Scraping ‘People Also Ask’ boxes for SEO and content research
People Also Ask (PAA) boxes have become an increasingly prevalent SERP feature since their introduction in 2016. In fact, recent data from Mozcast suggests that PAA features on around 30% of the queries they monitor.
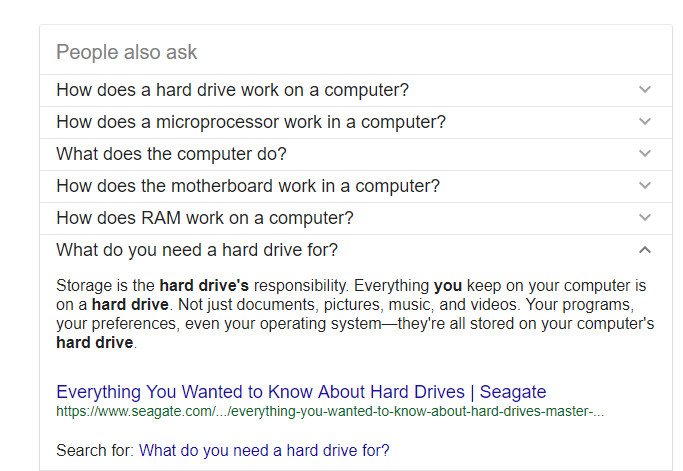
This box, tied to Google’s machine learning algorithms, shows questions related to a user’s initial query. For example, if you input “how does a computer work” in google.co.uk, then you see the following:
Initially, the reception to this feature amongst the SEO community was somewhat muted – perhaps because many saw it as another feature designed to erode organic CTRs – but over the past two years more and more people have identified the value of leveraging this data to supplement their campaigns.
How to use the data
Here are three ways that this newly gotten data can be used:
You can use the questions to build FAQ pages
We have used this tactic on several sites and found that FAQs become an invaluable resource for customers by using PAA data
Using the information to adjust the targeting of pages via page titles and headings, or even the creation of new pages.
Appealing topics related to your keywords can easily be found using PAA data which can help build out the content of your site and give additional information to users.
Using People Also Asked data to find related questions which may trigger featured snippets.
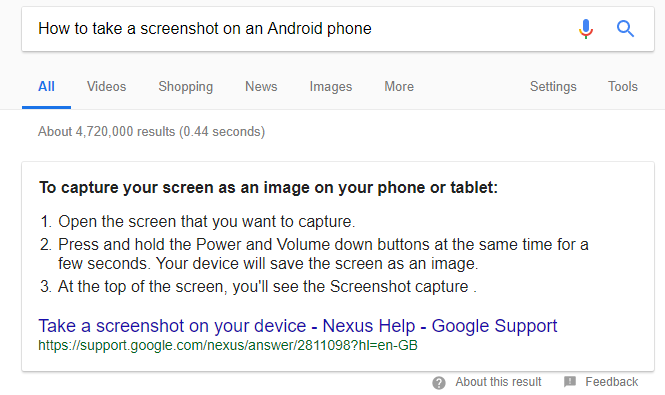
By formatting the answers to these questions as lists or step-by-step guides, it is possible to be featured in snippets. This will enhance your SERP listing and may give your site more prominence and authority in your chosen subject.
Collecting the data
Regardless of how you intend to use the PAA SERP feature, the first step will always be data collection. There are several ways that you can do this.
Manual collection
In scenarios where you’re only looking at a handful of keywords, then manual collection is still a perfectly valid approach – just dump your queries in and see if the feature is triggered. If so, note down the applicable questions that are returned.
Using rank tracking software
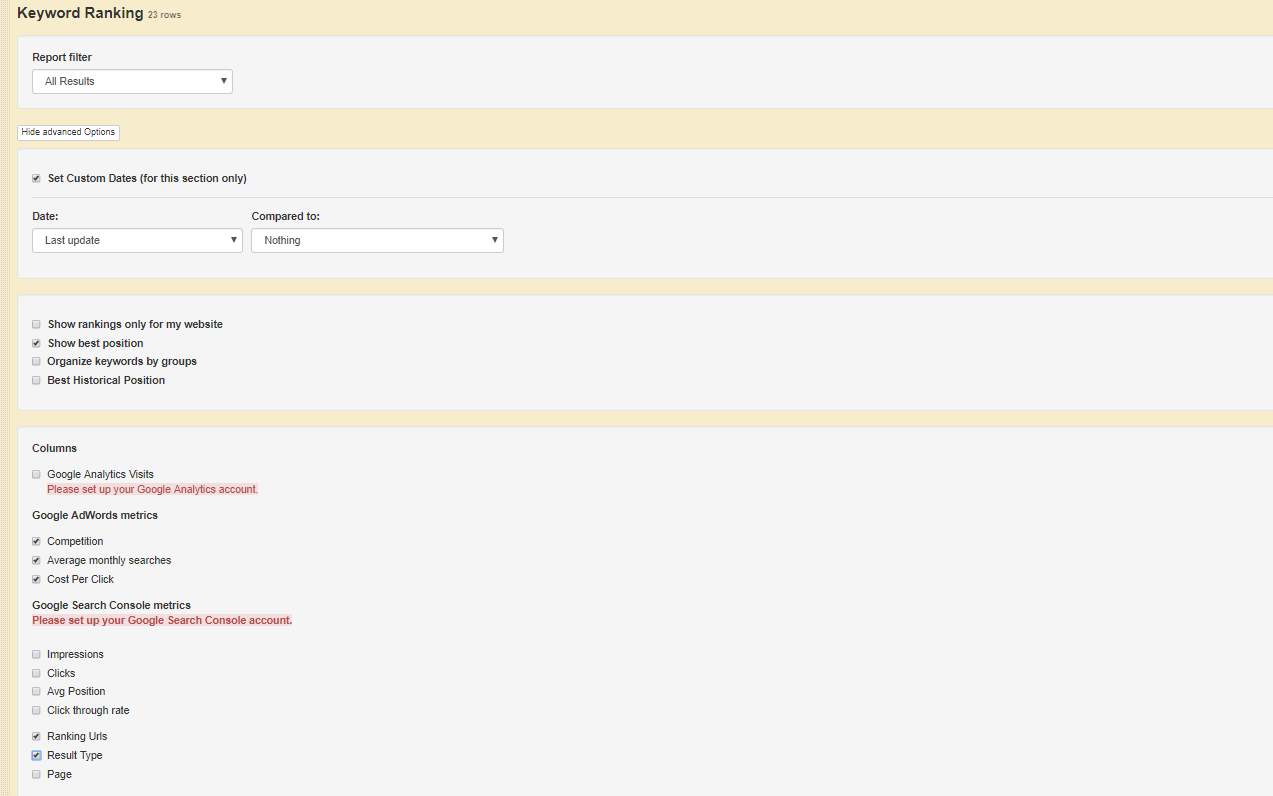
Many rank trackers show which queries generate SERP features. For example, in Moz if you log into an account and navigate to Rankings > SERP Features you can see the queries noted by the dual arrows icon.
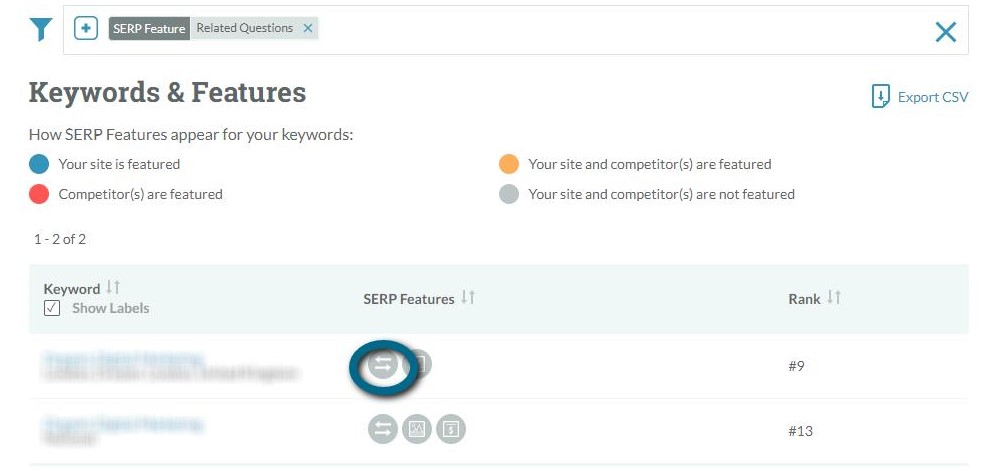
Unfortunately, many of these programmes don’t show the generated questions which means once you have narrowed down your list, you will still have to check them.
Some programmes, such as AWR, will show you the questions in a custom report if you set search engine to ‘Google Universal’ and tick ‘Result type’ in your keyword rankings report. Be aware: it takes up to a day to process four thousand keywords or a week to run 20,000 — and that’s before running the report, which may take another hour!
If you have access to a tool with features similar to the above and have some time to play with, then my recommendation would be to use them. If you don’t have access or time isn’t on your side, then luckily there’s another option: step forward Screaming Frog!
Screaming Frog
One of the best and most underutilised Screaming Frog features is custom extraction. This allows you to take any piece of information from crawlable webpages and add to your Screaming Frog data pull.
At this point, it’s worth highlighting that this technically violates Google’s Terms & Conditions. It’s what your rank tracking software does on a daily or weekly basis, so I’m sure they will forgive us. We’re aiming to improve the quality of our content and websites after all.
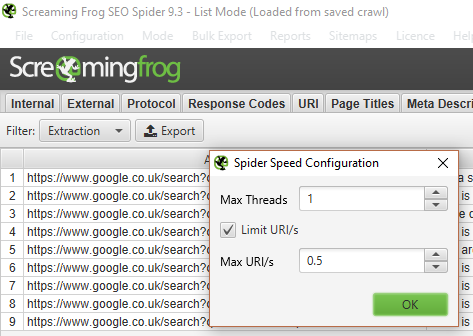
That said, if you use your standard SF settings, you will trigger a captcha very quickly, and the extraction will not work. So, it is crucial that you throttle your speed and, if you want to be cautious, use a VPN or proxy server set to your desired location.
The following settings usually work well and can be adjusted in SF under Configuration > Speed:
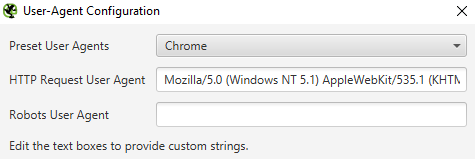
It’s worth changing your user-agent to Chrome via Configuration > User-Agent also:
Next, you’ll need to compile the list of URLs you want to crawl. If you’ve leveraged a ranking tool, you may already know which queries you want to check. If not, don’t worry – you can still plug in thousands of queries without an issue.
We’re going to build our URLs using a spreadsheet program like Excel. We’re looking to create something like this:

In the first column, enter the version of Google you wish to use (e.g. https://www.google.co.uk) appended with the parameter for the search query (/search=?q=).
The second column should contain your search queries. Given that these are going to form part of the URL, you’ll need to replace spaces with the ‘+’ symbol and escape any other special characters (see URL encoding). If you’re happy with your final keyword list, then the ‘Find & Replace’ function can make short work of this job. Alternatively, if you plan to frequently add new keywords to your list and want to avoid the hassle of repeating this task, you can create a working column which dynamically makes the necessary character swaps using the SUBSTITUTE function.
A third column is then required for any other parameters that you need, such as those for location. You can find a list of most of the parameters here (it’s a little out of date, but I have yet to find a better resource).
Finally, the URL components need to be concatenated using =CONCAT(A1:C2), leaving you with a final string.
Example: https://www.google.co.uk/search?q=what+is+amazon+echo&ion=0&num=10
The extraction can’t be run yet, though, as we haven’t told Screaming Frog what to find on the page!
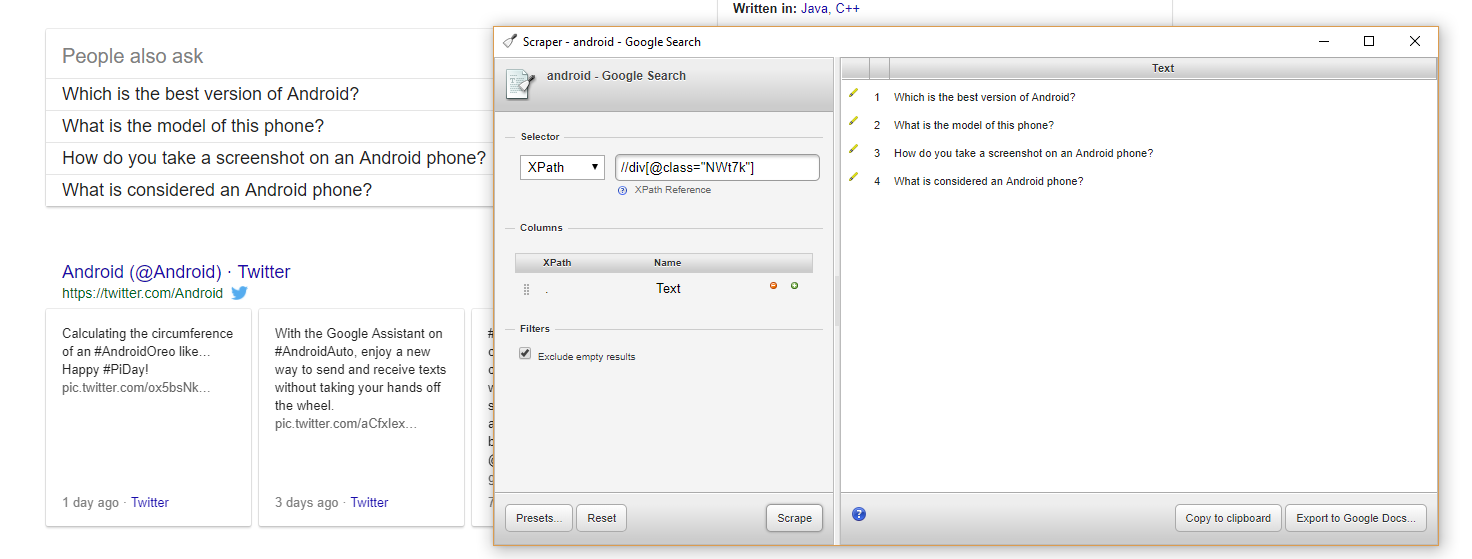
The next thing you need is a little Chrome extension called Scraper. This tool allows you to select data on a webpage and find things that are similar, and – more importantly for our purposes – will attempt to write the XPath string for you.
Once the extension is installed, navigate to a Google SERP that features a ‘People Also Ask’ section. Highlight one of the questions, right-click and select ‘scrape similar’ from the dialogue box. If you are lucky, all the questions are selected on the right-hand side, and the XPath is written for you. This is rarely the case though, in which case you’ll have to look in the source code.
Right-click on one of the questions and go to inspect. This should highlight the question and the relevant div class.
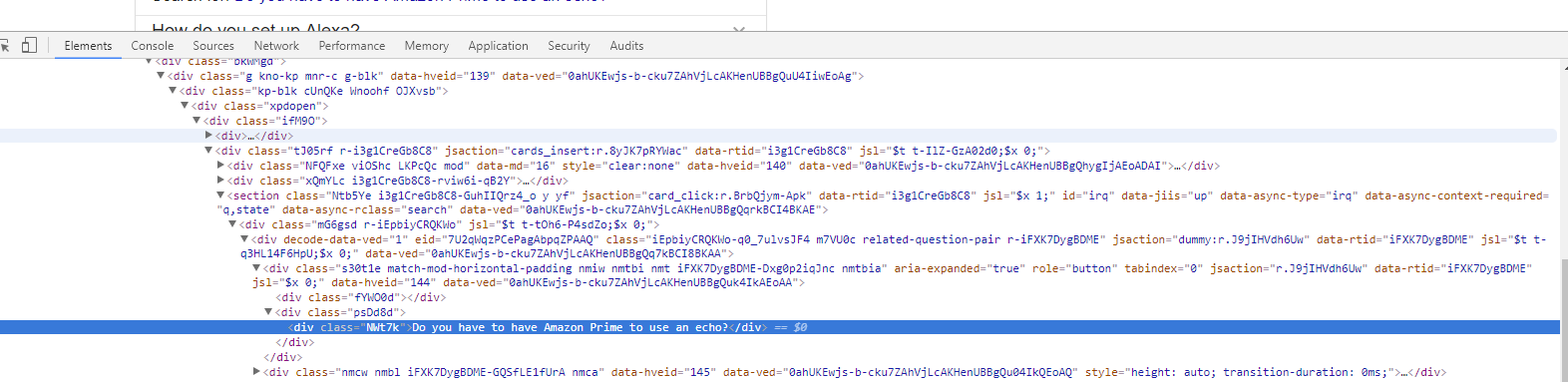
Then go back to your scraper tool and add the string to it, bearing in mind that:
- You typically want to start your XPath with //
- You likely then need the HTML tag (in this case the div)
- Any classes, ids, etc. need to be formatted in square brackets and have an @ symbol at the start. So in this case [@class=”NWt7k”]
This means our full string should be: //div[@class=”NWt7k”]
Add this to the scraper tool and hit ‘Scrape’ to make sure all the text you require is pulled and that no extra information is present. It may be worth doing this on a couple of different SERPs to make sure it works.
The relevant class changes every so often, so if you are using the string in this example and it is not working, then check the DOM node using inspect element and modify as required.
The XPath string then needs adding to Screaming Frog’s Custom Extraction Menu. This can be found in Configuration > Custom > Extraction.
Be sure to name the extraction something sensible so you can easily find it later. On this occasion, we want to make sure ‘Extract Text’ is selected via the drop down on the right-hand side.

You can now import your URL list, run the crawl, and see the returned questions by looking in the ‘custom’ or ‘internal’ reports

By hitting ‘Export’, we can get this valuable data into our spreadsheet program of choice for further analysis!
Other Google data that can be scraped
Similar logic can be applied to pull in data for other Google features, such as AMP results, AdWords Adverts, ‘searches related to…’ and any additional text-based information within the SERPs, or indeed any other information from your websites.
For example, we have used scraped AdWords data to help analyse if PPC campaigns are cannibalising potential SEO traffic. This tactic has proven to be fruitful in providing greater synergy between the two channels, allowing organic traffic to flourish while PPC budgets can be reinvested elsewhere. Ultimately this approach can maximise overall ROI and revenue for the client.

For further information, Screaming Frog offers a guide on web scraping

Paul
Hey!
Great stuff but I have a question – is it possible to scrape more than 4 TOP results?
Christopher Chorley
Cheers David, great read! Keep it up.
Cheers,
Christopher
Kristen Hays
Is it possible to get more than 4?
Leon Abrien
Hey Dave,
Great work, thanks a bunch for sharing the method and the tools used.
I am also curious about the number of results and I’m struggling with the scraping Chrome extension, which keeps returning Error [object Object] instead of the results. I’ve carefully followed the steps enumerated above, to no avail.
Any directions would be very appreciated.
Thanks again.
L
Suresh
Correct, it’s more likely google has closed this scrapping :D We can’t able to find the class of that x-path at all if you observe the source.
George @ Speedflow Bulgaria
Great article!
Gave me a direction to think about and start acting and firstly I’ll get Screaming Frog.
Cheers!
Tito
Can you confirm if this is still working?
I have followed this and got results before. When I tried it today – it’s giving a configuration error. It seems Google has added a whole lot of identifiers and scripts. I suspect that its a bid to stop scrapping.
Dave Elliott
Hi guys,
Have just run a few tests and it is working still.
On my machine the current xpath is:
//div[@class=”match-mod-horizontal-padding b5sWd”].
It might be different for you, but the methodology used in the article is still valid.
Please bear in mind that Google changes the classes quite regularly.
Dave Elliott
I have yet to work out a method to scrape more than 4 per SERP. I will experiment though and see if it is possible.
MikeTek
//div[contains(@id,’eobd_’)]/div pulls more per page in Scraper, but can’t seem to get it working properly in SF.
Matthew Chalk
Hey guys
I’m trying to do this for featured snippets in SF.
Whenever I try to scrape the results, they’re 302’ing in Screaming Frog and returning nothing for my custom Xpath.
Any ideas?
Cheers