Fast indexing options in 2019
In 2019, these are the simplest and most effective ways to get a page updated, re-indexed or submitted to Google. This is (in my opinion) arranged in order of indexing speed:
- Manually submit a page via Search Console (fastest)
- Use the (new) Search Console Indexing API
- Create a new sitemap or resubmit old sitemap
- Temporarily increase your site crawl rate settings
- Ping sitemap updates
“Ping” updated sitemaps or page URLs
These options have been around for a long time. You can “ping” Google or Bing via these end points:
https://www.google.com/webmasters/sitemaps/ping?sitemap=URLOFSITEMAP
https://www.bing.com/webmaster/ping.aspx?siteMap=URLOFSITEMAPIt’s debatable whether this is a good use of your time as I suspect these are the least effective options in the list. Let’s just move on and talk about the things I actually do myself.
Create a new sitemap and submit via Search Console
I’ve very recently completely rebuilt the htaccess file in use by Builtvisible, as it was full of years old redirects, chains and unnecessary hops.
After building a new redirection list I wanted to get all of the URLs recrawled as quickly as possible, so I used Screamingfrog’s XML sitemap generator to generate me a new sitemap:
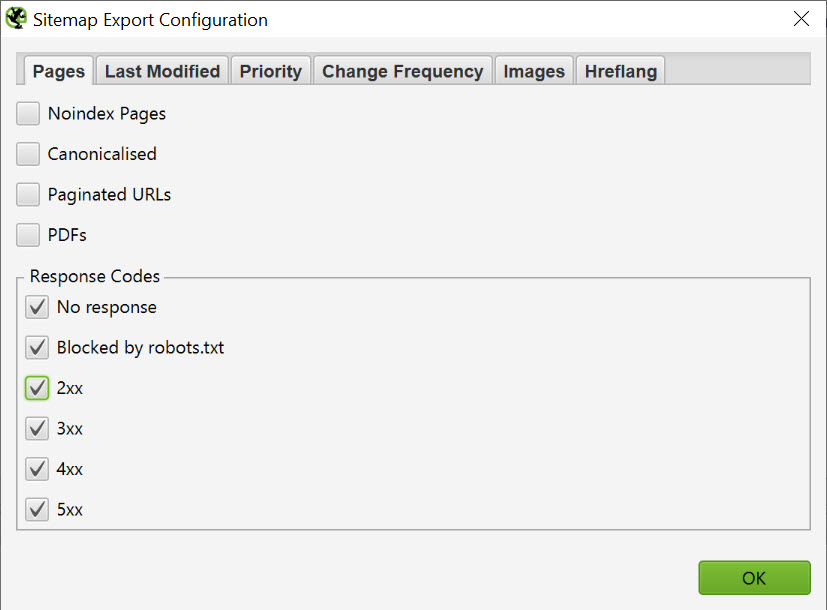
I then submitted that file to Search Console:
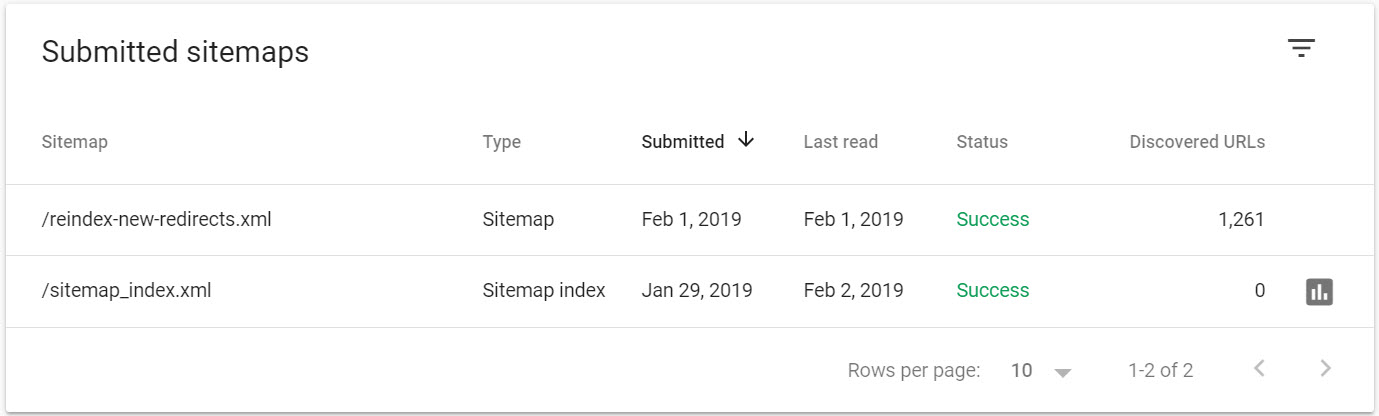
This is a set-it-and-forget-it solution. Given it’s a batch of decades old redirects, I can probably wait a few weeks for these to be fully recrawled.
Re-submit your sitemaps or RSS feeds
I am of the opinion that sitemap re-submission can trigger a flurry of crawl activity. I always find myself resubmitting existing sitemaps after a large site change. Especially when I’ve released a large number of new product pages on a retail site, for example.
I also think there are interesting sitemap alternatives or further options you can pursue:
- Submit your RSS feed into Search Console’s sitemaps feature.
- Break up your sitemap into smaller files.
- If you use a sitemap index file, submit the individual files anyway.

Both the old and new Search Consoles accept RSS feeds, however the new Search Console does not display them after submission. Probably a bug.
Google Search Console
There are a few handy ways to encourage indexing with Google’s Search Console, provided that the site belongs to you and it’s verified.
Using Fetch as Googlebot in Search Console
This feature is stunningly fast. Not only to trigger a visit to the page you’ve submitted, but also to update the version of the page in Google’s index.
The process begins by collecting data from Google’s index:
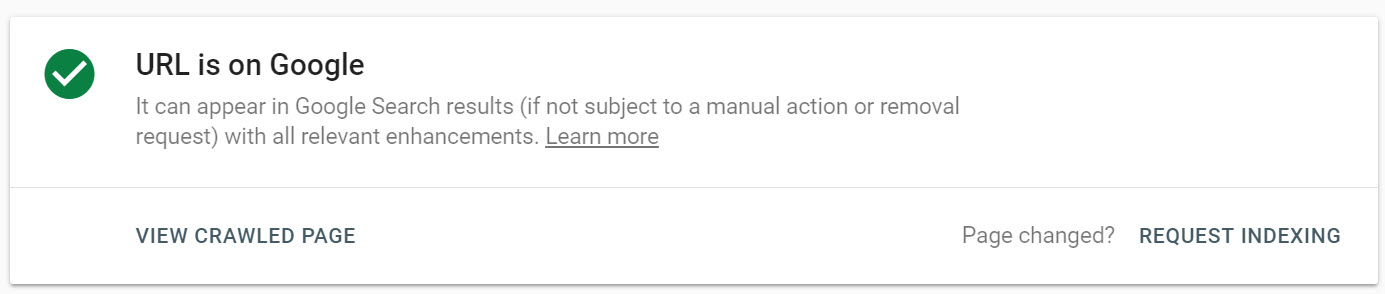
Then, you can request indexing using the link provided, which triggers this dialogue:
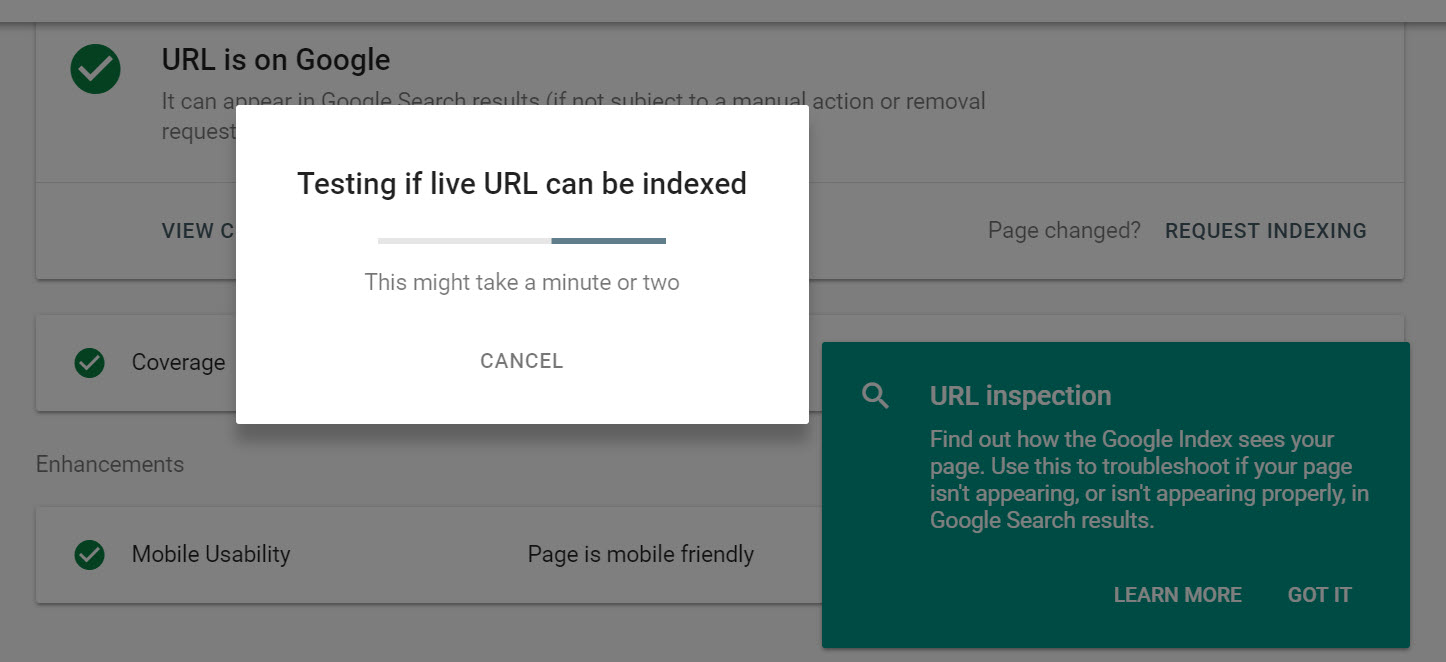
I compared the process of URL submission in the old Search Console to the new version, and saw some differences in the requests made by each. The common takeaway though, is the immediacy of the process. You get a visit from Googlebot instantly.
Comparing Logs: New Search Console vs Old Search Console
New Search Console
Submitting the live URL creates an immediate sequence of log entries beginning with a GET request to the page, followed by a GET request for the robots.txt file. Then a sequence of GET requests for CSS and JS files are made, followed by all of the image files.
This is the first log entry in that sequence:domain.com 66.249.66.159 [02/Feb/2019:13:36:36 +0000] GET "/" HTTP/1.0 200 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +https://www.google.com/bot.html)" "-" 66.249.66.159 1 1 "/" "index" php "-" 0 7.89 17659 18041 0.000 -
Observations
- robots.txt Request made after first page request
- CSS and JS requests are made in approximate order of page source
- Proceeds to GET request to all images
- This is a WooCommerce site, and Googlebot makes a POST to “/?wc-ajax=get_refreshed_fragments”
Finally, the Submit to index request triggers a further visit, but only to the page (no images, js or css requested).
Old Search Console
The original fetch as Googlebot feature seemed only make a GET request to the page. Then a subsequent request for the robots.txt file.
This is the first log entry in that sequence:domain.com 66.249.66.159 [02/Feb/2019:13:41:50 +0000] GET "/" HTTP/1.0 200 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +https://www.google.com/bot.html)" "-" 66.249.66.159 1 1 "/" "index" php "-" 0 7.89 17659 18041 0.000 -
Observations
- Old Fetch as Googlebot downloads robots.txt first
- Then makes GET request to homepage
- No further resources appear to be requested
So the new Search Console and old Search Console behave somewhat differently, although they’re making requests from the same IP address. Regardless of which method you choose, the manual submit option remains the fastest and most effective route to updating a page in Google’s index.
Use the (new) Google Indexing API
About two days ago, I dropped my friend Victor a line from SEO Tools for Excel. I mentioned how it would be a good idea to provide support for the new Google Search Console Indexing API in his platform.
He agreed and built a new connector for the service remarkably quickly.
Here it is:
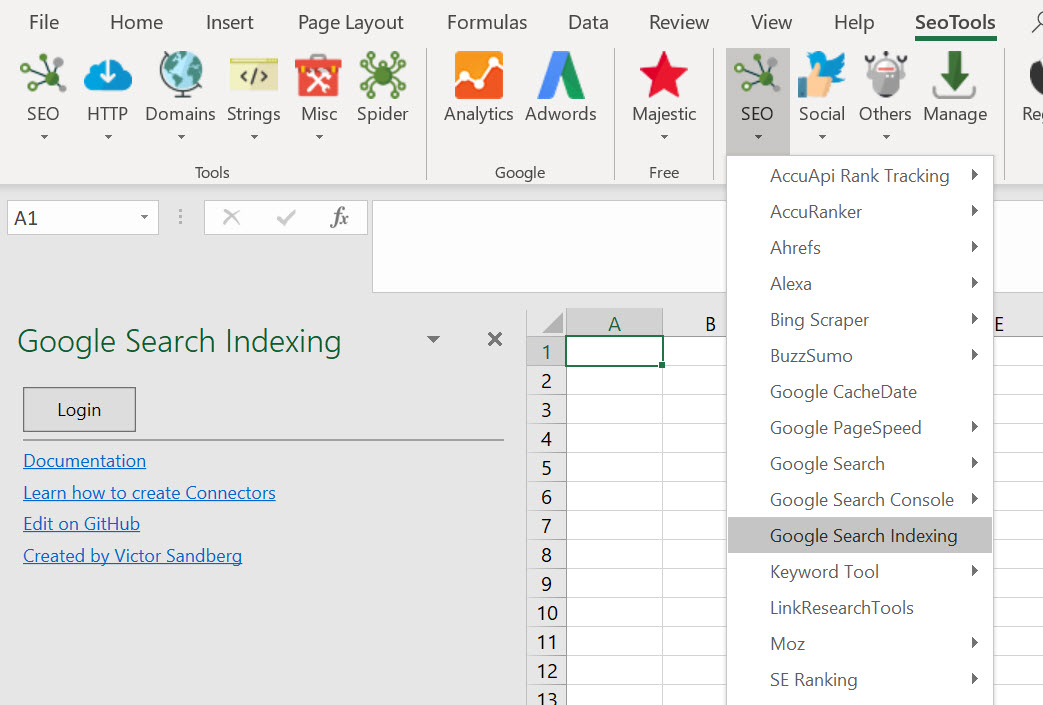
The main takeaway from learning how to use this service is that there’s some mild complexity in getting set up (notes below) but that the request behavior looks exactly the same as Fetch as Googlebot. There’s a slight delay between making the request via the API and getting the visit (approximately 30s to 1 minute). But, by 2010’s standards, this is magical.
How to use the Google Indexing API to submit pages
Assuming you have SEO Tools for Excel, and a Google account, login to your Google Account in the usual way via the tool.
You’re going to need to enable the Indexing API via Google’s API console. You can follow the instructions here.
Head to the API Console to enable the indexing API:
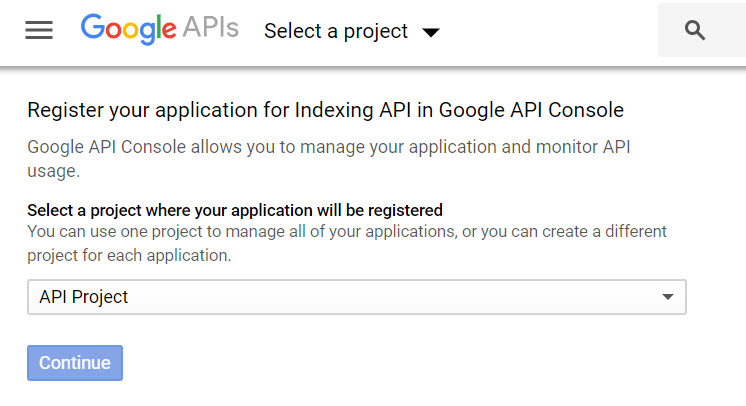
Select the type of credentials you need (Indexing API, Other UI, Application Data).
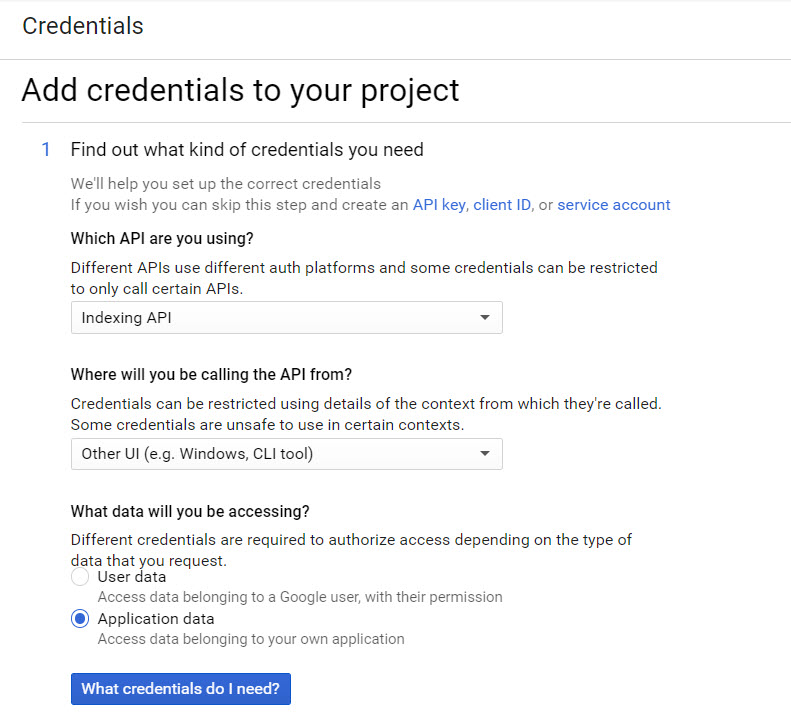
From “Credentials” go to “Manage Service Accounts”
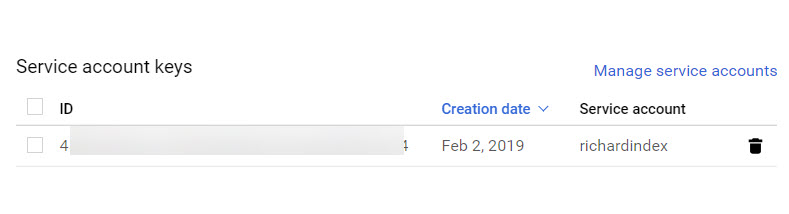
Highlight the account name here and copy it. You’ll need this to allow access for any Search Console account that doesn’t currently allow access to the Google Account name you’ve signed up to the API service with.
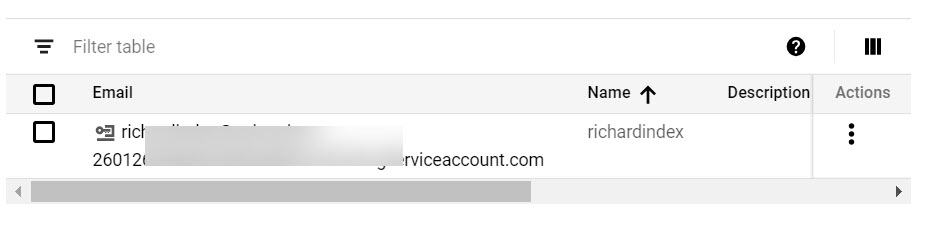
This is important. If you activate the indexing API using the Google account already associated with your Search Console account, you just need to add the domain under domain verification in the API credentials section like this:
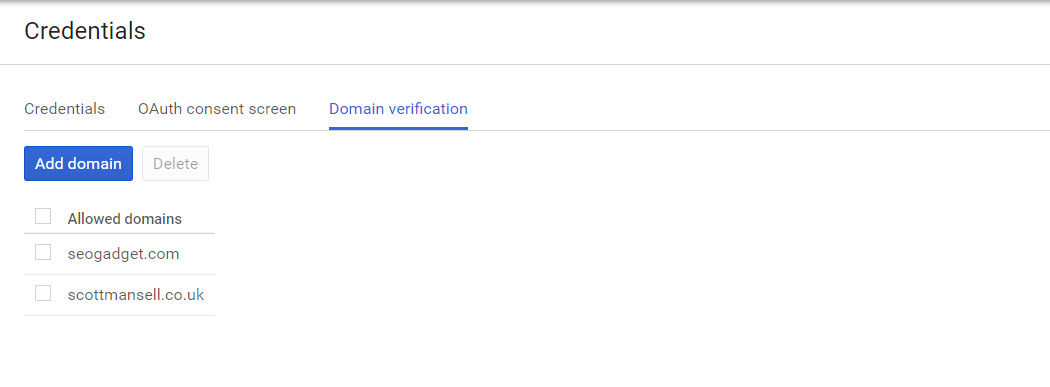
If you activate the API in a different Google Account to your Search Console account, you have to create a service account key, and add that as a user to Search Console before adding the domain under the domain verification in the API console:
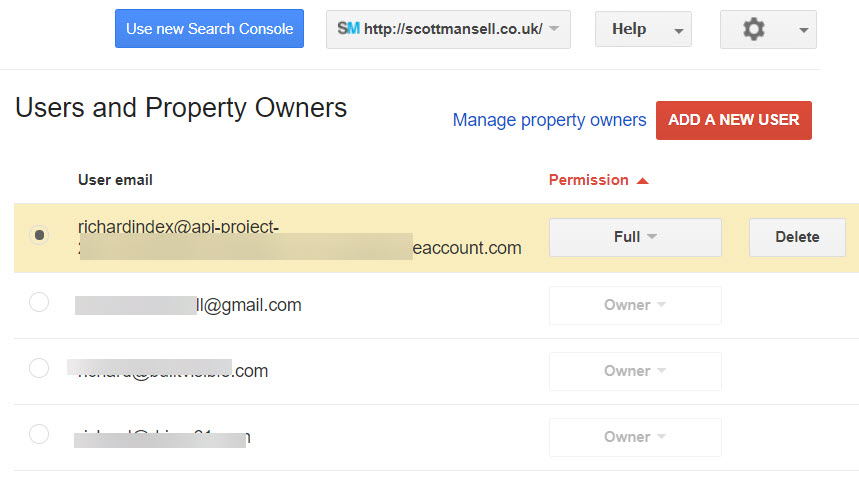
Once you’re through this stage, you’re ready to use SEO Tools for Excel to do some submitting!
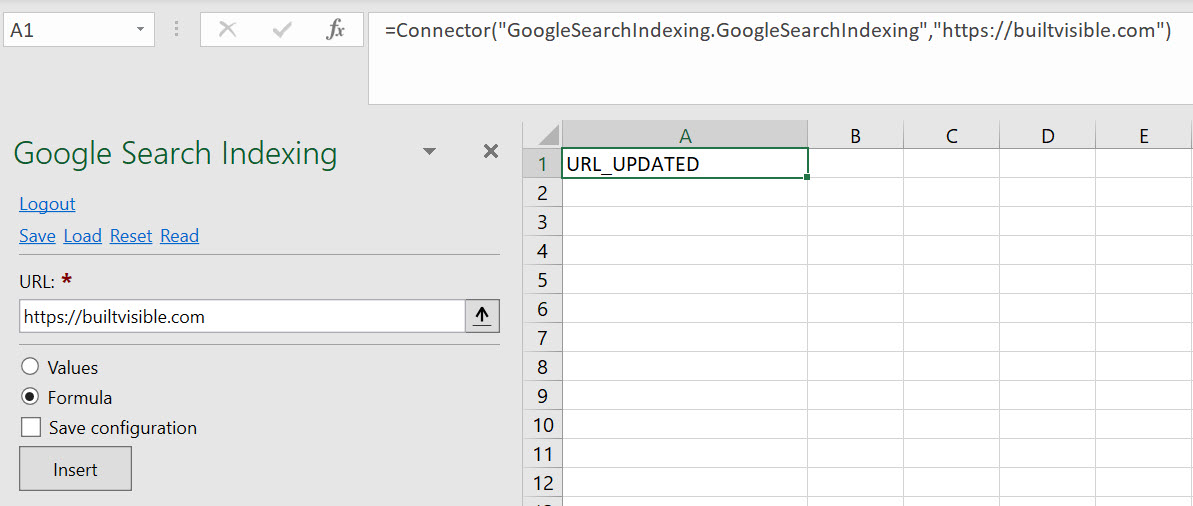
Here’s the (very simple) formula:=Connector("GoogleSearchIndexing.GoogleSearchIndexing","[your domain here]")
I looked at what happens in the logs when the URL is submitted, and it’s very similar to the Indexing request made in Search Console:
Created “test” URL that would respond with 404domain.com 66.249.66.130 [02/Feb/2019:14:08:03 +0000] GET "/test/" HTTP/1.0 404 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +https://www.google.com/bot.html)" "-" 66.249.66.130 1 1 "/" "index" php "" 0 7.08 8663 9078 1.111 1.112
Created indexable test pagedriver61.com 66.249.66.128 [02/Feb/2019:14:13:43 +0000] GET "/keetsington/" HTTP/1.0 200 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +https://www.google.com/bot.html)" "-" 66.249.66.128 1 1 "/" "index" php "" 0 7.14 8987 9379 0.563 0.564
As I mentioned earlier, API calls seem to delay by some time (30s to 1m) and only requests the page rather than all of the related resources. This is still potentially acceptable as the API will accept batch requests. Rather than submitting one page at a time, you could submit batches and expect them all to be visited in that time frame.
I’m with David, in that I’m hopeful this is a lasting solution. In Excel, for example, you could re-index and entire list of URLs in a single request. That is an immensely powerful option!
Temporarily increase your crawl rate in Search Console
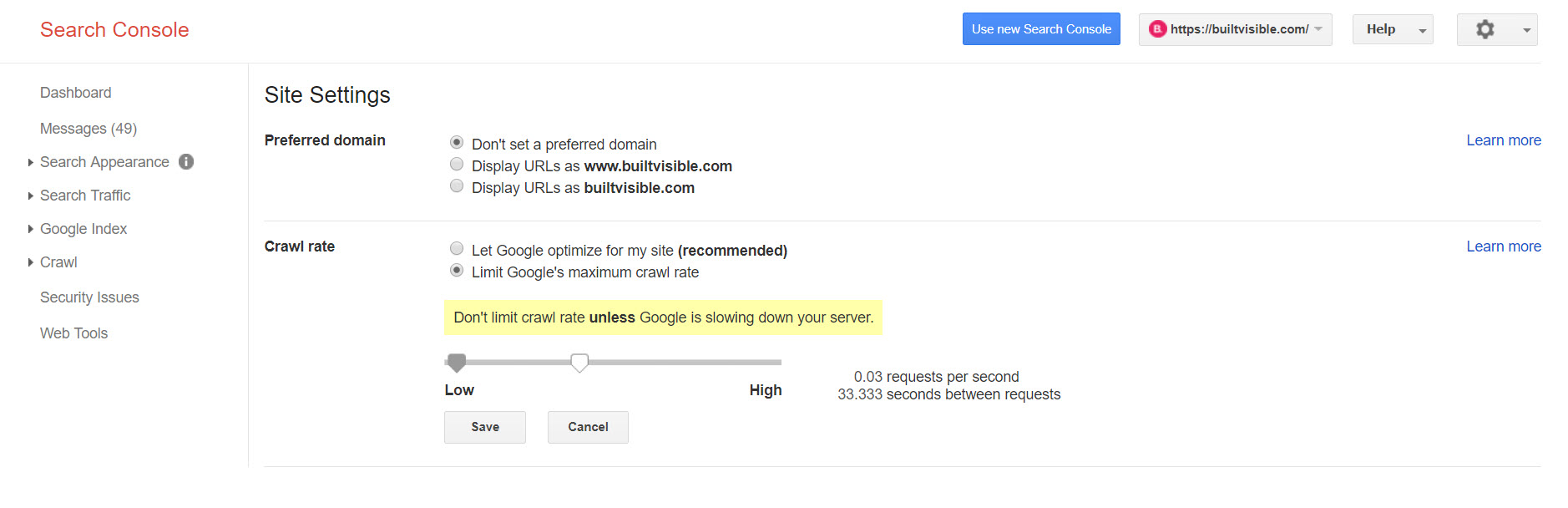
You can still adjust the crawl rate settings in the *old* Search Console. This feature doesn’t appear to be available in the new version.
Google advises you not to do this unless you have problems and I’m not totally convinced this feature will ever speed up your crawl rate. That said, it might be worth testing – just watch your logs to see if the number of pages requested per day increased.
What I would say is that my observations of crawl via the Search Console show that when something changes: you compress all the images on your site, you change server IP or switch to SSL – these things trigger a huge flurry or crawl activity too.
For now that’s everything I can think of – do let me know how you get pages indexed quickly!
By the way, sometimes it’s useful to get a 3rd party web page re-indexed quickly too. Some recent tests I’ve done show that you can encourage a page on a 3rd party website to be re-indexed by setting up a redirect from a page on your verified domain to the page you’d like updated.
This behavior is similar in nature to Oliver Mason’s observations made here with the URL Inspection tool. I recommend you read his article as it gives away an awful lot about how Google’s tools might treat URL redirects, and how you can gain insight by submitting the right type of URL redirects via Search Console.

Simon Piper
Hi Richard,
thank you for the great article and link to the Excel Tool (I don’t suppose there is a Google Sheets version??).
Just so I am clear, are you only able to submit a single URL API request at one time, whereas with this tool you can submit a whole bunch?
Jiri Brezina
We had some troube with Google crawling one big-ish site. A few days ago we increased GoogleBot crawl rate and from that moment, Googlebot is nonstop crawling us exactly at the specified rate.
So it seemed to work for us.
FranckN
Hi,
Thank you for this tutorial.
Do you have any idea if we could do the opposite? I mean, removing urls from Google Index?
Richard Baxter
Hi Franck, yes – this is the post you need to read.
Alex
The Rank Math WordPress plugin just introduced this functionality a short while ago and it really does make the entire process easier. Thought some of your readers might appreciate the easier route: https://rankmath.com/blog/google-indexing-api/
Hope that helps! :)
Richard Baxter
Very cool!
Dan Smullen
Hey Folks, in case you are new to SEOtoolsforExcel & want to use the function “Google Search Indexing” as Richard talks about above, you need to add the connector as explained below;
https://seotoolsforexcel.com/manage-connectors/
There are also tonnes of other connectors in there also!
Massive hat tip for creating this guide & sharing Richard. Thank you.