Scraping product pages is difficult, and it’s different every time
Scraping websites with variable products (drop-down selectors, checkboxes, radio buttons) that use a random variety of XHR POST and GET requests to update information such as availability and pricing in Javascript is difficult.
Every website you tackle is almost a completely new challenge as they’re all so different. Websites with variable options doubly so.
So this article shares my methods and an approach for a number of different circumstances that I’ve encountered along the way. Some of this is of course very niche, like using SEO Tools for Excel to make POST requests to an API endpoint.
It’s niche, but technical and therefore very interesting.
The main problem is this:
How do you build a product feed on a website that has variable options?
It’s actually quite difficult because most retailers have products with variations and variation-specific data isn’t forthcoming until you (as a user) have physically selected the correct options.
Once options on the product page are selected, what happens next depends on the platform.
Requests tend to be made via XHR / Ajax request, either using a Javascript library unique to the platform or something more common like jQuery. Parameters describing the product variations are added to a request URL ready for a GET request, but sometimes those parameters are sent in the form data via a POST.
The results are received as a text, JSON or CSV response (usually JSON but often some random format) and the page is updated appropriately. Sometimes all the data is already available in JSON embedded somewhere in the page source, and the JavaScript is simply updating the DOM based on what’s already there.
So there’s an awful lot of nuance in deciphering how a retail CMS updates product pages, and if you want to grab a retailer’s data, it’s an equally nuanced procedure.
Before you do anything then, you need to start by gathering some information.
Information gathering
I always start by collecting notes.
What technology platform is this? Are there any useful clues in the robots.txt file? Is there a decent sitemap.xml file?
Where is the API documentation? A surprising number of sites just leave their API exposed by complete accident.
I’ll poke around in Chrome Dev Tools, heading straight to “Network > XHR”, and select an option on the page to see what happens. This action usually exposes how data is supplied to update the page. I also check for the HTTP method used.
GET is the typical method although you do come across POST which is a different ballgame to work with. If POST is the method, this approach will expose the endpoint to which POST requests are made and responses received.
I’ll make notes about the drop-down selectors too; the value and ID attributes in the form input element are usually the parameters needed to pre-select the options via a URL GET request.
Often there’s evidence that a product URL will accept parameters to pre-select product variations. A Google Shopping result might give up some information, or a technical question on a forum. As there are only so many CMS platforms, the chances are, after a while you’ll have worked with them all.
Take a look at this example, a set of size selectors using (styled) radio buttons:

In this particular case, everything I’m going to need is contained in the label element in the for="" attribute. Collecting this data may well be important, so it’s useful to know the XPath to these snippets of data.
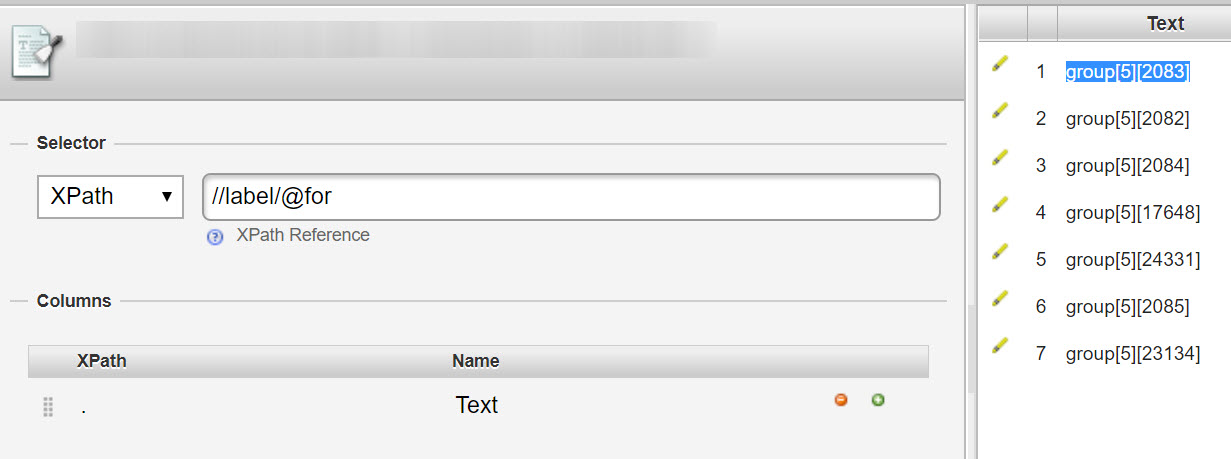
In our example about, the XPath: //label/@for extracts the parameters group[5][2083].
Usefully, these parameters can be added to the end of the URL to pre-select the relevant options. For example:
Request URL (GET) /product-page.html?group%5B5%5D=2082
So I hope you can see where a process might be forming! Generally, the goal of the information gathering phase is to answer questions like:
1) Can a page be loaded with options pre-selected or is there a URL that supplies the information I’m looking for?
2) Can those option values be extracted from the product page on a first pass scrape?
3) Can I concatenate these as parameterised request URLs ready for scraping?
4) What’s the best way to schedule a scraper?
Keeping notes along the way pays dividends down the road.
URL concatenation for parameterised GET requests
Once you’ve done your research and you know what you’re aiming for, it’s time to start gathering the actual data. I like to be able to build text lists of URLs that feature the data I need so that I can scrape them one by one.
To be able to build such a list, the process looks like this:
- Fetch all form values for each product URL
- Concatenate URLs with each combination of values added as parameter
- Save as a .txt file
Fetch all form values for each product URL
The example below is a website that displays delivery time (10 work days!) and the SKU number when one of these boxes are clicked. They’re actually styled radio buttons, but that makes no difference.
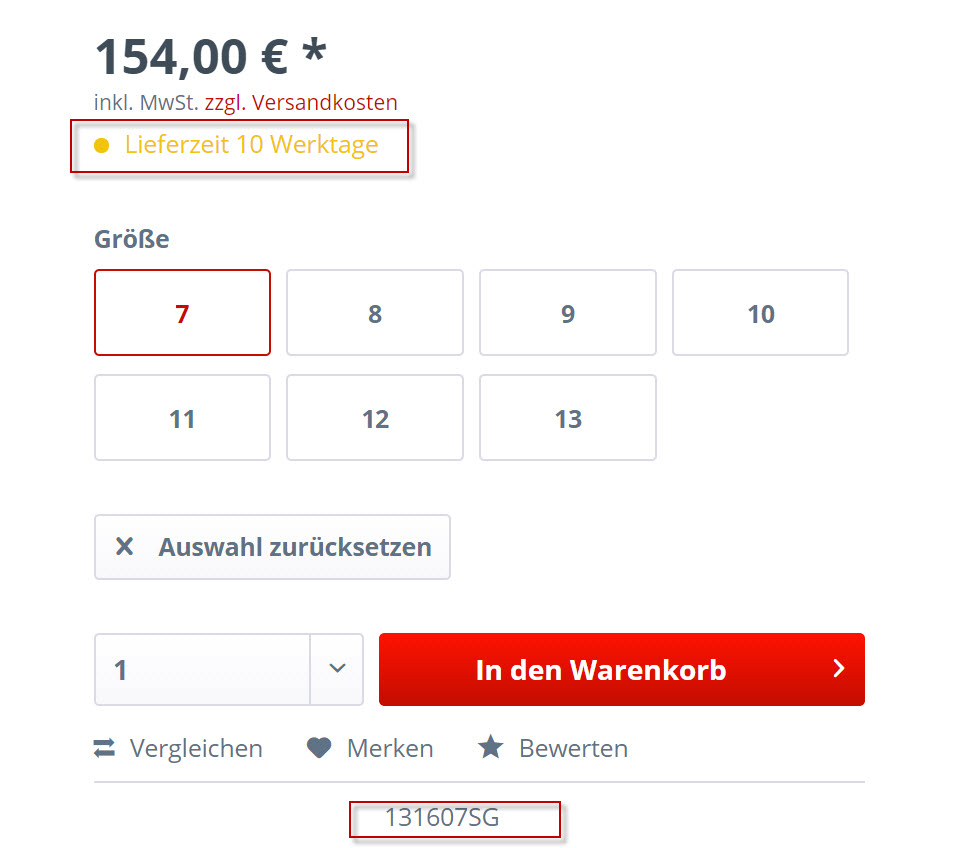
What’s important, is what happens when a radio button is selected:
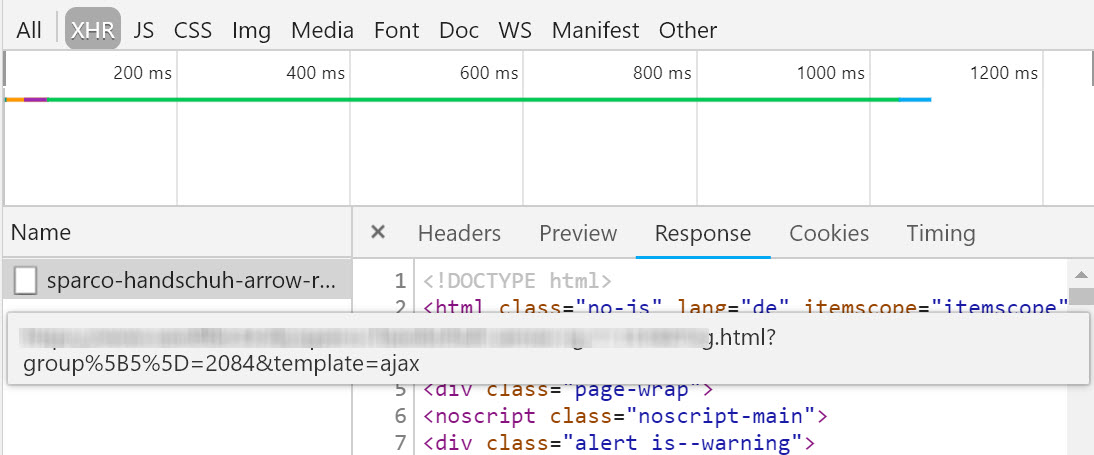
This is where my XPath example from earlier comes into play. We want to collect all of the parameters, of which there may be as many as 10 per page.
I end up with something along these lines:

I’m a big fan of the custom extraction tool in Screaming Frog.
It features a proper XPath parser, which includes being able to chain XPath rules with OR operators. For my use case, this feature makes it easy to chain rules together to catch different types of pages with different selectors (dropdowns, for example).
So, I collect the values for the form inputs and the names (for example, size, colour and so on).
PS: for a general introduction on how I use Screaming Frog for content research using simple XPath examples, read this article, and more recently, Dave’s article on scraping “People Also Ask” boxes.
Concatenate URLs with each combination of values added as parameter
Whenever Screaming Frog matches more than 1 result with an XPath query, it creates multiple columns in an export like this:
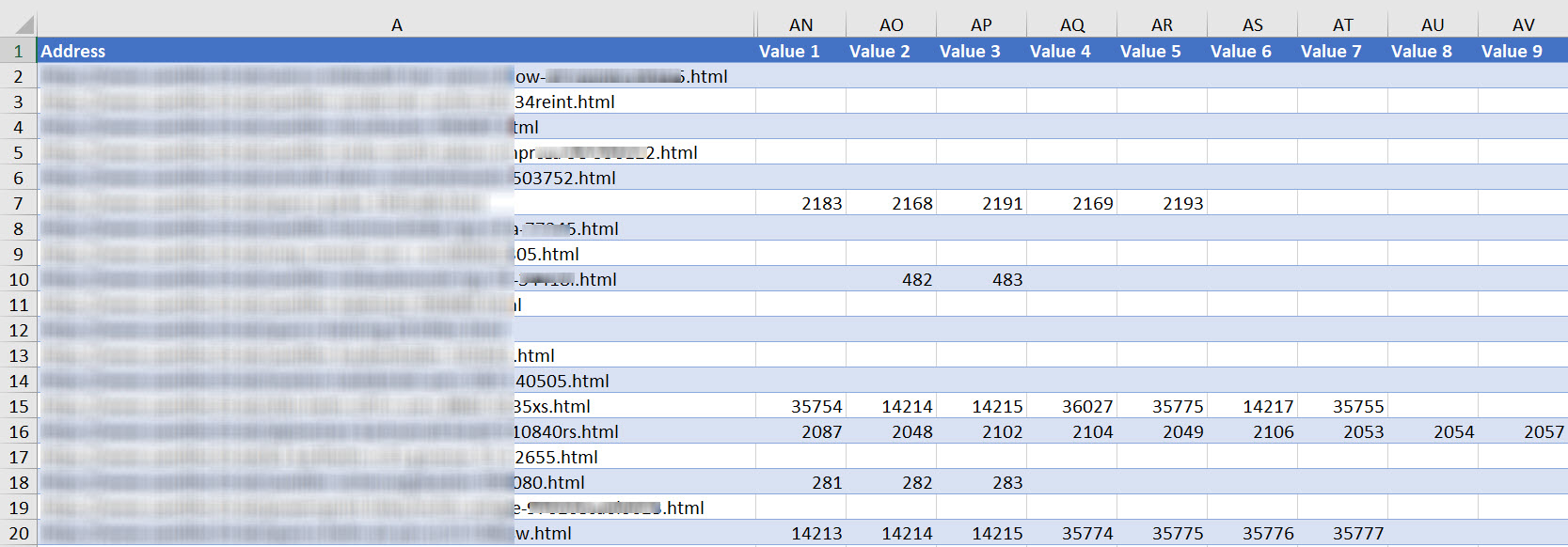
Concatenating each of these parameters into actual URLs is relatively straightforward:
Although you end up with a table of URLs that can have upwards of 18 columns! This requires some thought to transpose to a list:
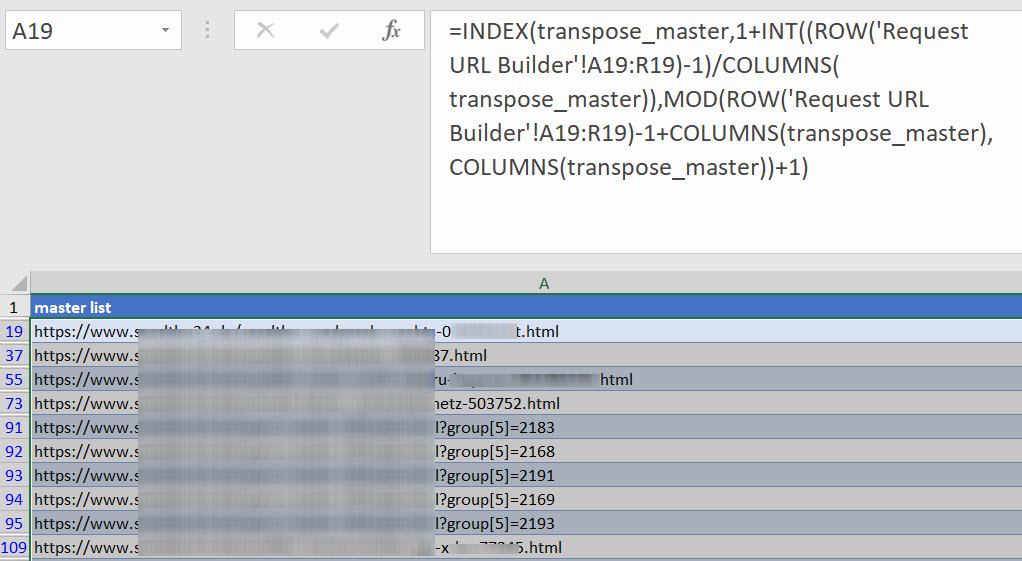
Here’s that formula, which requires the source to be a range (Excel Tables don’t work as a source for this part of the process).=INDEX(transpose_master,1+INT((ROW('Request URL Builder'!A91:R91)-1)/COLUMNS(transpose_master)),MOD(ROW('Request URL Builder'!A91:R91)-1+COLUMNS(transpose_master),COLUMNS(transpose_master))+1)
Where ‘Request URL Builder’ is the range and ‘transpose_master’ is the target table.
The result of all of this is a source list of URLs to be saved as a .txt file for a crawler to work though to collect our data.
Making POST requests
During this project, I came across a project built with OpenCart – a lesser known open source retail CMS. It doesn’t natively support variable products of any sort, so you have to install a premium plugin called OpenStock. This enables variable options to be selected on the product page.
There is almost no useful documentation for this plugin. But, after following my investigative process, it became clear the plugin wouldn’t accept URL / parameterised GET requests.
Instead, all the parameters are sent in form data via POST – see below:
(Follow along on this site’s product page for an Industry Nine Rear Hub)
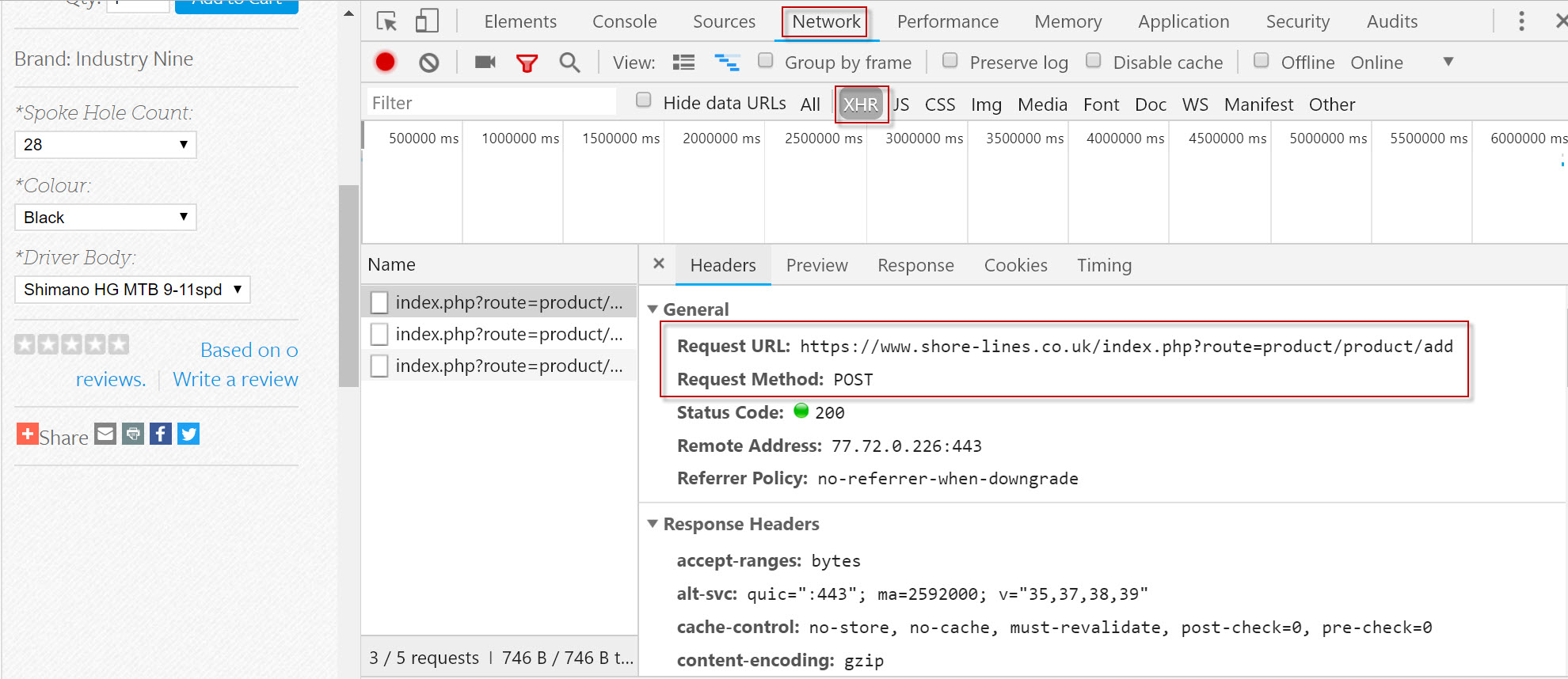
Navigating to Network > XHR > Headers reveals the POST request. Scrolling down the header information reveals the form data:
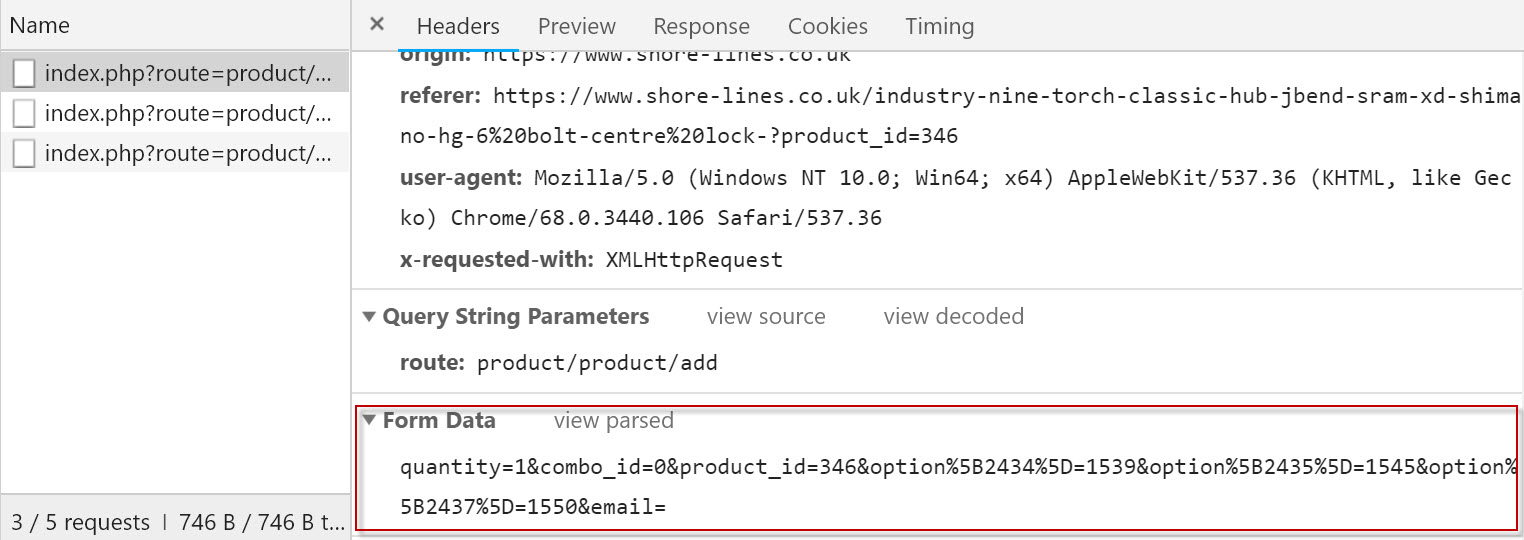
And the response, in JSON format looks like this:

When you’re trying to build a feed, discovering how this data is fetched from the server is most of the battle won.
The next challenge is to mimic the request yourself to get to the same result. For that, I use API Tester. It features a very clean and simple UI and therefore getting started is easy.
In the case of the OpenCart site, we’re actually talking about a total of 100 products, perhaps 20 of them are variation products like the one above. Given there’s no budget and consequently, no developer, I had to get creative about how to solve this problem.
Enter my old friend, SEO Tools for Excel.
SEO Tools for Excel
Now, a lot of you remember how much I used to love writing Excel posts that inevitably referred to SEO Tools for Excel from my friend, Niels Bosma. It’s €99 well spent in my opinion as it helps you solve all sorts of problems very quickly. It’s useful for prototyping things that might go on to be formally developed or just as a platform to build one-off solutions.
It’s also significantly more powerful than it used to be as the latest versions run multi-threaded requests so you can switch between tabs and keep working while it’s running a bunch of HTTP requests. Honestly if you don’t have this tool, trial it and get a licence.
Making POST requests with SEO tools for Excel
As I’ve often built prototype scrapers in Excel for a quick solution or a one-off bit of research, I’m pretty used to the =XPathOnURL() and other HTTP functions included.
This is the Global HTTP Settings dialogue inside the tool:
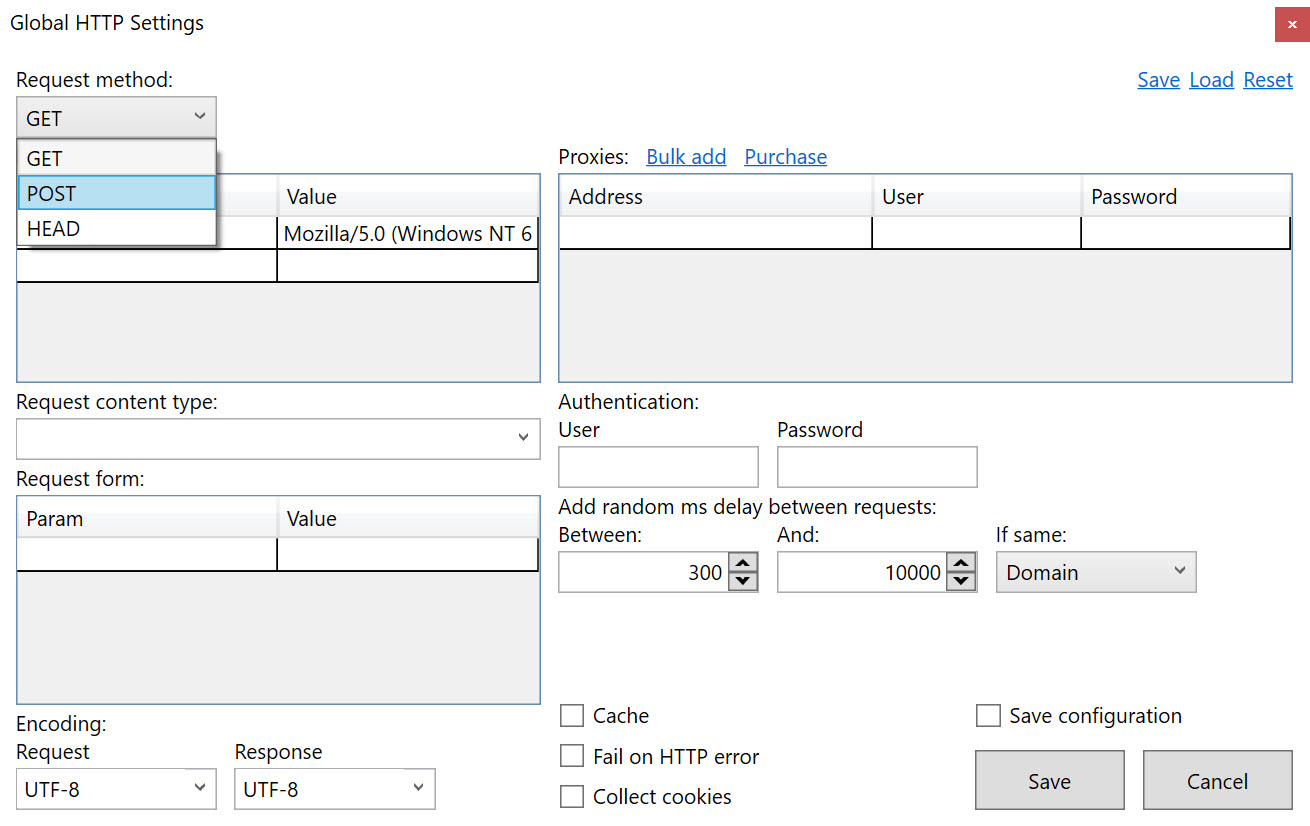
Clearly, there’s functionality available for POST requests in the master HTTP Settings dialogue. Similarly, the =HttpSettings() function allows for POST to be set as the request method.
Unfortunately, the HTTP Settings function doesn’t have support for a POST body. I’m hopeful that might change one day as it’ll open up a whole new world of coolness. However, when I reached out to the team, I got a really helpful response from Victor Sandberg who put together a connector to make this possible.
Connectors are relatively simple XML files that configure how SEO Tools for Excel connects to, authenticates with and parses the responses from API endpoints. There’s tremendous power in them, and for the most part, you can learn how they work from viewing the XML. Here’s the full collection from Niel’s Github.
Here’s the connector to make POST requests to an endpoint with two attributes submitted in the post body. The parser settings will extract SKU, Price and a number of other objects. You should be able to see how this works from the XML. The formula in SEO Tools for Excel looks like this:=Dump(Connector("Baxter.Baxter",C2,B2,"product_option_variant_id,sku,stock,active,subtract,price,image,weight,pop,nostock",TRUE))
And here’s how that looks in a table:
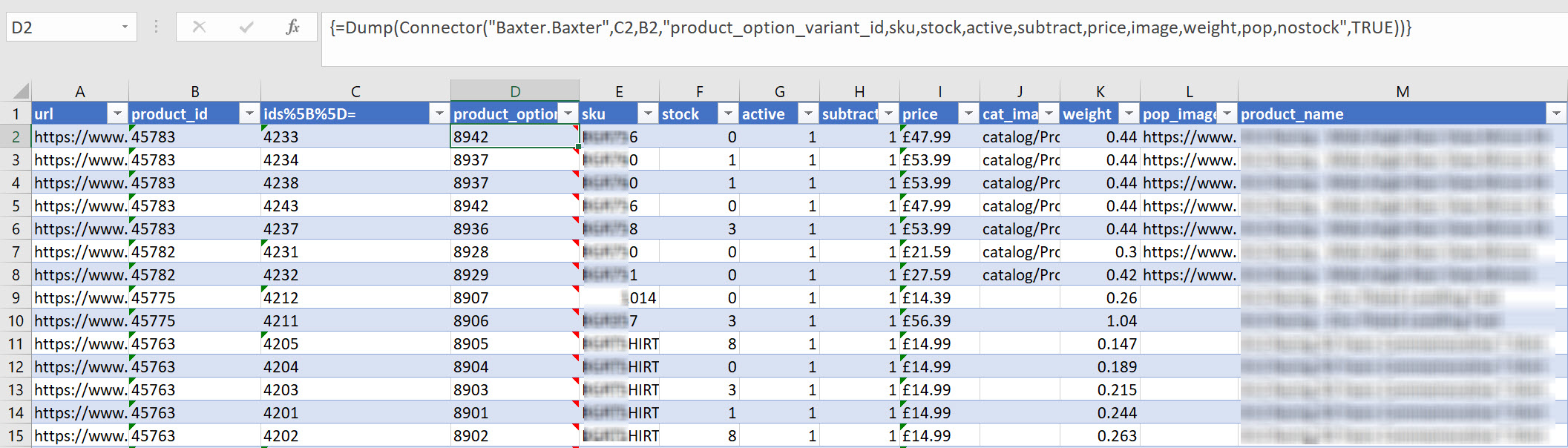
Fortunately, this is quite an edge case, although I’m grateful for the help from the SEO Tools for Excel team, and delighted that I’ve unlocked this skill. If you want to learn more about making connectors for SEO Tools for Excel, try this helpful Wiki page.
Briefing a developer to formalise this procedure would be an absolute walk in the park.
Now, to finish with the automation challenge.
Scheduled scrapers from URL lists
I strongly recommend Scrapinghub, a recommendation my friend David Sottimano made a few months back.
It has a visual scraping editor called Portia, while Scrapy Cloud is more intended for people who can write code. Either way, it’s inexpensive, powerful and well worth learning.
My setup runs from a .txt file list of URLs to scrape, approximately 20,000. It runs weekly and uploads a .csv file via SFTP to our server. From there, stock levels are updated to schedule as intended! Writing about this setup is very much a blog post to itself, so watch this space or have an explore for yourself.
Summary
What started as an initially quick job in Screaming Frog turned into weeks of data work.
Sometimes you find yourself in a position where you have to solve a problem that isn’t well documented or hasn’t really been tackled in this way before.
You might be asking yourself why not code your way out of the problem? That’s not the point here – before you build anything in code you really need to understand the dynamics of the problem you’re trying to solve. That’s the point of prototyping, and I’m very comfortable with using the best tools around me to get to a solution.
Scraping can get costly, fast. You can quickly get into a position where weeks of development work and server time is escalating costs beyond the economic scope of the project.
I really relish problems like this as personally, I think understanding how websites work is the most important skill we can have. Have fun testing this very niche technical process!
