Think of the Internet as a database
I’ve always loved the concept of thinking about the Internet as a source of data, like a database.
But, of course the Internet isn’t a big database. It’s a collection of pages. Lots of them, and almost every page belonging to every website is built differently. Some are built very well, some are built terribly. And, while it’s all HTML, CSS, JS and so on, everything has been constructed on the basis of what best practice looks like according to its developer.
It’s actually amazing how browsers can make sense of it all and render a useful web page (see: tag soup). But, when it’s time to try to collect data, the inconsistency of the web can be your worst enemy. Fetching data from web pages can be extremely difficult as everything is marked up slightly differently.
This is where XPath can help.
Why is it useful?
I use XPath expressions to create Schemas for different websites I’d like to extract data from. Some are one-off tasks, some are for retail intelligence and content research purposes and some are intended to be lasting contributions to data feed projects.
XPath is immensely powerful in that, once you’ve solved the problem of finding the most elegant way to select data in an element of a web page, your solution will continue to work until the way the page is built changes.
How does XPath work?
When you’re looking for a particular XPath expression, it’s almost too easy simply to copy the best version of an expression you can find (usually on Stack). Obviously this is inevitable, we’re all busy and sometimes we just need a quick fix.
If you want a list of XPath cheatsheet expressions, here are some of mine:
| Thing | XPath |
|---|---|
| Page Title | //title |
| Meta Description | //meta[@name='description']/@content |
| AMP URL | //link[@rel='amphtml']/@href |
| Canonical URL | //link[@rel='canonical']/@href |
| Robots (Index/Noindex) | //meta[@name='robots']/@content |
| H1 | //h1 |
| H2 | //h2 |
| H3 | //h3 |
| All Links in the Document | //@href |
| Finds any element with a class named ‘any’ | //*[@class='any'] |
| Grabs hreflang attribute values | //link[@rel='alternate']/@hreflang |
But there’s more to it than copy and past XPath expressions.
XPath has expressions, it has filters (predicates) and functions. The more you’re aware of what it can do, the more likely you’re going to save time at your keyboard sweating away trying to solve a problem you’re not completely comfortable approaching.
We’ll start with the basics and move on to the more challenging problems XPath can solve later in the article.
Fundamentals: How to write XPath
XPath uses path expressions to select elements in an XML document (or HTML document, of course!). So, a basic understanding of the path that describes the location of the element you’re interested in is the first and most important thing you’ll learn.
Let’s use this page from Cheapflights.co.uk as an example.
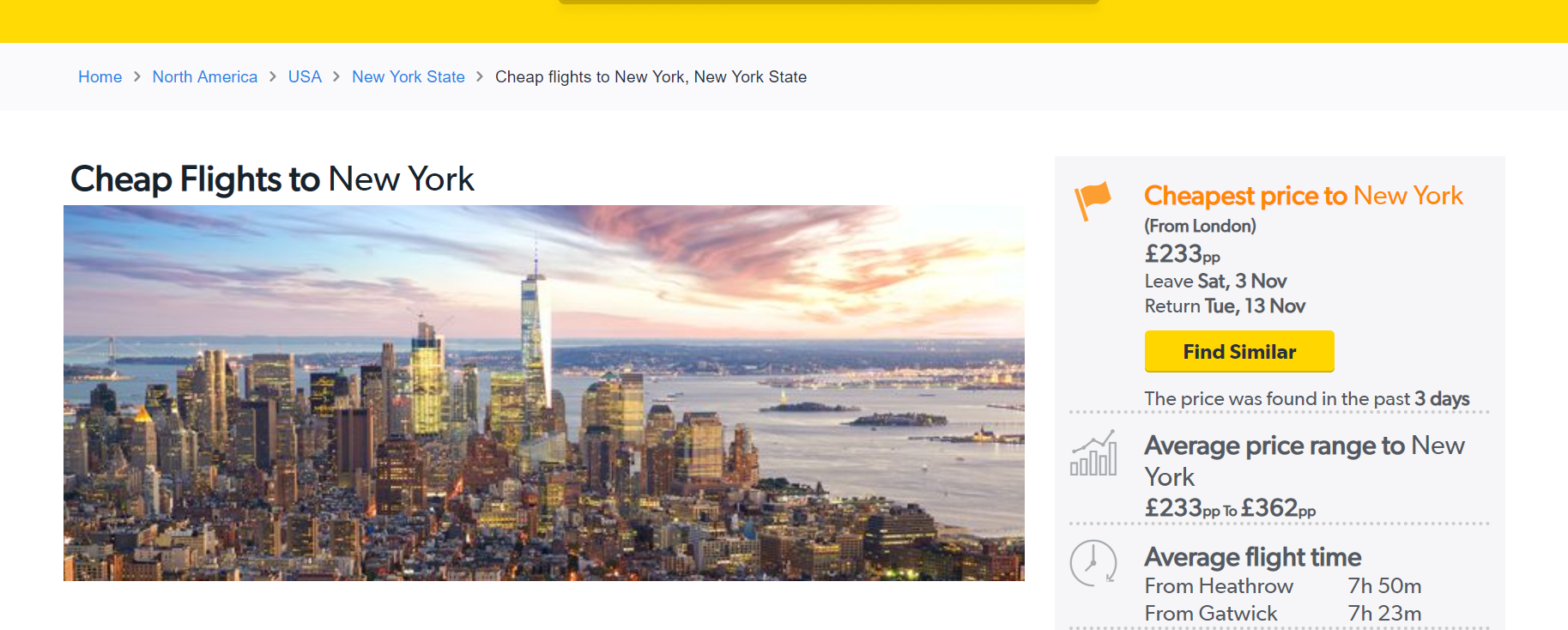
Take a look at the XPath query as I write it (ignore the suggest items for now!).
The tool I’m using is Scraper from the Chrome Web Store. It’s a simple, but fast tool to create and refine XPath expressions on the fly. I use it to write almost all of my XPath expressions before moving them to my scraping tool of choice. You can use Chrome Developer Tools to evaluate and validate XPath and CSS selectors too; here’s a useful step by step.
Location paths
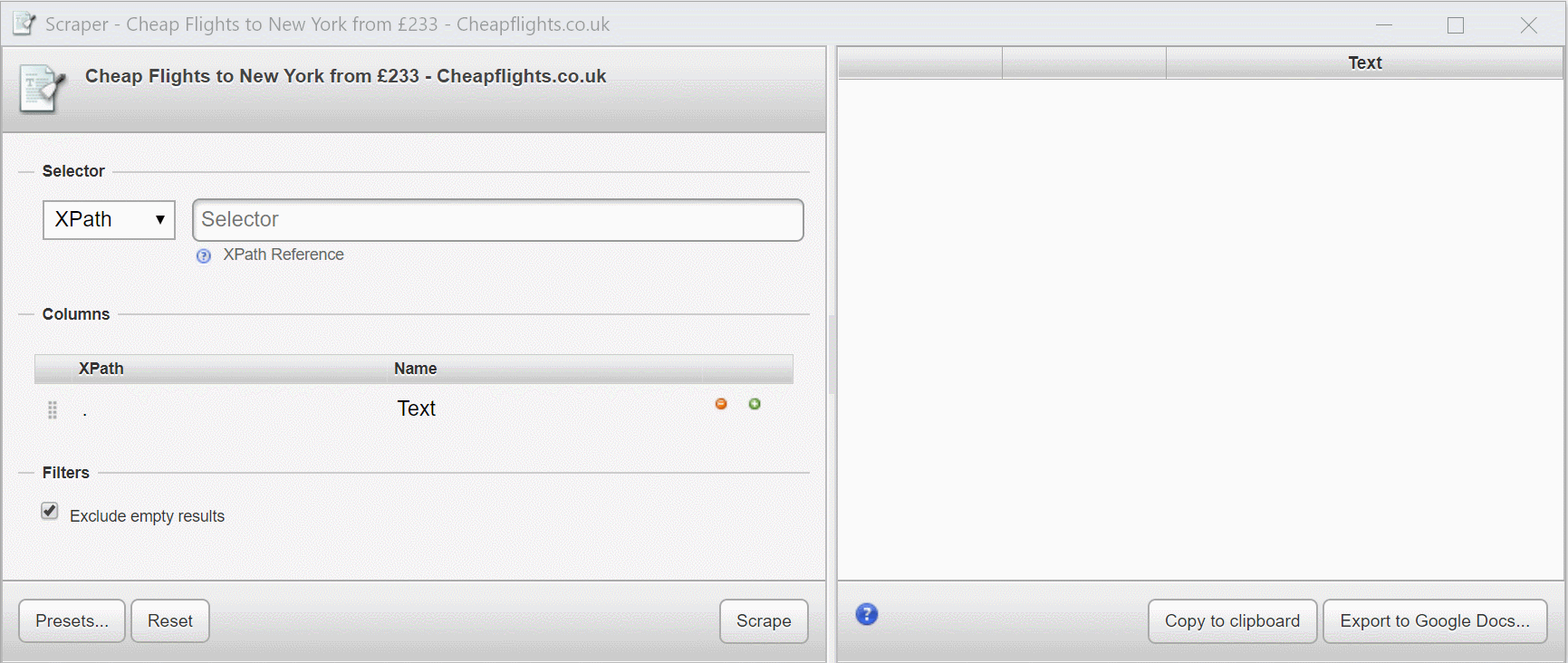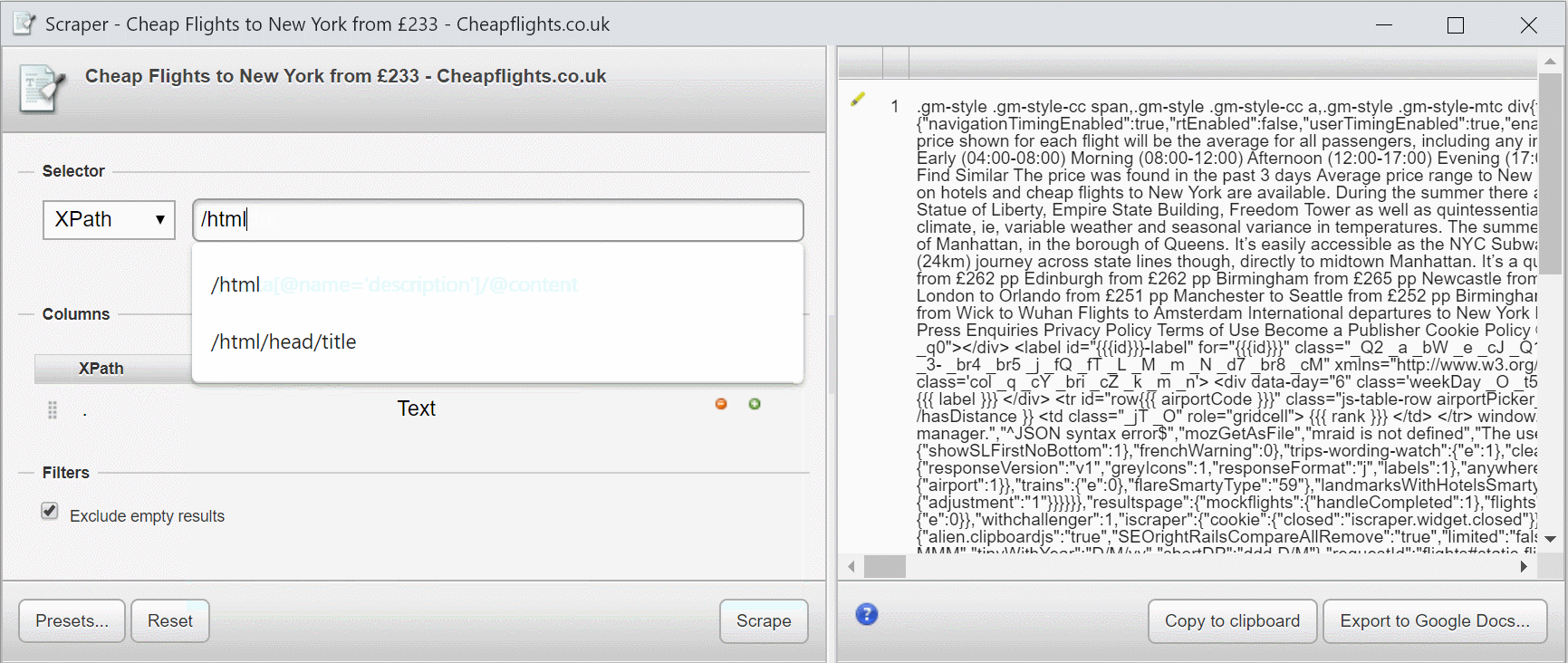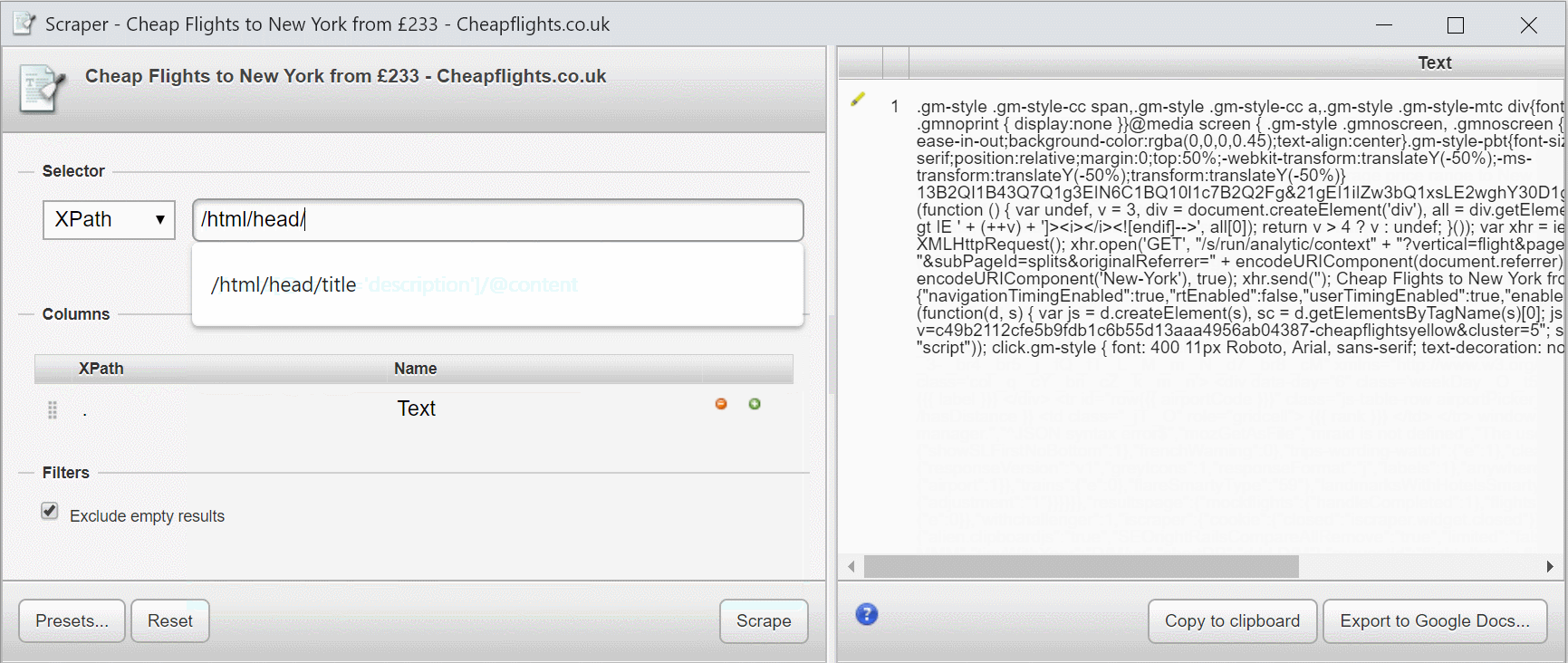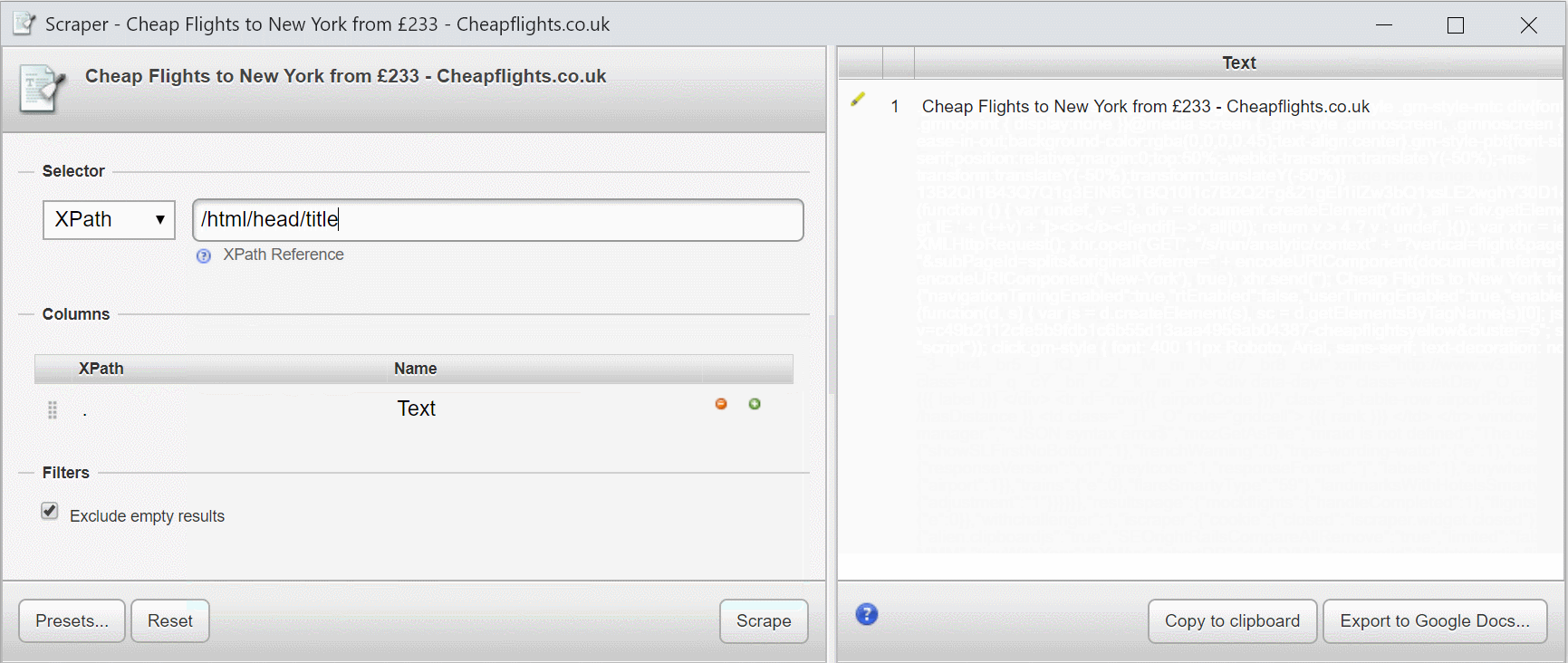
What’s important in my example above is that my XPath expressions selects from the root node (the element) with /.
This essentially selects the entire document as you’ll see in the preview
If I add /html, nothing changes as the html element is the root node.
If I add /html/head, only the contents of the head element are selected.
If I add /html/head/title I get the contents of the title element.
A “node-by-node” path expression isn’t usually how we write XPath, but it’s handy to explain how it works.
So, to fetch the contents of a specific element (in our case, title) we’d skip the full path by using the abbreviated syntax: //title.
Just like this:
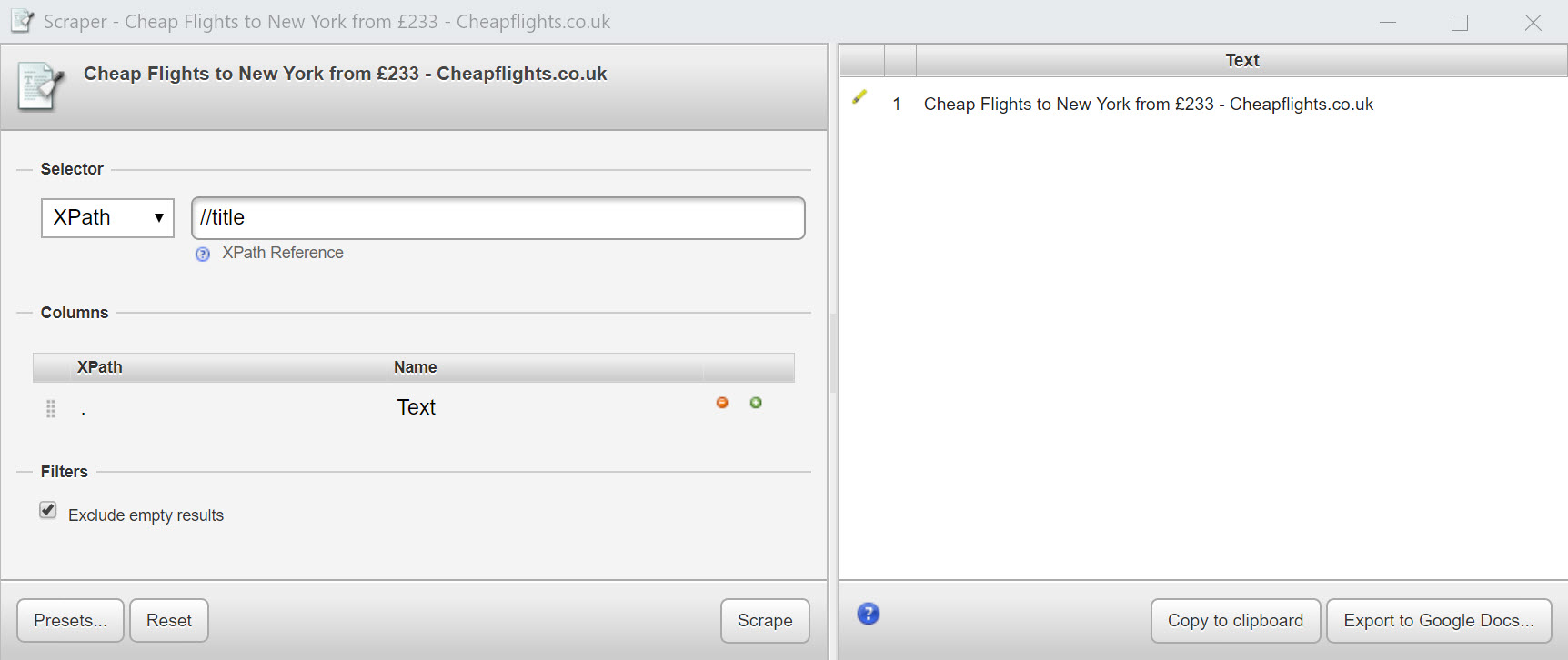
Technical bit: // in the abbreviated syntax is short for descendant-or-self, which means the current node or any node below it. This part of the expression is known as the axis which specifies the node or nodes to select based on their position in the document tree (for example, upwards, downwards, parent, child and so on).
Extracting attributes
What if you want to extract the href attribute from all the elements in a page?
Use: //a/@href
//@href would give you all href attributes from any line in the page source including references to css files, JavaScript and so on.
You could achieve the same result with //*/@href.
Predicates
A predicate is much like making an if/then statement inside your XPath expression. If the result is TRUE, then the element in your page will be selected. If the predicate result is FALSE, it will be excluded.
Let’s consider this expression:
//*[@class='any']
Which would select any element with a CSS class of “any”.
Extracting a price from a product page
Let’s put something like this into practice with this product page for an Anglepoise lamp. I’ve highlighted the price on the actual page and the corresponding code found via Inspect in Chrome Developer Tools.
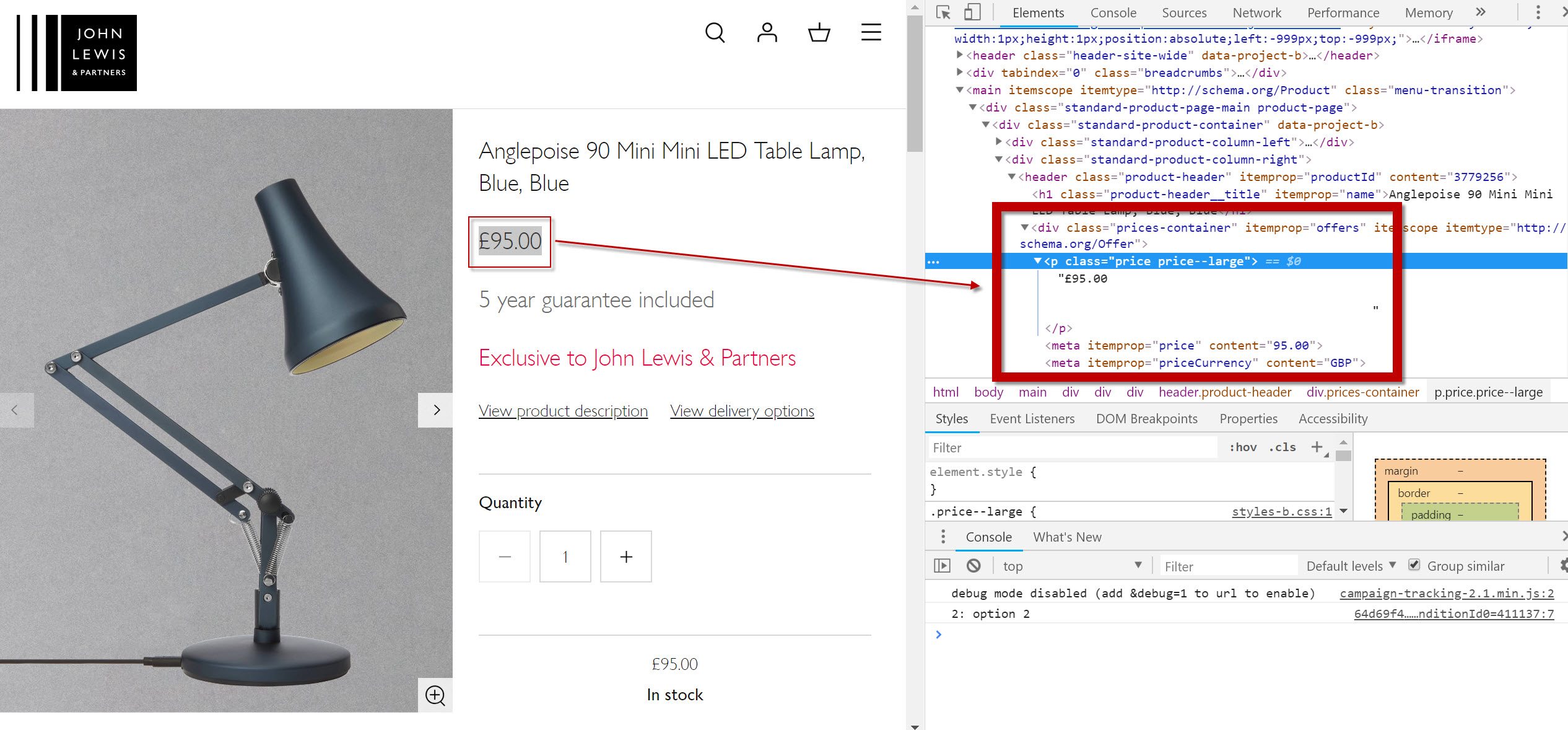
To grab the price, we’ve actually got a few useful data points in the markup.
Either, a P container with the CSS class attribute class="price price--large" or, the product schema structured data.
I’d actually prefer to use the Schema reference but, for completeness let’s use both examples:
//p[@class='price price--large'] which would deliver:
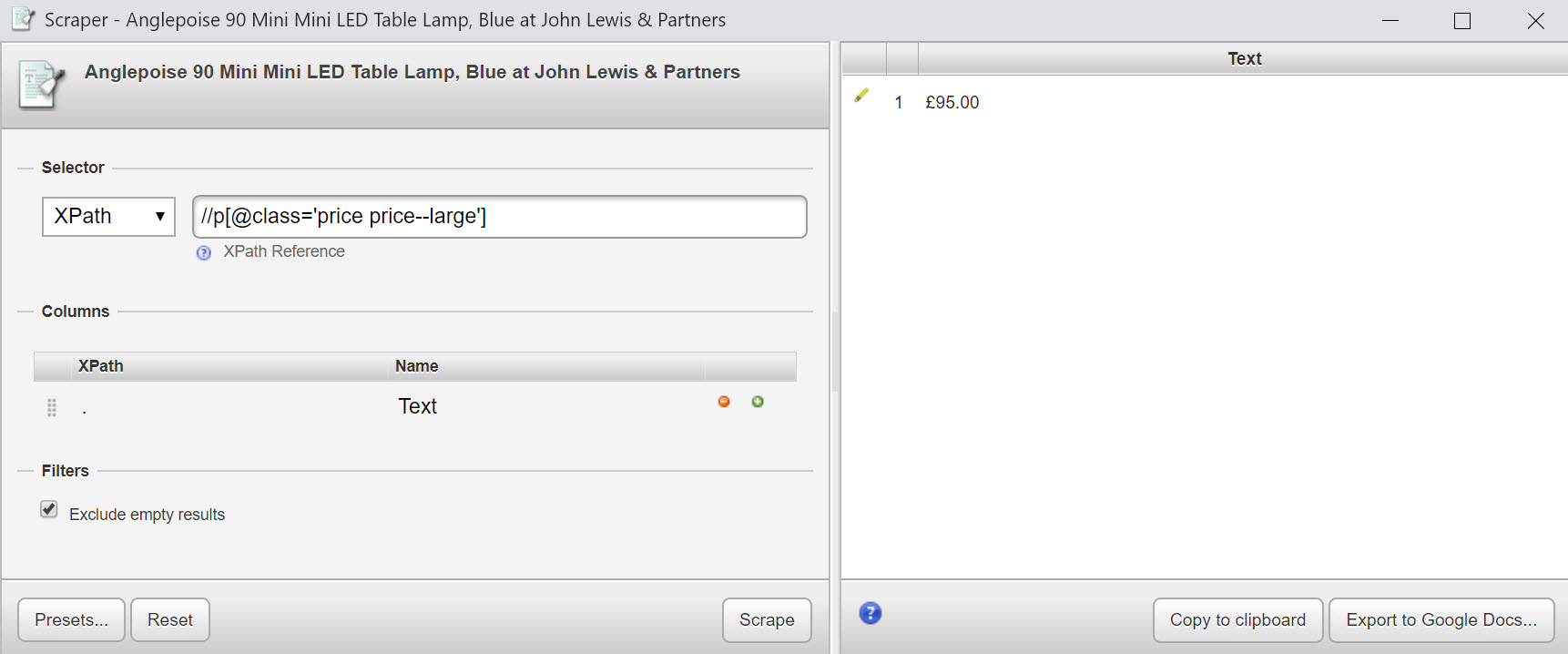
Although you can see there’s a lot of white space in the HTML source around that price, so it might be a good idea to wrap all of this in the normalize-space function:
//p[normalize-space(@class) = 'price price--large']
We could also go another way by grabbing the data from the structured data in the page. Assuming that Schema markup for products doesn’t change in the near future, we’re protected from John Lewis making any changes to the HTML structure and CSS class names of their site.
Try this: //meta[@itemprop='price']/@content
or
//*[@itemprop='price']/@content
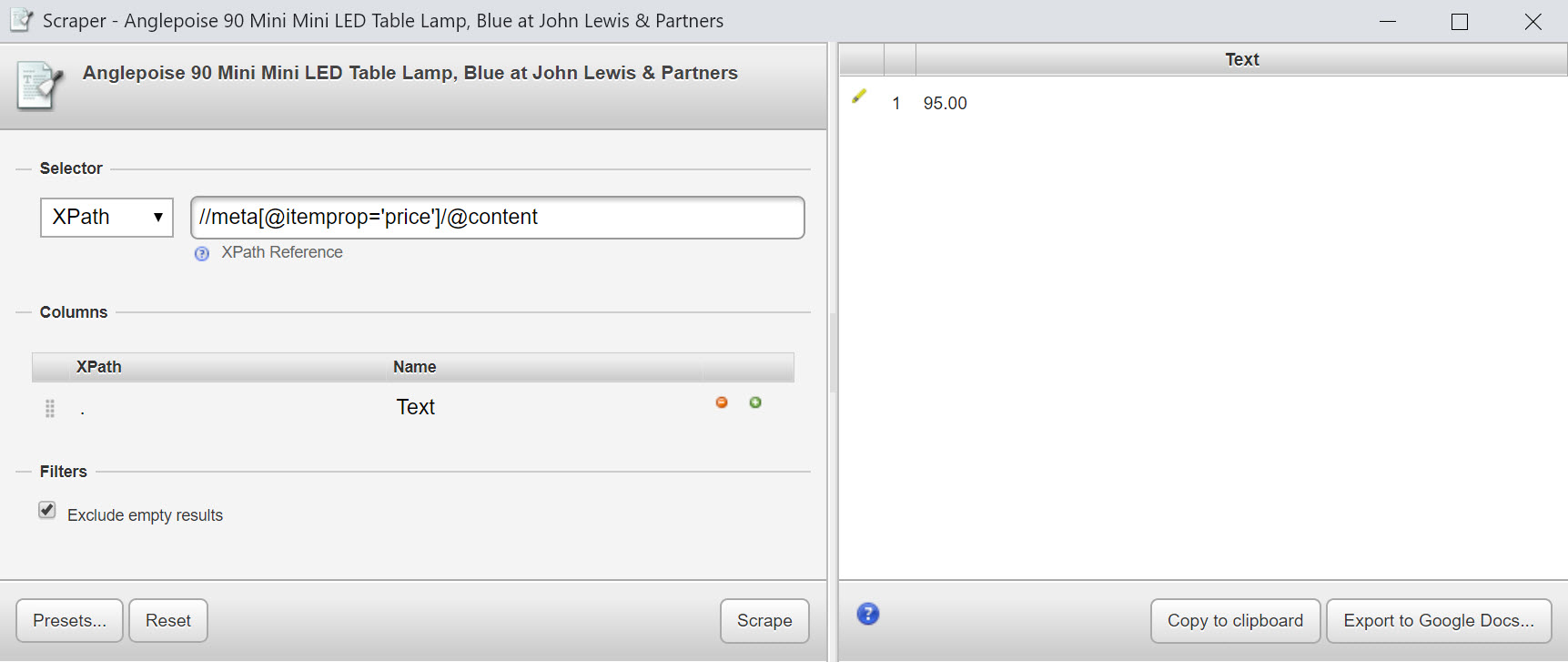
Using our expression above, we’re able to extract a lot of interesting data from the structured data on this product page, including:
| Thing | XPath |
|---|---|
| Price | //meta[@itemprop='price']/@content |
| Image | //meta[@itemprop='image']/@content |
| Name | //h1[@itemprop='name'] |
| Product ID | //header[@itemprop='productId']/@content |
| Stock Status | //meta[@itemprop='availability']/@content |
For more on scraping data on retail product pages (and automated that data as a feed) read this article.
Extract data from tables
I came across an interesting problem where important items of data, such as product SKU and weight were in a “Technical Details” table like this:

To extract the SKU, I’d select the table cell that contained the text “BG” using the text() node test:
//td[contains(text(),'BG')]
With weight, however, the challenge was slightly different as the numbers in the value cell were always different! The solution looks like this:
//td[contains(text(),'Weight')]/following-sibling::td
Where following-sibling selects the value contained in the next td along the Axis.
These are niche problems to solve but, if you ever have to extract data from tables that vary in size and format, it can be a lifesaver!
XPath functions
XPath functions are cool. There are lots of interesting functions listed here – the ones I find myself using most often are:
- Count()
- Contains()
- Starts-with()
- Normalize-space()
Using Count
Of all the functions to put a smile on my face, this is the one that really brings home just how powerful XPath can be. Also, huge thanks to the Screaming Frog team for featuring an XPath parser that actually works.
Consider this flight route price page from Kayak.
It lists a number of flight deals (as you’d expect. But how many?) Each deal is marked up with CSS class attribute, ‘resultPrice’.
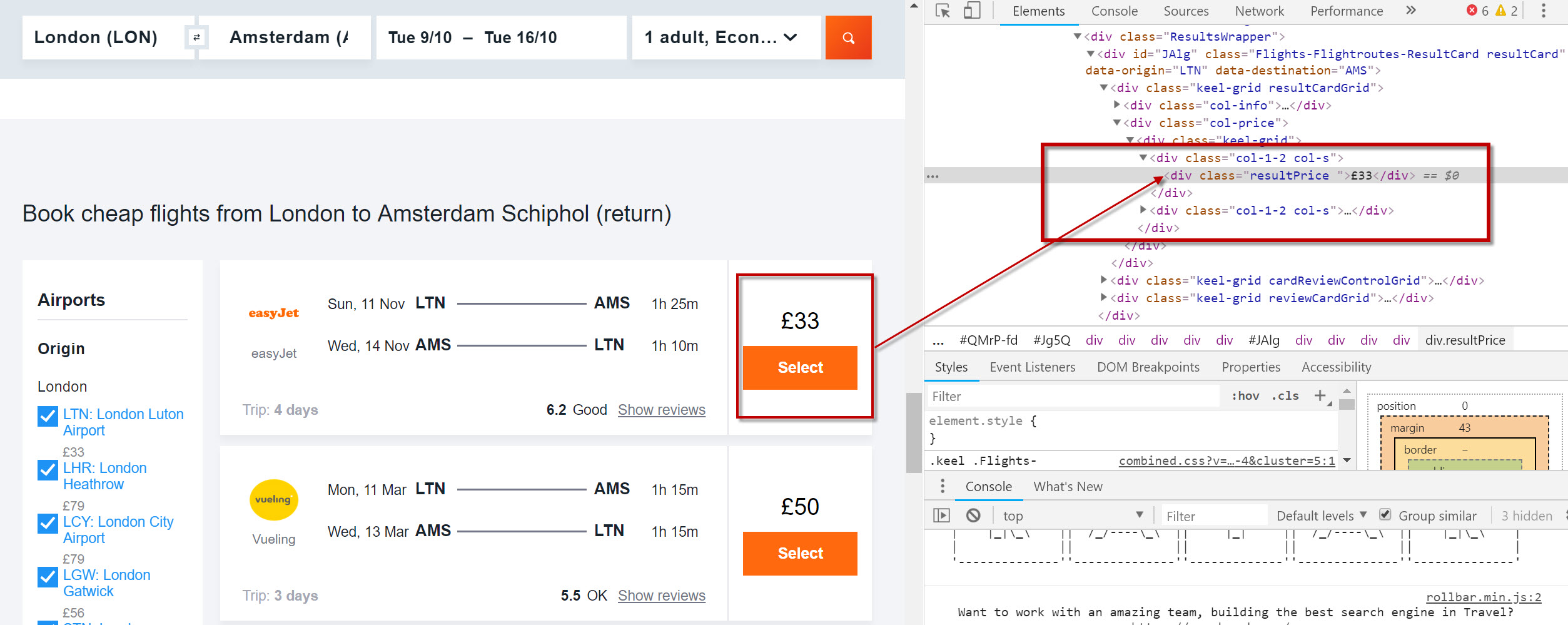
Try wrapping your XPath expression with the Count() function and adding to Screaming Frog’s Custom Extraction tool:
count(//div[@class='resultPrice'])
Being sure to select “Function Value” as the desired output:

The count result will appear in a column in the usual place:

When I worked at Cheapflights, we were very clear that a low number of deals listed on the page significantly affected conversion. And not in a positive way! Back then it was fiendishly difficult to get a quick measure of pages with weak listing content (unless you had developer time to query the database).
With Count() that problem is solved. For retailers, identifying weak category pages without a decent level of product coverage should be a walk in the park.
Using Contains and Starts-With
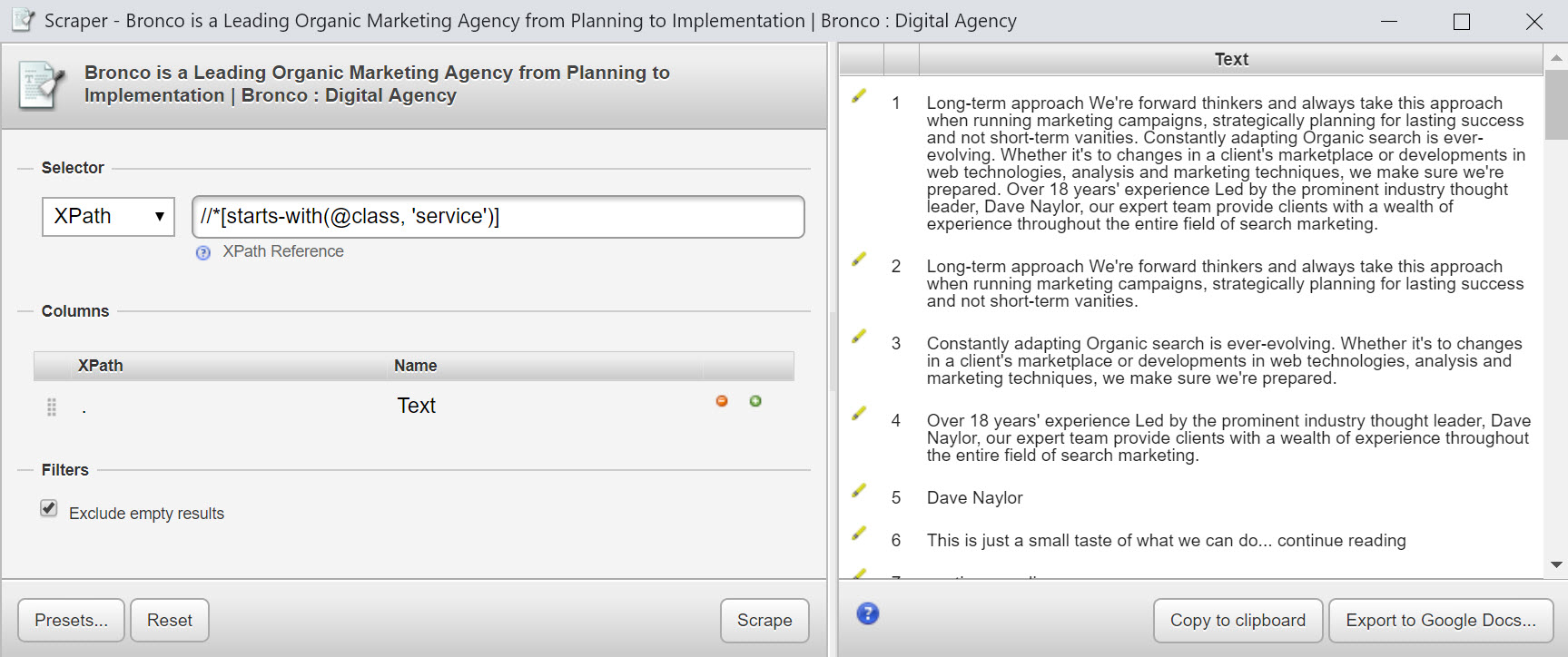
Contains and starts-with are useful search functions that I might use to catch all attributes that are similar – either that they start with the same characters but end differently, or that they just contain characters I’m looking for.
For example, I might want to find all elements of text that are in containers with the word “service” in the CSS class on my friend Dave’s search engine optimisation page :
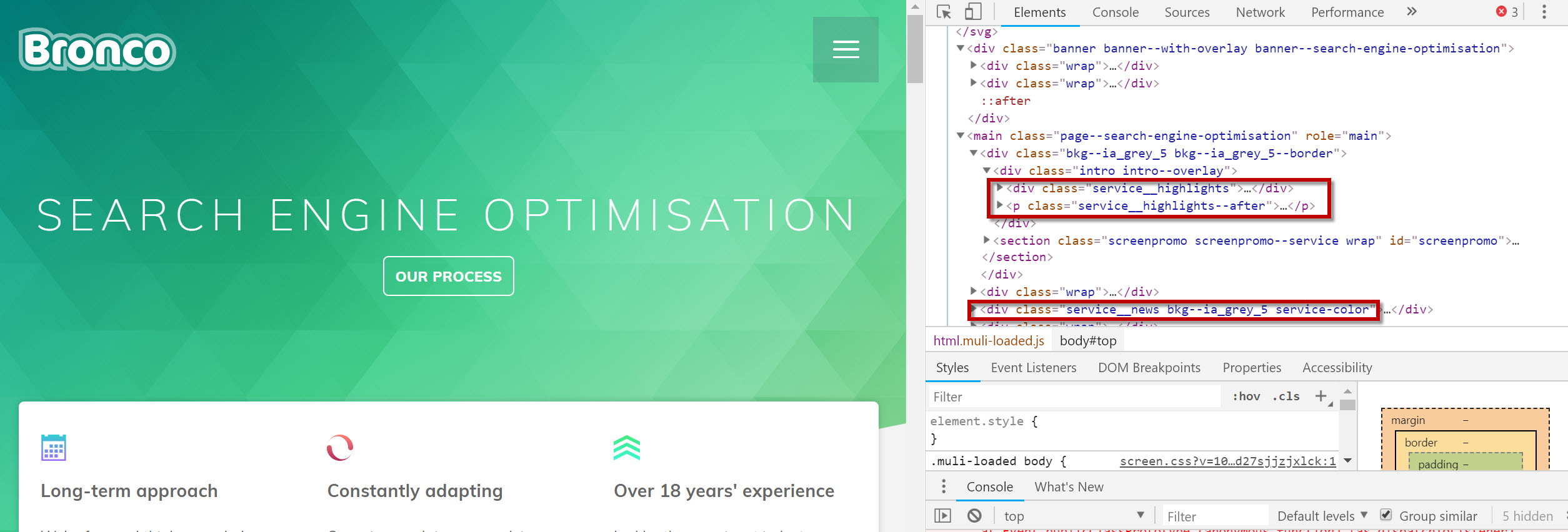
Something along these lines might work for you:
//*[contains(@class, 'service')]
Or
//*[starts-with(@class, 'service')]
Remove white spaces with “Normalize-Space”
Finally, we covered normalize-space earlier in the article – a useful function to strip the leading and trailing white space from a string of text, replacing sequences of white space characters by a single space.
How to collect data
We’ve talked about the Scraper extension for Chrome, which has a lot of merit but falls short for any serious scraping. So what other options are available?
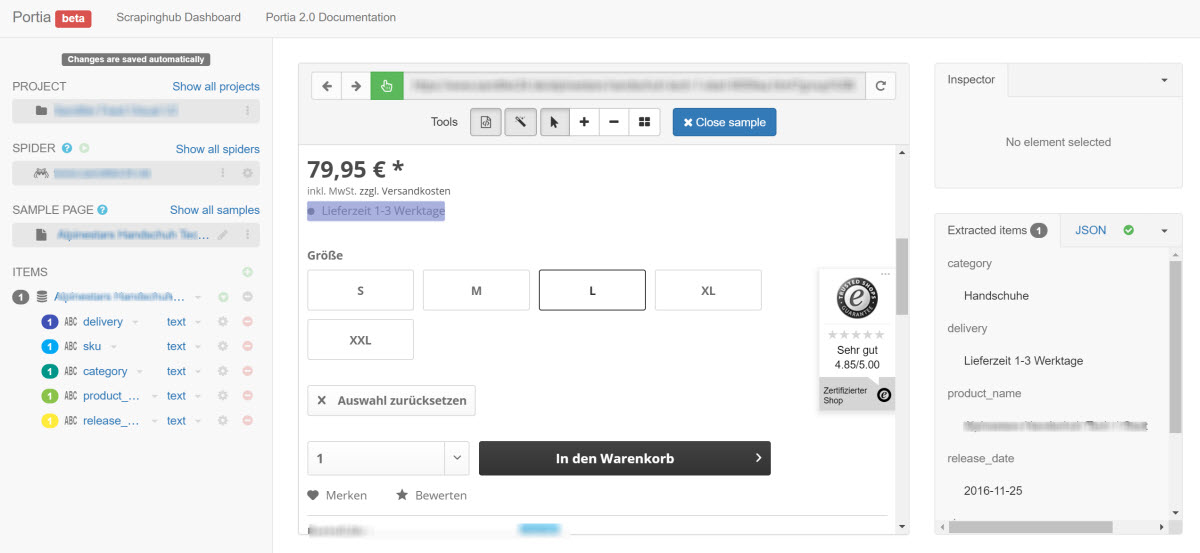
Scrapinghub
In full fat developer mode Scrapinghub is a powerful, scalable and inexpensive scraping tool. Scrapy Cloud is a developer focused environment configured specifically for scraping. It also has a visual UI called Portia that can accept visual point and click inputs. It also accepts custom XPath and CSS Selectors, too.
SEO Tools for Excel
Lots of people I’ve spoken to admit they haven’t looked at SEO Tools for Excel for a while. Yet in my opinion the latest version is surprisingly powerful and well worth a look. The XpathOnURL() function can extract data from 10,000’s of URLs. The multi threading features of the plugin also allow you to continue to work in Excel in another tab, such is the difference between the old and newer versions!
Screaming Frog
As I’ve demonstrated above, the custom extraction feature in Screaming Frog is outrageously powerful. This tool needs absolutely no introduction whatsoever. All I’ll say is that it tends to be my first port-of-call when I’m prototyping new ideas that use XPath.
A typical custom extractor for me might look like this:

Google Sheets
I’ve never really found much need to use Google Sheets over and above the other tools that I have, though Google Sheets should get an honourable mention. The =ImportXML() function allows data collection via XPath expressions. Take a look at this guide or follow my friend David Sottimano who is a big supporter of building SEO Tools in Google Sheets via his OpenSourceSEO.org project.
Further reading and tools
- Evaluate and validate XPath/CSS selectors in Chrome Developer Tools
- Dev Hint’s XPath Cheatsheet
- XPath Syntax
- XPath Playground
- Regular expressions and XPaths alternatives every SEO needs
- XPath functions
- Using XPath functions
- How to use XPath in Screaming Frog
- How to extract title & meta data using Gdocs, Xpath and ImportXml
- How to scrape page data using the ImportXML function in Google Sheets

Donald Piccione
Hi Richard,
I found your page because my connection on LinkedIn posted. It is my first time as marketer that I hear about Xpath and it took me about 2 days to settle down on this concept of data extraction using scraper and the syntax you wrote in this page. At first I didn’t understand what was the correlation with SEO as I thought that using Xpath you could do something directly towards the optimization. Now I understand its uses and I am currently testing few pages doing queries on title, h1 and meta description. It is very fast getting this data. I have screaming frog and too be honest I didn’t know you can use it for this purpose too. There is always room to learn in our field. Thanks again for your guide that I found easy to understand with practical example. Cheers, Donald
Mohd Amir
Oh! What a great piece of information, thank you so much Richard you have literally explained each and everything making it absolutely clear. The article is written in a manner that it seems as if it is written to make things clear and not just be read. Thank you for such an informational article, looking forward to reading more of your work.
Marcos Séculi
Thanks for such a usefull post! It is my first time reading about this topic and I consider this is the new SEO.
Hugs!
Stephen
Hopefully that’s not actually the real Dawn, as that’s pretty rude!
I remember when ImportXML first came out and Distilled had an awesome guide! A lot of those formulas have since broken, so this is now one of the better, short, straightforward guides out there!
Even experts could use a refresh of the fundamentals, and an up-to-date reference like this.
Richard Baxter
Thanks Stephen, I don’t believe it was so I’ve deleted the comment. Thanks for the kind words!
Al Gomez
Hi Richard,
Cool guide you’ve got here, it’s nice that you have shared this one. I like the samples you have shared and the depth of this content.