How to gather new data for content marketing research using data scraping
In this post, I’m going to talk about the basics of data collection for content marketing and give some examples of how scraping with Xpath can be used for research purposes in content marketing projects.
For a more advanced guide to scraping, I recommend you read my guide to XPath for SEO‘s, which is intended to give teh advanced user a fuller primer on the subject.
How To Scrape – The Very Basics
The trick with scraping is to have a basic understanding of how a web page’s mark-up is laid out. That, with an understanding of the XML path language known as XPath and a few tools to help extract data. You can get started in literally minutes, as Chrome plugins and tools are freely available and simple to get started with very quickly.
Install Scraper for Chrome
Start by Installing Scraper for Chrome. It’s an incredibly simple plugin that works a little like this:
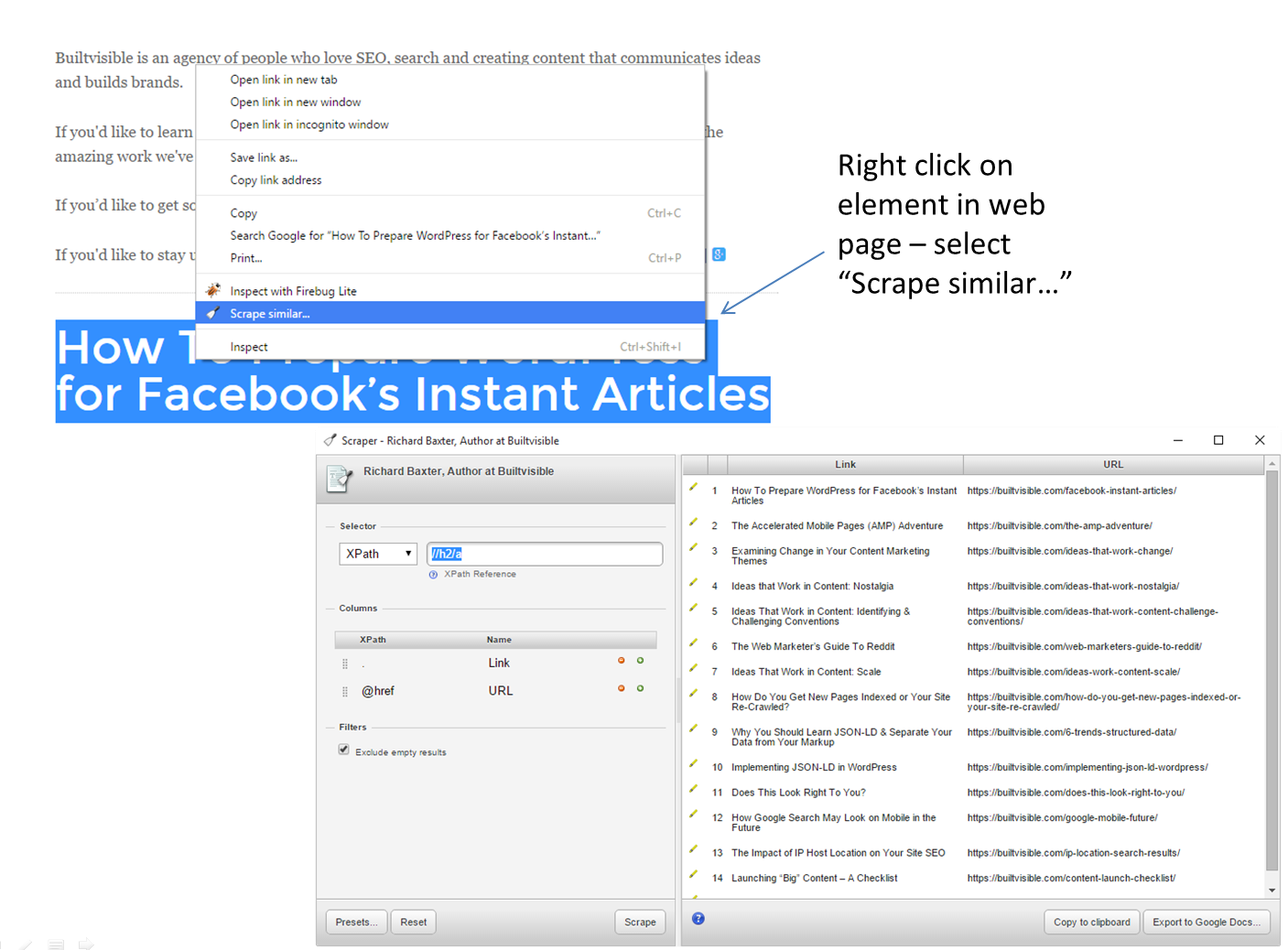
Look at the scraper dialogue. Under “Selector” you can see some XPath://h2/a
Put simply, XPath is a language for selecting elements in a hierarchy. You follow that hierarchy from the top down, which is how you derive the syntax. Take a look at the example above; the XPath selects the contents of all “a” containers that are nested in a “h2” container. In the context of my author page, that’s all post titles and links featured on the page.
In a more complex web page, it might pay to look closely at the mark-up and style classes used in the containers. Let’s switch to Web Developer Console in Chrome and have a closer look:

The h2 is styled with a class attribute called “post_title”.
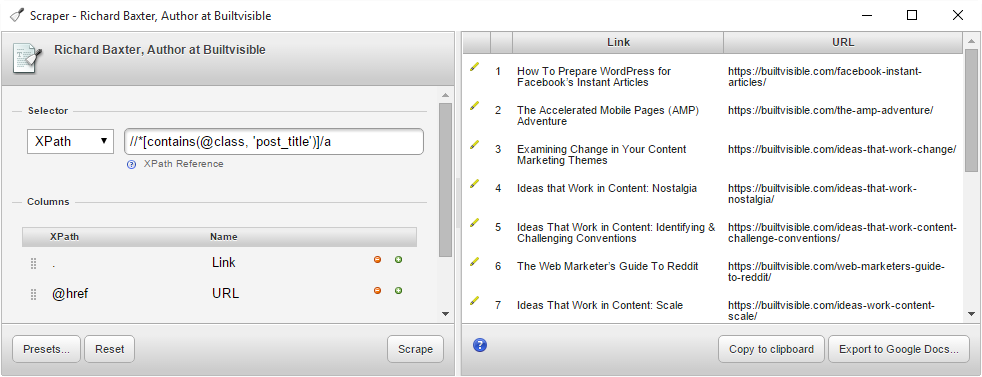
This is a useful thing to know, because you can select all containers that use this style class without traversing through a number of unstyled containers.//*[contains(@class, 'post_title')]/a
There’s a useful discussion about selecting elements by their CSS style attributes on this Stack thread. Xpath is much more powerful too, if you’re interested in learning more have a look at this quick start reference to some surprisingly powerful functions.
There are a few more tools that are pretty standard in the SEO world that are absolute must haves for data collection too.
Screaming Frog
The Frog is the best SEO crawler your money can buy.
I don’t need to write about it a great deal because surely by now you all know this. Perhaps not everybody knows a few useful features in Screaming Frog so that you could, should you wish, scrape quite a lot of data from a small to mid-size website, or a large one rather carefully.
Scraping with Filters: XPath, CSS Selectors and Regex
Screaming Frog has two massively powerful features if you’re going to use it for data extraction. Include/Exclude URLs and the XPath/Regex/CSS Selector based scraper.
Include URLs is really easy to configure, and gives you quite a lot of focus over which pages you’d like to crawl on a site. In the example below, category pages linked to via the Women’s clothing category on asos.com
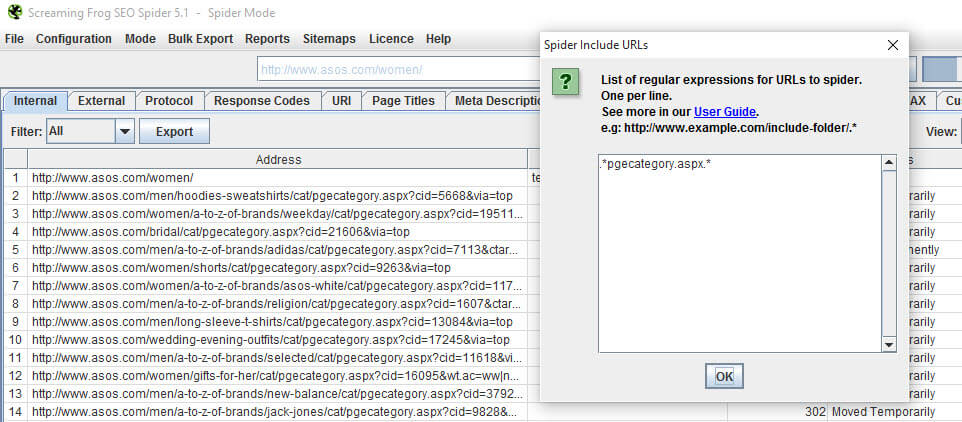
Several site architecture data collection ideas spring to mind with this feature, but today we’re more interested in scraping.
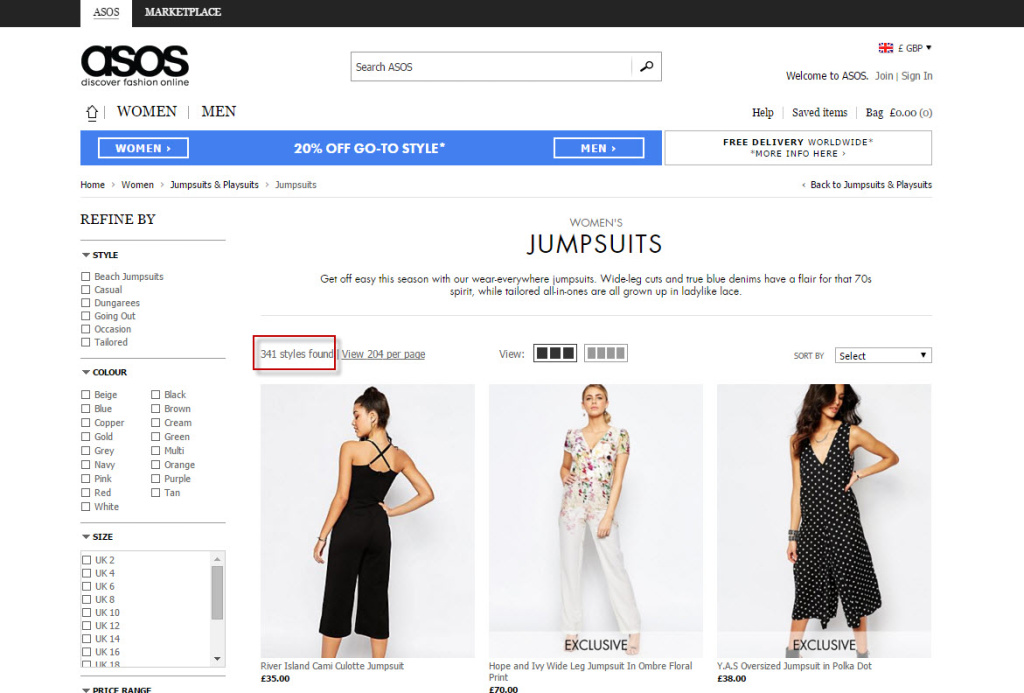
Let’s try to catalogue how many products asos.com have in some of their product categories:
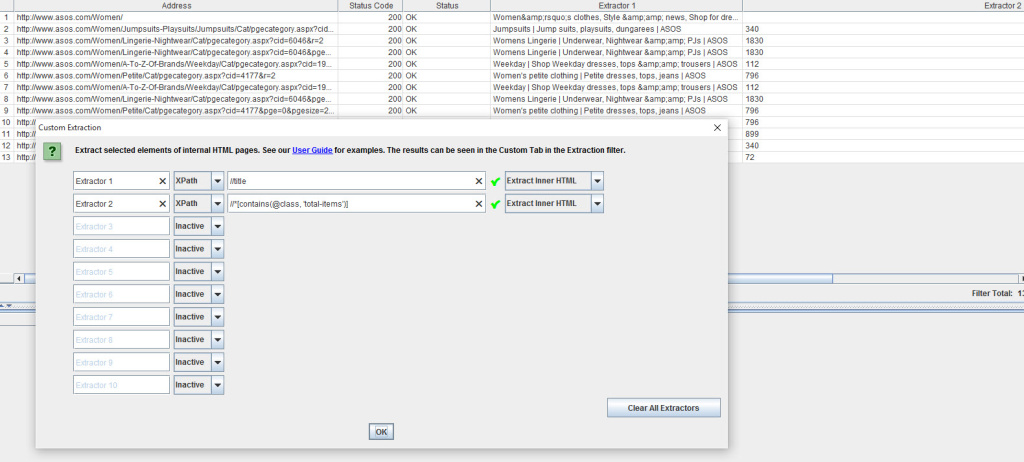
Where://title - extract the contents of the element
//*[contains(@class, 'total-items')] - fetch the contents of any container using class="total-items"
Obviously the data collected would need a tidy up but you see the principles at play. Very simple data extraction, all contained in your trusty desktop crawler.
The only limiting factor to your desktop crawl is allocated memory. Obviously making sure you include / exclude rules are working helps an awful lot, but after that you could just modify the amount of memory in use, if your machine has some spare!
Here’s the config file location to set a larger amount of memory: C:\Program Files (x86)\Screaming Frog SEO Spider
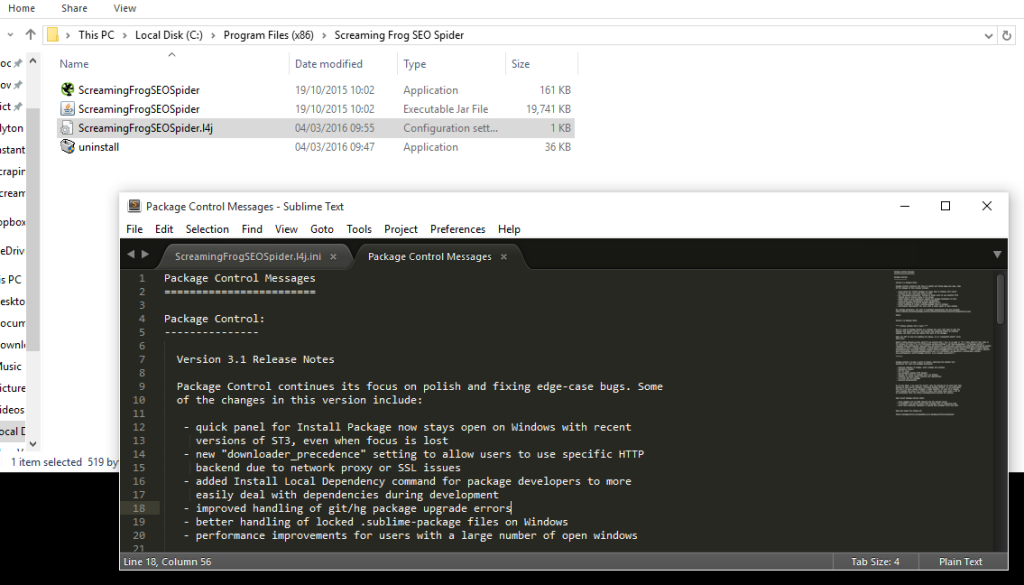
If you do need to increase your memory allocation, you’ll run into issues unless you’re running 64 bit Windows and 64 Bit Java. It’s pretty easy to check and uninstall Java from add/remove programs.
You can also set a reduced crawl limit (play nice and you won’t upset services like cloudflare).
Scraping with Screaming Frog is awesome and a skill well worth learning. Nate Plaunt shared this image of his project which looks like an impressive combination of Regex and XPath:
Google Docs
As fun as using Screaming Frog is for crawling and scraping, sometimes it’s not necessary. Simple is always better, and lots of fun things we’ve made for the community have been based in Google Docs, using the =importXML() function.
Everyone’s written about this feature before, so all I’ll say is that if you want to understand the basic arrangement of an =importXML query in Google Docs, read this post or copy / paste the query from below:=ImportXML([URL],[Xpath])
For a really impressive example of functions like =importXML() in action, take a look at Danny’s Link Reclamation Tool.
Extract JPG Image URLs on Any Topic from Reddit Search
With the basics of scraping more or less covered, what can you actually do with scraping?
As you know we’ve covered a lot of content marketing and ideation concepts on the blog this year. Reddit continues to be such a goldmine for ideas and inspiration. Often we focus on extracting insights and raw ideas, but you could also extract raw materials, too. Like images:

Try this Reddit search: https://www.reddit.com/r/Polaroid/search?q=cat+url%3Ajpg&sort=relevance&t=all
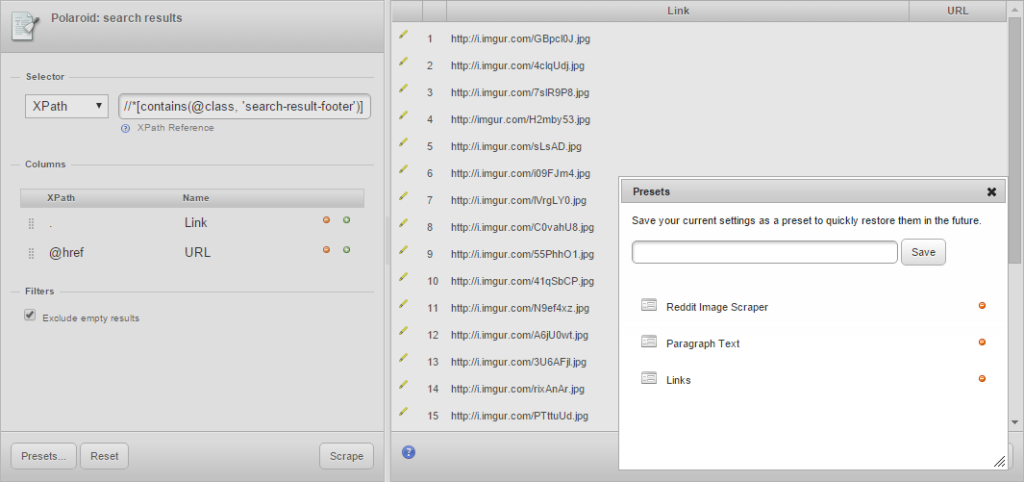
Reddit search has a suite of powerful operators, including a URL: command, which delivers results that contain a string in the shared URL. That’s fabulous for specific file types, like images. Once you’ve found a subject of choice, extract with this XPath://*[contains(@class, 'search-result-footer')]
Pro tip: the scraper extension has presets functionality. You can save your XPath, navigate to a new set of search results and re-run the query without having to re-enter it.
Find Average Salaries for Graduate Jobs Added on Reed
Reed is a huge jobs database in the UK. They have a lot of job ads in lots of different verticals. As we know, the jobs market is of continual interest especially for recent graduates. Content ideas like a comparison of the average salary for a new graduate job in London compared to a different city might make for interesting reading:
Vs.
Now, the data’s not perfect here but it could be cleaned up easily. Look in the HTML:
- £35,000 – £55,000 per annum
That data is easily extracted://li[@class='salary']
I’m not sure of the answer so, if anyone wants to work that out, go ahead!
Compare the Price of Cider at Asda vs Waitrose
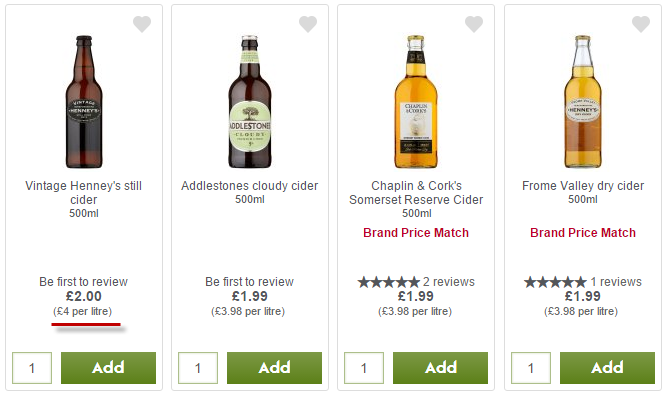
This is a topic close to my heart. In the middle of summer, when you absolutely must have a bottle of cider in your hand, where are you going to head? Waitrose or ASDA?
The XPath://*[contains(@class, 'fine-print')]
vs
The XPath://span[@class='priceInformation']
Other Examples / Inspiration
This whole post was really inspired by this Reddit thread, a contributor had hired someone on Upwork to manually collect the data for the post. The format wasn’t great but the post did exceptionally well.
Similarly, this Buzzfeed post discussing how much your rent has increased since 2007 really shows the power of historic data, something we all have access to in our day-to-day jobs.

Luca
interesting facts. But the Chrome extension doesn’t seem to help with more complex data scraping requirements. What if I want to have job titles, salaries, location, employer and skills wanted all into one document from Indeed?
Richard Baxter
Then you’d need to actually learn xpath: https://builtvisible.com/seo-guide-to-xpath/