How to tidy up all the redirects in your htaccess file
Managing site redirects is an important SEO task and one that can bite you if it’s put off for too long. Especially if there’s a website redevelopment project on the horizon or some sort of major site change.
This post documents the process I used to deal with the legacy .htaccess file in use on our website, builtvisible.com.
Our .htaccess file in Yoast’s handy editor.
Years of migrations, legacy redirects and a bit of neglect
We’re busy people and naturally, aspects of our own websites tend to come lowest in the priority list.
The problem with older sites is that there’s always a history of migrations, legacy redirects, out of date blog posts and expired article removals (if the site in question is a WordPress site). That history accumulates a lot of stuff in the htaccess file.
From several domain migrations (causing a probable decay of equity from legacy inbound links, a successful re-brand, a penalty and subsequent recovery, even annoying comment spam tripping safe search filters, switches to HTTPS, back to HTTP and back to HTTPS again, this website has seen a decade of change.
Whatever server is running your software, they’ll always be a configuration file dealing with URL redirection.
For Apache, it’s .htaccess.
These are the types of problems I encountered while streamlining our htaccess file:
- Old redirects pointing to a URL now redirected causing redirect chains (an issue I’ve always advocated for fixing in a Quick Wins Audit) and are considered to be soft 404s by Google
- Inconsistencies such as a URL redirect to a new asset, but its non-trailing slash equivalent version redirects to home
- Inconsistencies with redirection rule handling
How to audit and update your htaccess file
We’re going to start by collecting as much page level error data as possible.
While we still can, we’re going to download some crawl error data via the Search Console API using my weapon of choice, SEO Tools for Excel.
You could also collect error data from Googlebot requests in your server log entries (which in my opinion is the most complete approach provided you’re using data collected over a reasonable period).
The aHrefs “pages” API will also give you a list of broken pages (as well as pages with links which can come in really handy later on).
With a somewhat large list, it’s important to remember to de-duplicate at strategically correct moments.
Let’s have a look at this phase of the process:
Download search console errors
SEO Tools for Excel has an API connector for this, and while it’s still possible (pre-March 2019) I say grab the data. After that, Google is taking away this precious feature. I think it’s a shame.
Connect to Google’s auth via SEO Tools for Excel using SEO > Google Search Console > URL Crawl Error Counts. Once you’ve authorised the platform to access your Google account, you can access the data. This is the summary:
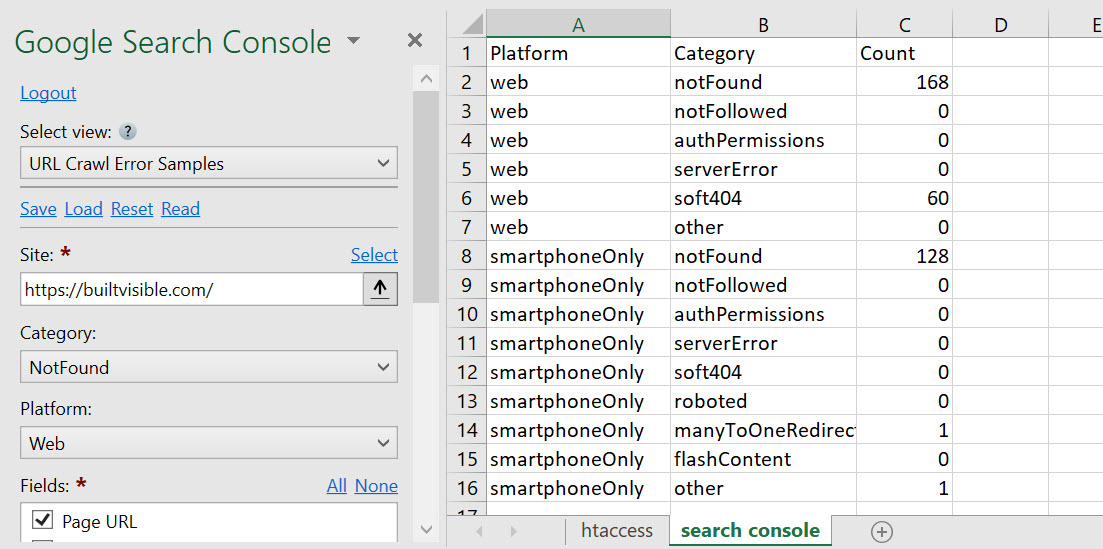
And for the full error download, change the drop down on the left to URL Crawl Error Samples.
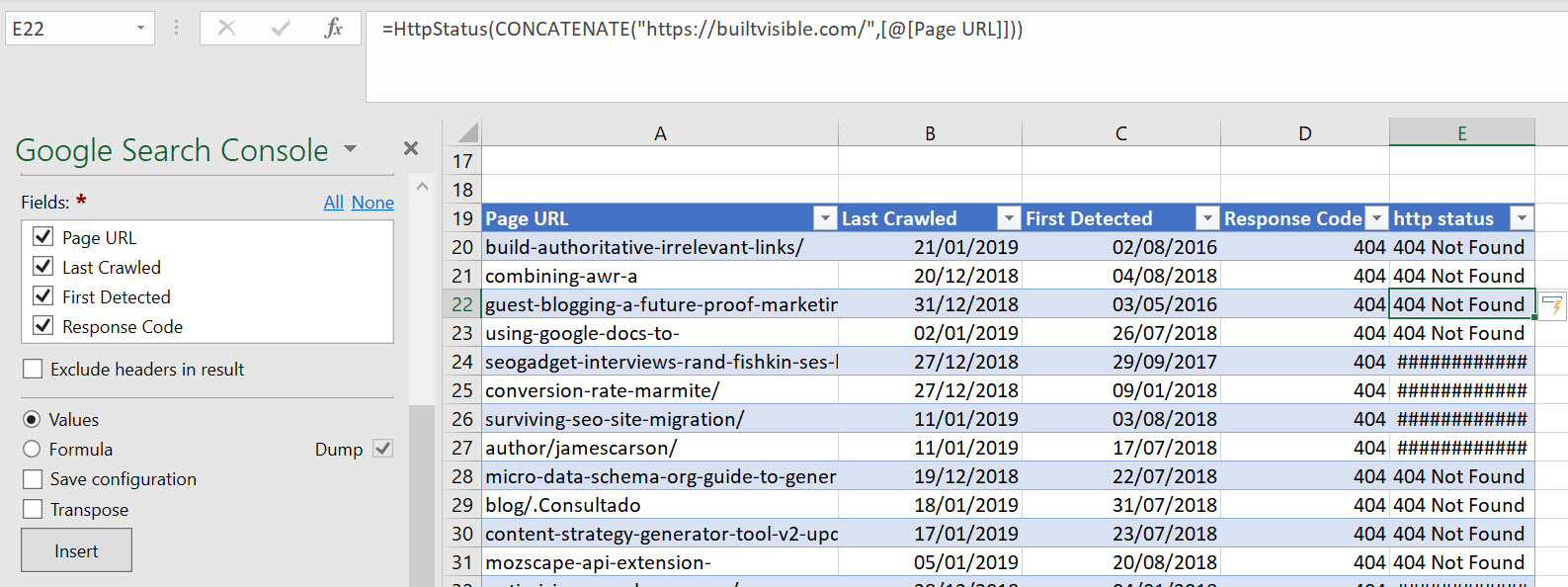
In the example above, I’m concatenating the the hostname into a =httpstatus() query and checking the live http status of the URL. You’re going to want to copy anything that’s a 301 or 404 (all 4xx and 5xx errors are interesting too, so grab everything that clearly needs a redirect setting up).
The reason why you’ll need the 301s too – if we’re completely rebuilding the htaccess file, you’re going to need to retain those 301s. Obviously they’re already in the existing file but it’s good to have them to hand if only to de-duplicate them out later on. We’re trying to be as complete as possible.
aHrefs “best pages by incoming links” report
Have you see this magic report from aHrefs?
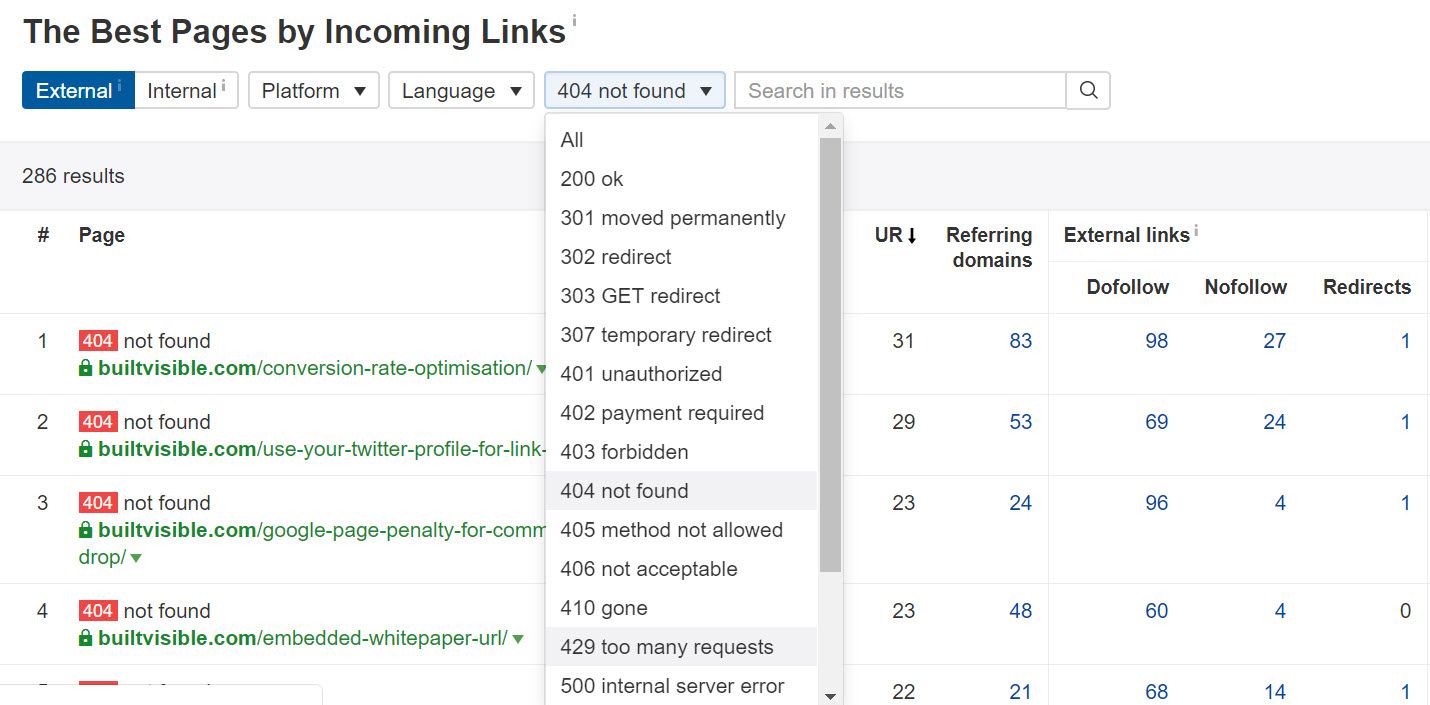
Categorise top pages on your domain by pretty much any https status code there is. Magic.
You can download the data or grab it via the API in SEO Tools for Excel.
Before we go onto the next step, combine all of the URLs from all of your data sources, de-duplicate and get a fresh status code for each. Remove anything that isn’t a 3xx, 4xx or 5xx server response (you don’t need the 200s, basically).
Bring in the old htaccess file
Until this point we haven’t talked about the htaccess file itself. Our first job will be to arrange the data in a useful way in Excel. Then, we’ll follow a process to begin to unpick the old structure and add any new error URLs we need to tackle.
Then we’ll look at strategies for redirect-to destinations and methods to test before you deploy back to your staging, and eventually, live environment.
Raw htaccess into Excel
First things first. Take all the redirects already in your existing htaccess file and paste them into a column into Excel.
Using Find and Replace, replace “Redirect 301” with whatever your domain name is, in our case, “https://builtvisible.com”.
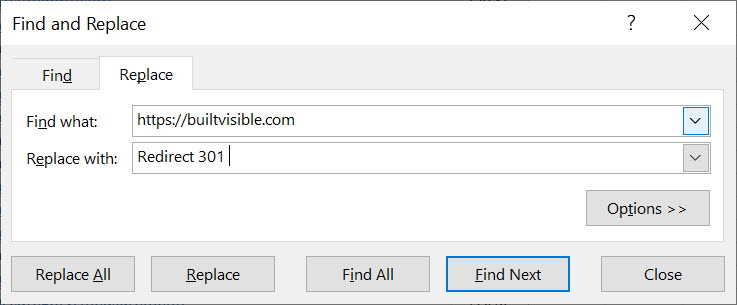
Then, using Text to Columns, highlight the entire column and use “Space” as the delimiter to break up the text into usable Excel columns:
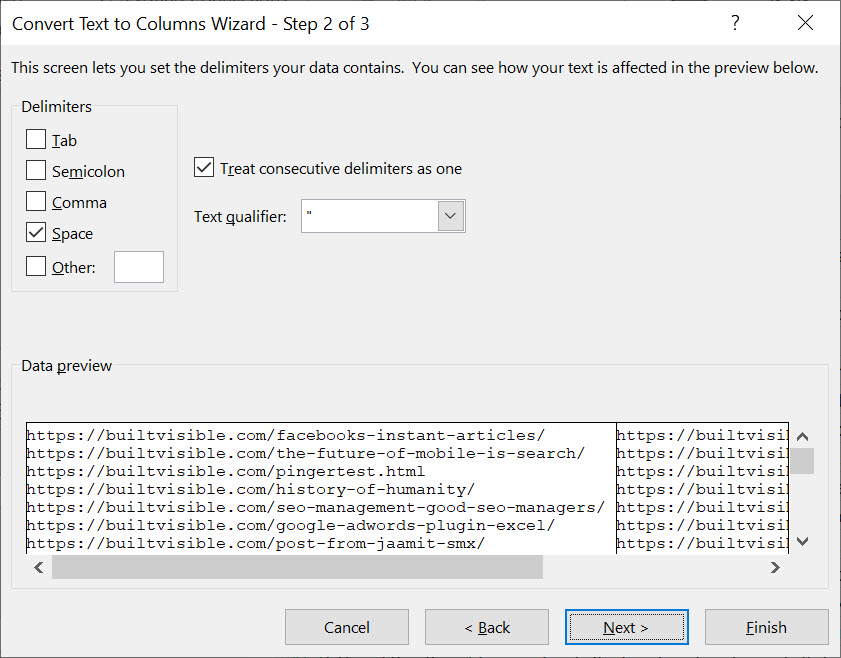
Next, paste in all of the errors and 301s you found in the Search Console and aHrefs data, and carefully remove duplicate values on the left hand column.
You should end up with a table that looks like this:
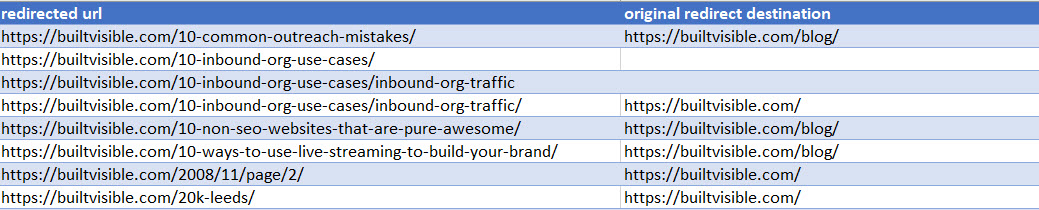
Don’t worry about the gaps, that’s to be expected if you’d found 404 errors in other data sets.
Next, we need to start addressing the issue of redirect hops.
To do this, you have two options. Either paste your “Redirect from” URL list into Screaming Frog, crawl and export a redirect chain report:
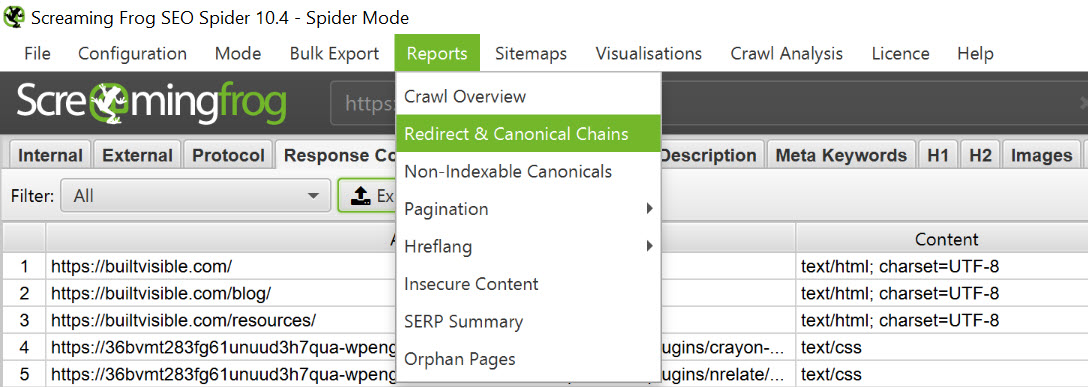
Or use SEO Tools for Excel’s =unshortURL() function, which will traverse the redirect for you and come up with the final destination:

The goal, find the last redirected-to URL and make that your “final destination”.
Dealing with the blanks – defining a redirect strategy
Now we’re ready to make some decisions! This legacy htaccess file, with its many redirects is a naturally tangled web to unpick. A big potential problem, in my opinion, is the habit of just redirecting a URL to something that looks like it’s similar enough to blindly redirect.
Take for example, a 2008 article about building links with infographics. That’s not something we do anymore and the URL has long since been removed. Where, therefore, do we redirect it?
If you’ve got a 100% relevant redirect with some or all of the original meaning of the page intact go ahead and redirect to that destination. Don’t blindly redirect irrelevant pages to key areas of your site, though!
I’ve seen otherwise healthy pages drop out of the rankings with careless redirects set in place.
For the few of you still reading at this point therefore, this opinion might trigger some debate. Go ahead and test whatever feels right for you. For me, I’m more interested in building a manageable set of rules so that we don’t end up in a mess in another 10 years.
An example WordPress redirect strategy
- All tag pages redirected to new relevant category (this site doesn’t use indexable tag pages but there are 100s of legacy ones)
- Old category names redirected to the new, correct category names
- Old authors redirected to blog home
- Removed posts redirected to relevant content or relevant parent category (they still drive traffic from referrers)
- Old job postings to /careers/
Unfortunately, “filling in the blanks” takes time. For the 2,000 redirected URLs in this htaccess file, I took almost an entire day to carefully and individually review the situation. When it’s done, you need to do some testing before setting it live.
Testing your new htaccess configuration
Testing your htaccess redirects comprises of:
a. checking your redirect destinations all resolve with a 200 response (why would you redirect to an error or another redirect?) and
b. checking your redirect origins are all either 3xx, 4xx, 5xx or responses (why would you redirect an existing 200? You might have a good reason for it though!)
The drive by check
The most important thing I always do is sort your origin / redirect from URLs in alphabetical order. Doing this will almost certainly highlight some inconsistency in your decisions.
For example, this is a very common mistake in my experience!
/inbound-org-traffic redirects to: https://builtvisible.com/page/inbound-org-traffic/ redirects to: https://builtvisible.com/page2
Check all redirect to destinations are 200
You need to make sure that everything you’re redirecting to is a 200. That’s extremely easy to test for with Screaming Frog, just copy the list and paste in list mode. Weed out any anomalies.
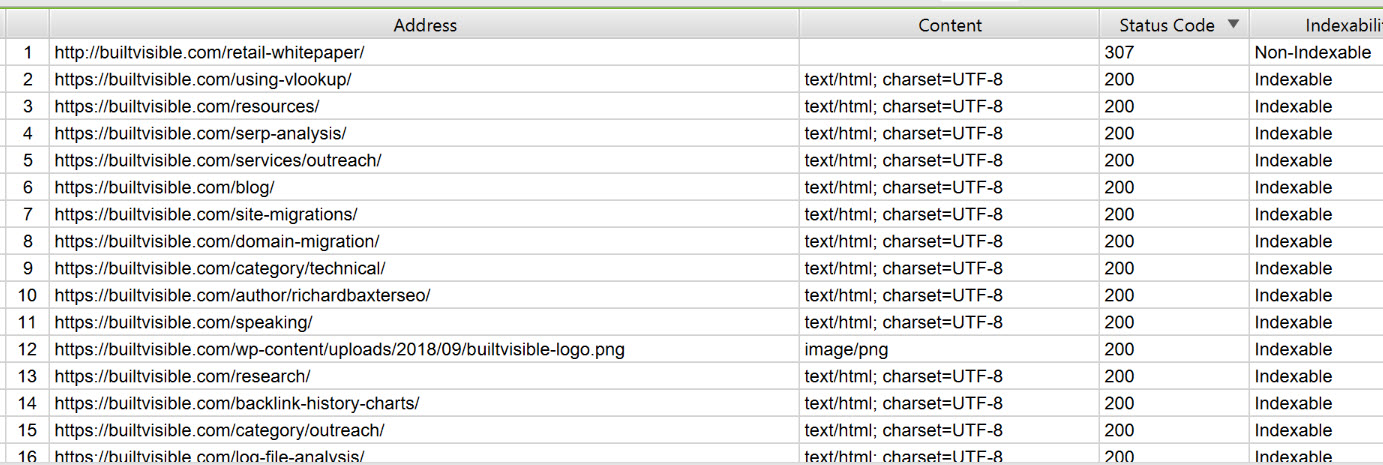
Check all redirect destinations respond with a 200.
Check all redirect from locations are already 301 or 404
Similarly, check all of the locations you’re redirecting from respond with either:
– a 301 / 302 (they’re already featured in the legacy htaccess file)
– a 4xx / 5xx error (you’ve found some new errors you’re mopping up as part of this process)
And most definitely look out for anything that responds with a 200. It’s so easy to accidentally leave a typo in your origin list. If you have, lets say, the homepage URL in this list you’ll deny yourself access to your own website by accident!
Time to create a new htaccess file
As I’m working with a WordPress website, I’ll pay special attention to preserving the WordPress htaccess rules!
With that important point made, all I need to do is reverse the find and replace process I began earlier. Use find and replace in Excel to remove your domain name from the redirect from column, and then I’m ready to copy / paste all of it to Notepad. Excel pastes to Notepad with tab separators, which are super easy to find and replace to space characters.
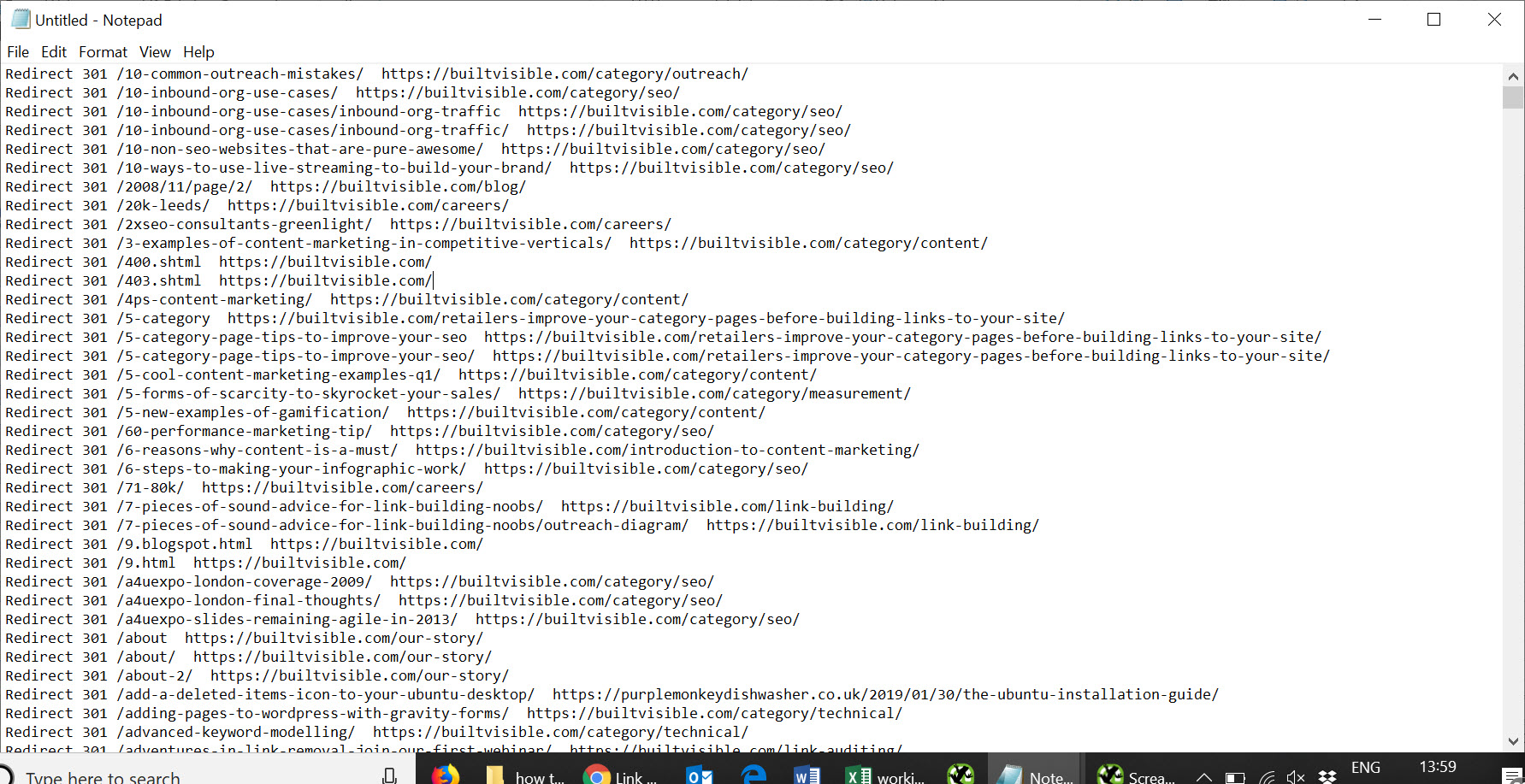
As soon as everything is tidied up, you’re ready to update your htaccess file!

Fernando
Verify broken links is an important step in on-site SEO, I already use YoastSEO to redirect deleted posts/pages and works well to me.
Rajiv Singha
Hi Richard,
Wonderful guide and just in time! I have been hoping to stress on maintaining a clean htaccess to our server team and your guide will surely come in handy.
I’d like to add a few points to your document:
1. “Redirect 301” may not be the only instruction used. Redirect permanent, RedirectMatch 301 are some possible variations that can be often found in htaccess file; unless the institution follows a strict rule to always use “Redirect 301” only while adding redirects.
2. Does SEO for Excel provide crawl data more than the first 1000 rows? If not, there’s another way to get the same 1000 rows via Search Console API explorer. It’s a free alternative so users without the Paid SEO for Excel can use it too. I wrote a post on the process titled “How to download 404 errors from Google Search Console with Linking pages”. If you like I can share the link with you.
Regards
Rajiv
Richard Baxter
Nice comment Rajiv. SEO tools for Excel is surprisingly powerful. It’s good for 1000’s of rows. Any higher though and I’d suggest Screamingfrog.