So what is the Robots Exclusion Protocol?
The robots exclusion standard, also known as the robots exclusion protocol or simply robots.txt, is a standard used by websites to communicate with web crawlers and other web robots. The standard specifies how to inform the web robot about which areas of the website should not be processed or scanned.
Wikipedia
Crawler directives, indexing directives – what does this mean?
Crawler directives
Setting crawler directives (in robots.txt and our sitemaps) allow the website owner to determine which resources search engine crawlers are allowed, or not allowed to access on the site.
Sitemaps can be used to suggest things like the most important pages to be crawled, how frequently they should be crawled (although this is probably ignored) and the date they were last updated.
Search bots are simple things. They fetch the data for a search engine to index, and that’s pretty much it. Once a page has been crawled, any indexer directives we’ve set will be processed and hopefully, respected.
Indexer directives
1. In the head
Indexer directives are directives that are set on a per page basis and can be found in the head of your web pages.
For example:
<meta name="robots" content="noindex" />
2. In the http header
Indexer directives can also be set on a per file (.txt, .doc, .pdf and so on) basis in the http header using the X-Robots-Tag.
This lesser-known HTTP header addition method to add: “noarchive”, “noindex”, “nofollow”, and “nosnippet” at the page level, much like you would in the meta element.
Why lesser known? While it’s supported by Google and Bing (and therefore, Yahoo), the X-Robots-Tag likes to hide in your server header responses rather than in the head element of a web page.
A lot of SEOs just don’t look here:
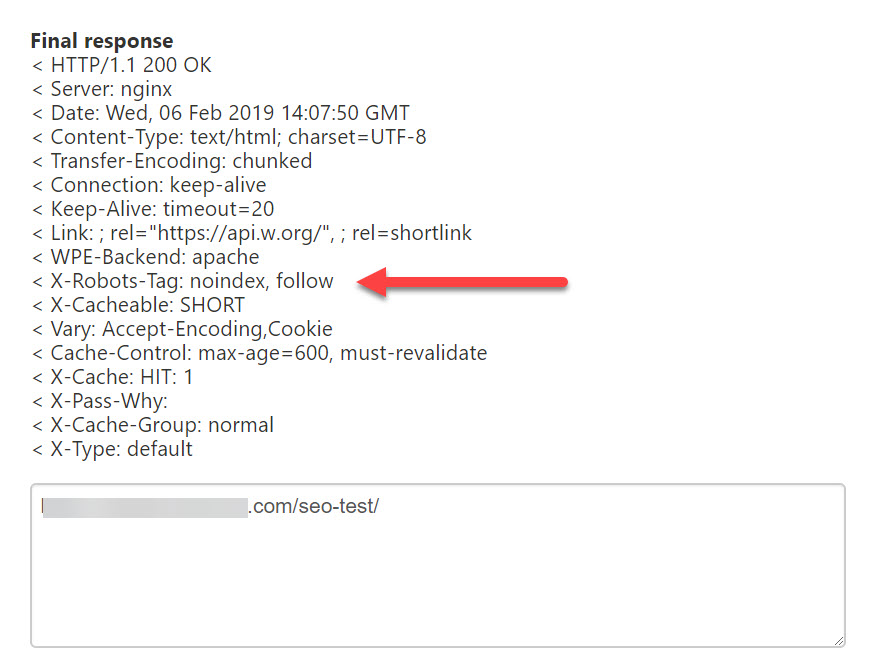
Setting an X-Robots-Tag in a WordPress page.
3. Inline
Finally, you could class the Microformat rel=”nofollow” as an inline indexer directive.
It implies that a search engine should not “follow” a link with the objective of not passing any authority to the link from your page. I’ve always thought of nofollow as a way of saying “I don’t editorially vouch for this link”.
Rel=”nofollow” was initially developed in 2005 to deal with the problem of comment spam on blogs but quickly became a tool to PageRank sculpt until that idea was debunked at SMX Advanced in 2009 (I was there!).
The rest of this guide looks at how to apply these different methods, with some (hopefully) useful real-world examples at the end.
Quick Navigation
- Using meta robots
- Using X-Robots-Tag
- Set crawl directives in robots.txt
- Test robots.txt
- Removing content via Google Search Console
- Real life examples QA
Setting page level indexing directives with meta robots
Each of these indexing directives will look extremely familiar to most SEOs. They’re found in the html source of a page, which we all work with on a daily basis!
The classic “noindex” directive sits in a meta element in the head of your web page. The “name” attribute is set to a generic “robots” declaration, or can be set to identify individual bots by their user-agent tokens, for example, “googlebot” or “bingbot”.
There are lots of interesting takeaways from looking through the list of working meta tags.
Even when reviewing an item of knowledge that should be pretty ancient in the SEO world, you can always learn something new. For example, setting name="robots" content="none" is the equivalent to setting a noindex, nofollow. Here are some examples.
Set a page to noindex:
<meta name="robots" content="noindex" />
Set a page to noindex,nofollow
<meta name="robots" content="noindex,nofollow" />
Or:
<meta name="robots" content="none" />
Set a page to noarchive (don’t provide a cached copy):
<meta name="robots" content="noarchive" />
Prevent a description from appearing below the page title on a search result page and don’t provide a cached copy of the page:
<meta name="robots" content="nosnippet" />
Don’t index the images on the *page:
<meta name="robots" content="noimageindex" />
*This won’t stop Googlebot and Googlebot-images indexing your images. It will only stop Google referencing the host page as the source for the image in image search. To keep an image out of the search results altogether, I would use the X-Robots-Tag (described below).
If you wanted to just discourage Googlebot from indexing your stuff, then change the user agent token to name=”googlebot”.
You can also insert multiple tags:
<meta name="googlebot" content="noindex" />
<meta name="googlebot-news" content="nosnippet" />
Or chain the tags:
<meta name="googlebot" content="noarchive,nosnippet" />
For see all of the user agent tokens from Google, see here.
Indexer directives that works (according to Google)
Here are all the directives that work according to Google:
| Valid indexing & serving directives | |
|---|---|
| all | There are no restrictions for indexing or serving. Note: this directive is the default value and has no effect if explicitly listed. |
| noindex | Do not show this page in search results and do not show a “Cached” link in search results. |
| nofollow | Do not follow the links on this page. |
| none | Equivalent to noindex, nofollow. |
| noarchive | Do not show a “Cached” link in search results. |
| nosnippet | Do not show a text snippet or video preview in the search results for this page. A static thumbnail (if available) will still be visible. |
| notranslate | Do not offer a translation of this page in search results. |
Whenever the official specification claims “undefined”, I’d strongly consider reworking that rule. Or, testing carefully!
Missing from Google’s documentation above, but not from this video by Matt Cutts is “unavailable_after”, a directive to set an expiry date on your content. The directive is accompanied by an RFC 850 formatted timestamp.
This removes an URL from Google’s search index a day after the given date/time.
For example:
<meta name="googlebot" content="unavailable_after: 23-Jul-2019 18:00:00 GMT" />
This could be set in the X-Robots-Tag, too. A word of caution, though if unavailable_after is set incorrectly, *and* it’s hidden away in your server headers, it could take an age to diagnose any potential problems.
Setting page and file level indexing directives with X-Robots
You can set indexer directives in the server header with the X-Robots-Tag. This HTTP header allows you to do what you’d normally do in a robots meta tag, just in an HTTP header.
While you’ll almost certainly need to work with a developer on a site with significant scale, a comfortable place to learn about and test setting the X-Robots-Tag is your htaccess file of a WordPress site running on an Apache server.
Let’s look at some examples, first, let’s set any file that ends in .doc or .pdf to noindex, noarchive and nosnippet:
<FilesMatch ".(doc|pdf)$">
Header set X-Robots-Tag "noindex, noarchive, nosnippet"
To do something similar to this in nginx, add these rules to nginx.conf.
If you wanted to noindex a rewritten page (a page that ends in “/” rather than a FilesMatch candidate) for example, "/seo-test/", try the following rule.
Place this before your WordPress directives are executed:
SetEnvIf Request_URI "^/seo-test/" NOINDEXFOLLOW
Header set X-Robots-Tag "noindex, follow" env=REDIRECT_NOINDEXFOLLOW
I highlighted the results of this test with Aaron’s Server Header checking tool earlier in the guide. It’s a brilliantly handy way of dealing with those occasional edge cases when you need to noindex at the server level. It’s also pretty cool.
Testing is important, so let’s cover that in some detail later on in the guide.
Setting crawler directives with robots.txt
Robots.txt files have been around since the dawn of time (pretty much). They’re incredibly simple things to get right, provided you acknowledge some important points.
Those are:
- Save the file as UTF
- The URL for the robots.txt file is – like other URLs – case-sensitive
- Casing absolutely matters in rule matching
- The longest rule can take precedent
- You can percent-encode characters for non ascii character compatibility which makes ideas like this possible (source)
- A robots.txt will be accessed on the hostname’s punycode equivalent if the domain uses non ascii characters
- Test everything
How is a robots.txt file structured?
Each group-member record consists of a user agent declaration and a crawler directive. The crawler directive declares a path that that directive applies to. The path can contain wildcards.
User-agent: [user agent token] (Name of the web robot)Directives: [path] (Rules for the robot(s) specified by the User-agent)
The file itself should be plain text encoded in UTF-8.
Setting User-agent:
Setting User-agent: is trivial, but somewhat important to get right! As everything in a robots.txt file is operated on a text matching basis, you need to be very specific when declaring a user agent. The crawler will find the group with the most specific user-agent name match and will ignore everything else.
In this example, Googlebot will ignore the first group of directives:
User-agent: *
Disallow: /
User-agent: googlebot
Allow: /
If you have a specific user agent you’d like to block or otherwise set some crawling rules for, here’s a list.
Setting the crawling directives
There’s a list of directives that are supported by most major search engines. If you’re trying to do something non-standard, always test your configuration.
- Disallow: (works for all major search engines)
- Allow: (works for all major search engines)
- Sitemap: (works for all major search engines)
- Crawl-delay: (supported by Bing, takes precedence over their Webmaster Tools settings)
- Host: (supported by Yandex, sets a preferred hostname for display in their search results)
- #: (a comment declaration)
The Disallow: and Allow: directives both work with wildcards, so let’s take a look at those next.
How to Use wildcards in robots.txt
Understanding wildcards is an important part of learning how to build robots.txt files.
With these simple expressions, you can build elegant rules that will improve your use of crawl budget and help to deal with duplicate content issues caused by features such as faceted navigation.
Wildcards: include “*” to match any sequence of characters, and patterns may end in “$” to indicate the end of a name.
For example:
Block access to every URL that contains a question mark “?”User-agent: *
Disallow: /*?
The $ character is used for “end of URL” matches. This example blocks GoogleBot crawling URLs that end with “.php”User-agent: Googlebot
Disallow: /*.php$
Stop any crawler from crawling search parameter pagesUser-agent: *
Disallow: /search?s=*
To remove all files of a specific file type, use:User-agent: Googlebot-Image
Disallow: /*.gif$
By specifying Googlebot-Image as the User-agent, the images will be excluded from Google Image Search.
It will also prevent cropping of the image for display within Mobile Image Search, as the image will be completely removed from Google’s Image index.User-agent: Googlebot-Image
Disallow: /images/*.jpg$
This example is taken from my Woocommerce site. Woocommerce creates lots of product attribute pages that are indexable by default. When you have literally hundreds of these things, it’s hard work getting them out of Google’s index (we’re going to come on to this example in a moment). Once they’d all been removed, I used a catch-all rule to block product attribute pages getting crawled.
This had the undesired effect of blocking a sitemap file that happened to contain the list of the one type of attribute pages I needed indexing, the brand pages. But the Allow: directive overrules the Disallow: directive on order of precedence:User-agent: *
Disallow: /wp-admin/
Disallow: /checkout/
Disallow: /cart/
Disallow: /pa_*
Allow: /pa_brand-sitemap.xml
Order of precedence
This last little bit of information could save you a lot of time while testing.
The most specific rule based on the length of the [path] entry will overrule the less specific (shorter) rule.
Order of precedence is good to know in case you come across the issue I’ve described above.
I’ve lifted Google’s own scenarios to explain this point in the table below:
| Sample situations | |
|---|---|
| https://example.com/page | Allow: /p Disallow: / Verdict: allow |
| https://example.com/folder/page | Allow: /folder Disallow: /folder Verdict: allow |
| https://example.com/page.htm | Allow: /page Disallow: /*.htm Verdict: undefined |
| https://example.com/ | Allow: /$ Disallow: / Verdict: allow |
| https://example.com/page.htm | Allow: /$ Disallow: / Verdict: disallow |
*When the official specification says “undefined”, I’d strongly urge you to consider trying a different rule. Or, test carefully!
Testing your robots.txt and other indexability issues
Aside from using the site: search operator in Google, there are lots of tools for testing your robots.txt file. My go-to is the (old version of) Search Console:
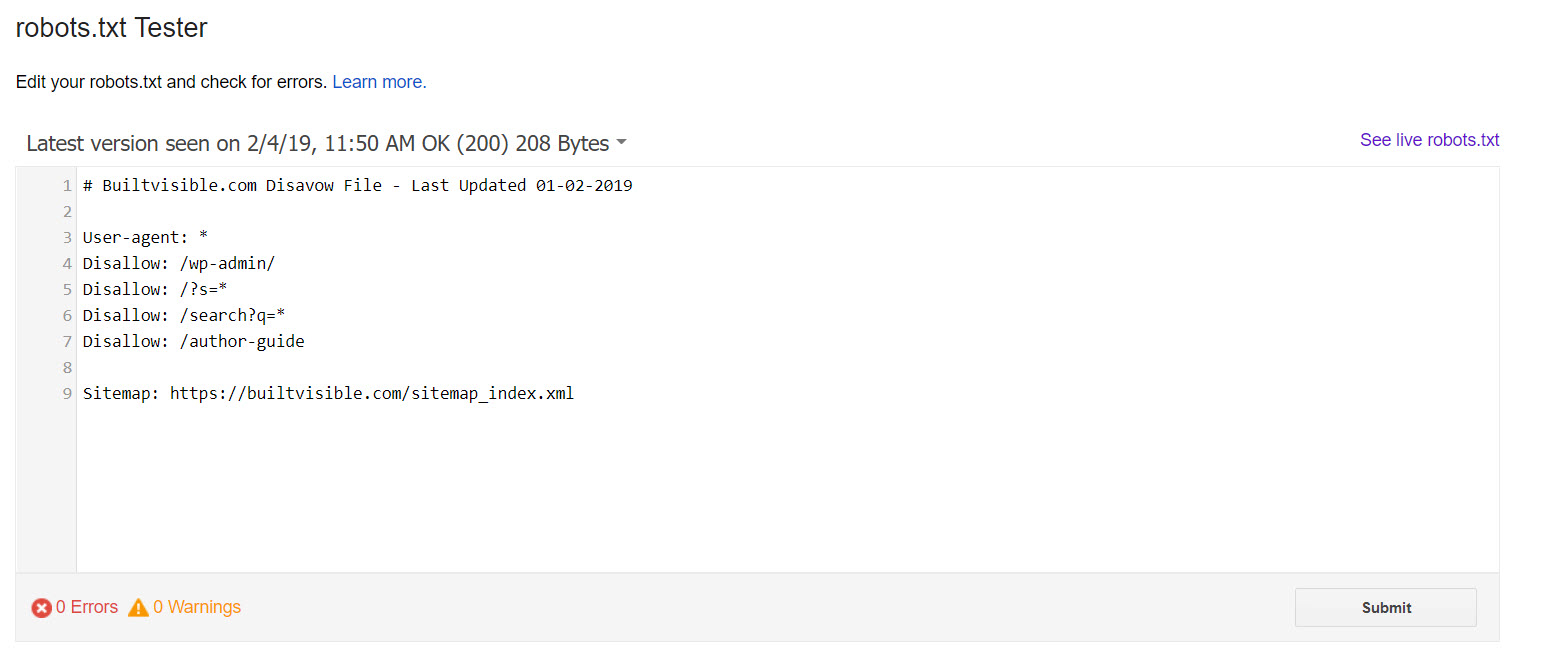
The (new) Search Console offers data on URLs blocked by robots.txt in the Coverage report:
And there are a variety of robot.txt testing tools available with a simple Google search. Screaming Frog is my weapon of choice for most indexability checks, though.
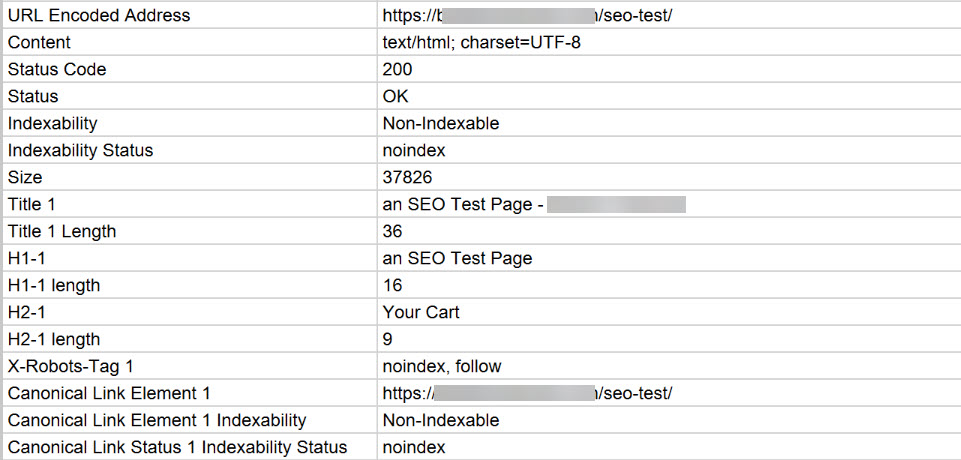
Screamingfrog showing every item that has been set to noindex in previous demonstrations throughout this article.
Remove a subfolder in Search Console
Using the url removal tool
You can use this feature in the (old) Search Console to remove a page or entire subfolder from appearing in Google Search results *permanently by removing the page from your site and letting it 404, password-protecting the page or by adding a NOINDEX tag to the page and allowing it to be crawled by Googlebot.
Here’s everything I’ve removed for a site recently.
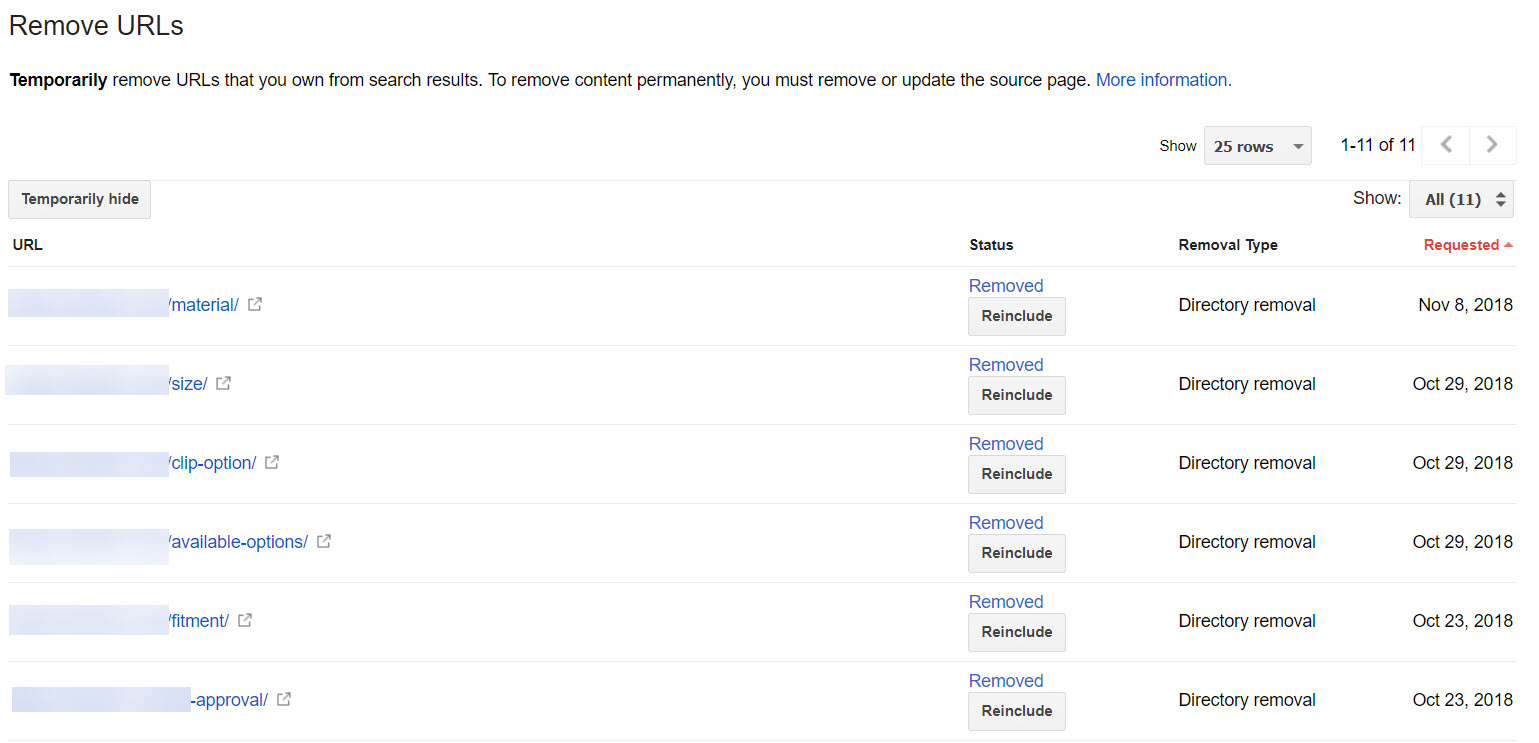
A long list of removed directories in (old) Search Console
I prefer to use this option to wipe out entire subfolders when I’m in a hurry. It isn’t my prefered solution, but it does work. Note the wording implying “temporary”. After following this process the URLs won’t return unless you remove the indexing directive from the page or subfolder.
The process is very simple. Select “Temporarily hide” and follow the prompts:
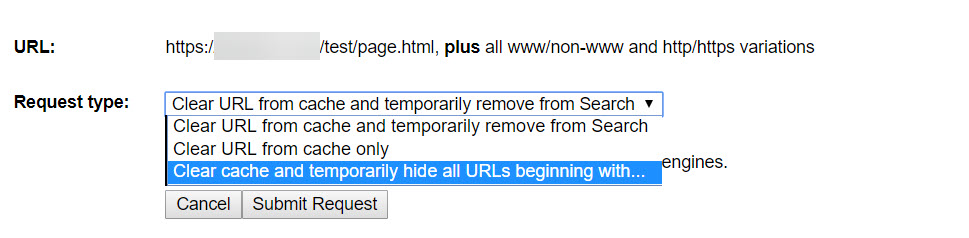
Updating a page and submitting via Fetch as Google or the Indexing API
Last week I wrote about using methods to get pages indexed faster, by either using the Fetch as Googlebot features in (old) Search Console, URL Inspection in (new) Search Console or via the Indexing API.
My preferred route to removing content in Google would always be a. set all the undesirable pages to noindex using whatever means at my disposal and b. getting those pages visited by Googlebot asap. Then, when I’m confident they’ve dropped out of the index, update my robots.txt rules to prevent them being crawled again.
If you actually don’t need the pages then create a rule to respond with a 410 server header response or perhaps just a 404. You could redirect them out, too, although that might trip some soft 404 warnings in Search Console.
If we’re talking dealing with URL parameters, you need to remember that they probably have rel=”canonical” URLs set, and by noindexing these pages you’ll prevent Google from honouring the canonical instruction. Don’t do that.
You could have a play around with the URL Parameters feature in Search Console too. I almost never interfere with google’s “Let Googlebot Decide” setting, though.
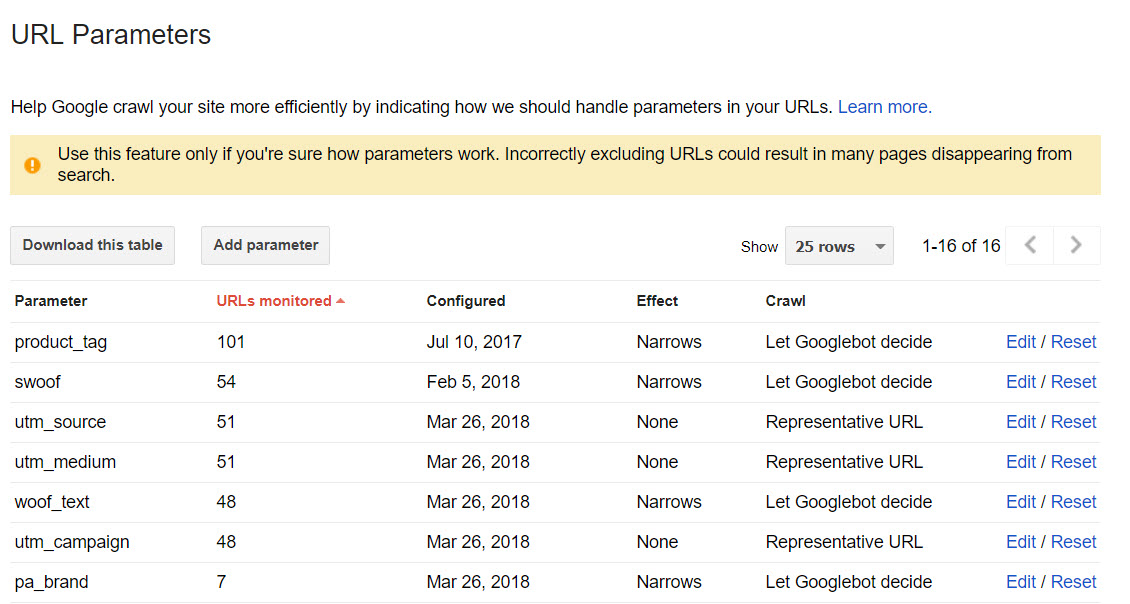
This brings us nicely to the real world scenarios.
Real life scenarios
Once you’ve learned all the theory, it’s easier to put things into a real-world context. Here are brief answers to the types of questions I see on a reasonably regular basis.
How do I deal with query parameters in faceted navigation?
Faceted navigation causes a problem because of the huge potential for duplicate content to be indexed, which wastes crawl budget. The usual solution in this situation is to use a rel="canonical" to hint to Google that the faceted navigational pages with query string parameters are in fact duplicates of the canonical. If you’re using canonical, don’t noindex the duplicate pages as the canonical instruction will be ignored. Maria outlined 4 different solutions to this problem in her excellent post on dealing with faceted navigation. Nick LeRoy also looks at the impact on the canonical that using a noindex directive can here in this excellent post.
How do I deal with noindex in paginated architecture, say on a retail category page with many products?
Google can identify paginated sequences, crawl these pages and index the content. As the product listings on these pages will be unique, we do not want to set them to noindex (a noindex would imply a nofollow over time when there are important blog posts or product pages to follow!). We self reference the visible url in rel="canonical", essentially each page within the paginated series should self reference, so /category/2/ has a canonical pointing to /category/2/.
How do I remove all indexed csvs in a subfolder?
Set a htaccess (Apache) or nginx.conf (nginx) rule to set all *.csv files to noindex in the X-Robots-Tag, or if it’s urgent, block the folder in robots.txt and use the Google URL Removal tool in (old) Search Console. If it’s personally identifiable information and therefore an emergency, I’d remove the files from the server altogether or password protect everything asap!
Block and remove the contents of a subfolder?
Similar to the answer above, block the folder in robots.txt and use the Google URL Removal tool in (old) Search Console. A htaccess rule to add noindex via the X-Robots-Tag, or password protect the folder.
What if the page uses rel=”canonical” but it’s a duplicate
Don’t use noindex.
How do I deal with an indexed login page that hand hundreds of thousands of session-based query parameters?
Use noindex via X-Robots-Tag and wait for the pages to drop out of the index. Then, block the offending session parameters with a set of robots.txt wildcard rules.
Resources and Further Reading
There’s a huge world of resources and information on this topic. This article, and my knowledge of the subject would not be complete without a nod to these resources:
- https://sebastians-pamphlets.com/
- https://microformats.org/wiki/rel-nofollow
- https://johnmu.com/highlight-nofollow/
- https://developers.google.com/search/reference/robots_meta_tag
- https://perishablepress.com/list-all-user-agents-top-search-engines/
- https://www.user-agents.org/
- https://stackoverflow.com/questions/43828216/x-robots-tag-noindex-specific-page
- https://support.google.com/webmasters/answer/79812?hl=en
- https://developers.google.com/search/reference/robots_txt
- https://www.gsqi.com/marketing-blog/how-to-check-x-robots-tag/
- https://www.askapache.com/htaccess/
- https://www.askapache.com/htaccess/using-filesmatch-and-files-in-htaccess/
- https://www.deepcrawl.com/knowledge/technical-seo-library/robots-txt/
- https://yoast.com/pagination-seo-best-practices/
- https://twitter.com/JohnMu/status/1083093012266340362?s=19

Gurbir
Hi Richard, great article.
You mention that we shouldn’t be using noindex on query parameter pages in the faceted navigation. However, I have seen these pages get indexed even after proper canonicalization + crawling blocked in both robots.txt & URL parameters in GSC. It is like Google does not respect robots.txt directives unless it wants to.
I understand the point about not using noindex on canonicalized pages. What solutions do you recommend to prevent indexing of query parameter pages (even after proper canonicals and robots.txt directives) ?
Thanks :)
Richard Baxter
Hi there, if you’re blocking an indexed URL with robots.txt then adding a canonical won’t make any difference after the fact. canonicalise and allow access in robots.txt. As for the URL removal tool not working in Search Console – 100% of my tests confirm that tool works. It’s extremely effective. Parameter handling is a different matter – consider those settings a hint, rather than an absolute rule. Finally, I have noticed that Google takes a long time to process this stuff – noindex, for example, can take weeks, even months. Use the URL inspection tool and submit to index to get your URLs crawled faster. This article covers fast indexing method for SEOs.
Jack
Great article Richard. I do prefer placing robots directives in the head section. X-Robots headers are not so easy to spot and I always recommend using meta robots.