Making keyword research commercially relevant
In the last few months I’ve been working on a project to start and incubate a retail website. During the research phase we were faced with some really interesting questions.
Questions that keyword research alone might not provide a huge amount of commercial insight for.
Questions like: “Which brands should we target first?” and if those brands are particularly huge, “which products should we target first for each brand?”.
Remembering that when you’re starting a new retail operation online, one of your biggest costs (except web development, infrastructure and, er, stock) is managing the site content you’re creating. Rewriting tens of thousands of product descriptions (for example) is expensive and time consuming. In what order do you tackle a problem like this?
Fortunately the tools exist to help address precisely those sorts of real world problems.
Adding scraped data to keyword tool outputs
This post looks at using information from sites that already rank in your vertical to mine important data that might aid commercial decision making. Think of it as a more commercially focused form of competitor research with search volumes thrown in.
In this post, the example I’m going to use is online retail orientated but I’m in no doubt this method would work in other types of vertical too. I’m going to have a little fun taking apart some data from food retailer Ocado.com provided by SEMrush and data scraped via Screaming Frog’s Custom Extraction feature.
Start with SEMrush
Did you know you could filter by URL in SEMrush’s Organic Research report?
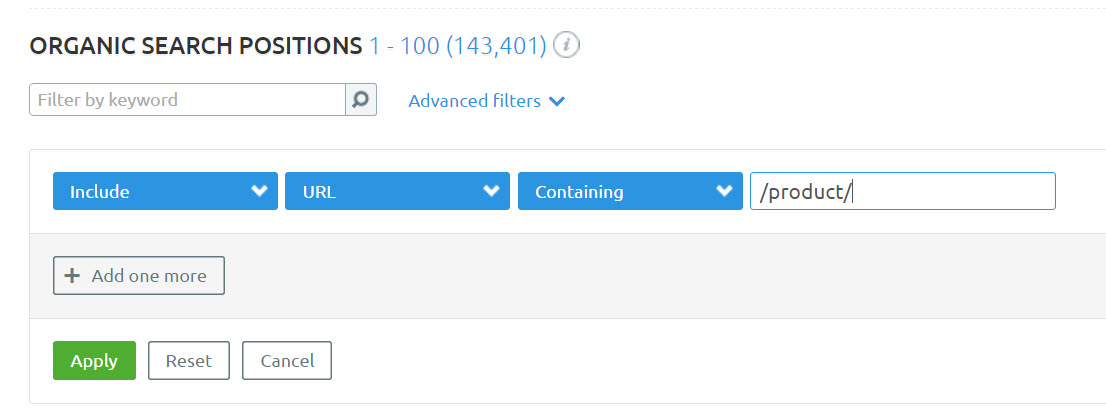
This optional feature allows you to filter data by a particular indicator in the URL, like “/product/” or “/category/” and so on.
While you can filter later down the line in Excel, this filter is handy for large sites as the export limit on a standard SEMrush account is 10,000 rows.
For our research, we’re going to filter for all product URLs on Ocado.com and find out some interesting things about the organic performance of products, and brands on offer by the retailer.
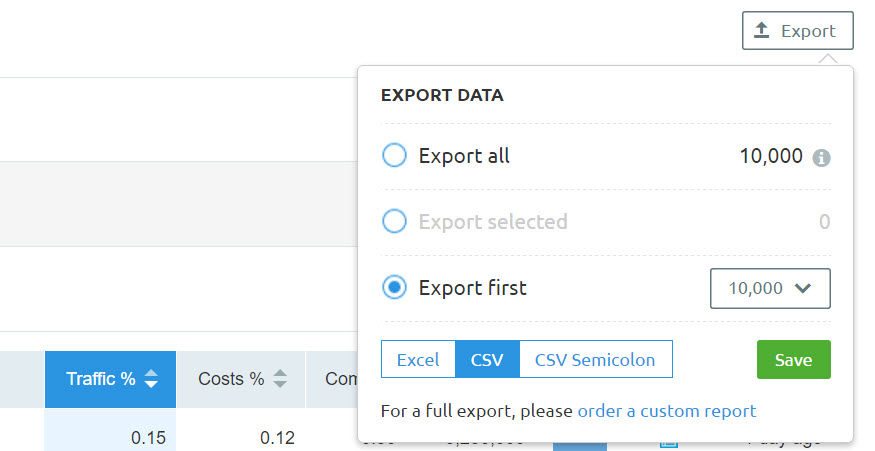
Once you’ve filtered your data, use the “Export” button to download a CSV.
Develop the XPath for useful data points on the page URLs
Most well built sites have a reasonably predictable container structure. A price might be marked up with the CSS class “price”, and so on.
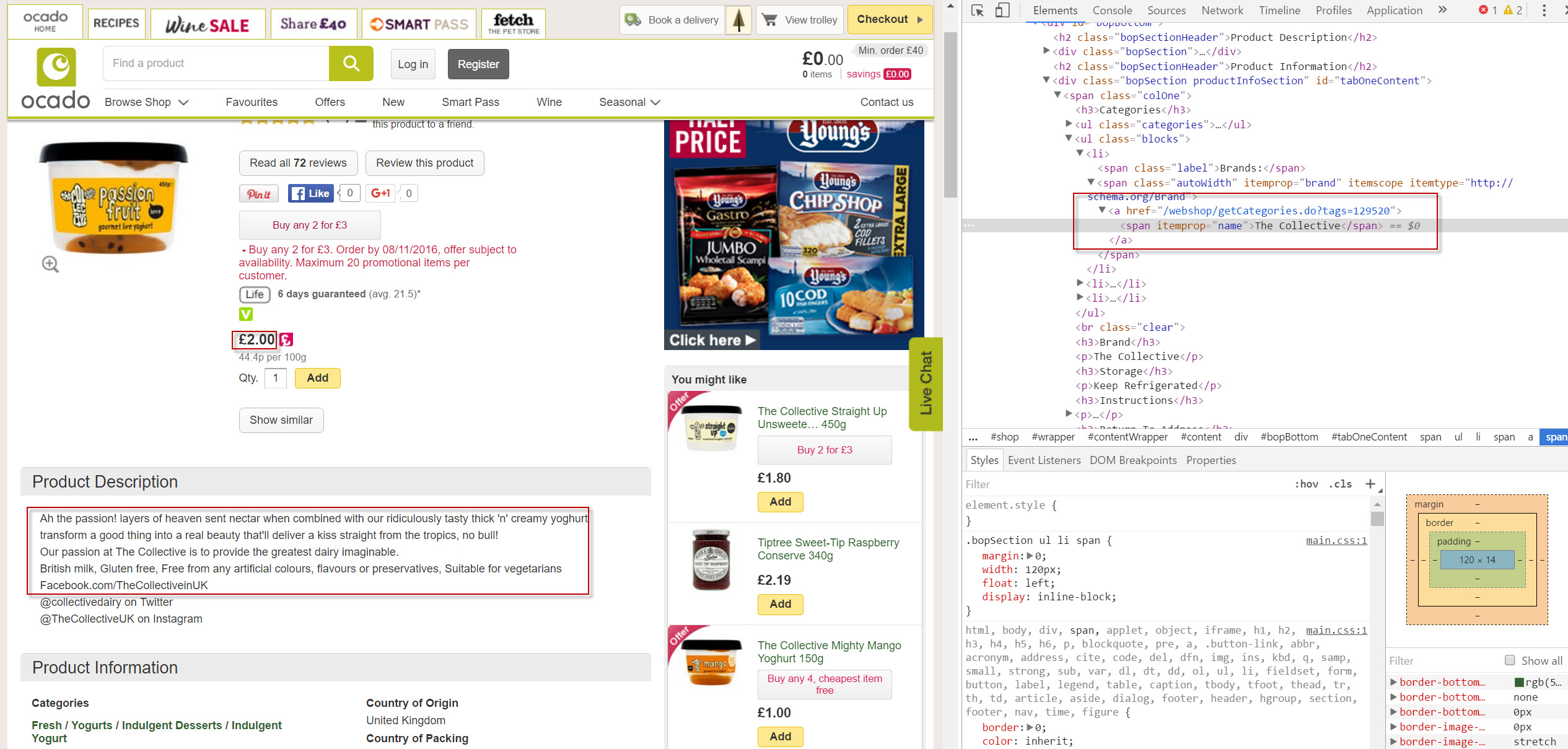
For our example, I’m very interested to see which brands perform well in search for Ocado. I’m also very interested to see which categories might perform well by looking at the cumulative popularity of products that belong to them. Any insight I can glean on their top in-demand products would be a bonus.
So we need to be able to extract the brand, and categories on a product page.
I’ve explained how to do this in this post about scraping data for content ideas and Pete recently explained the basics of XPath on Moz.
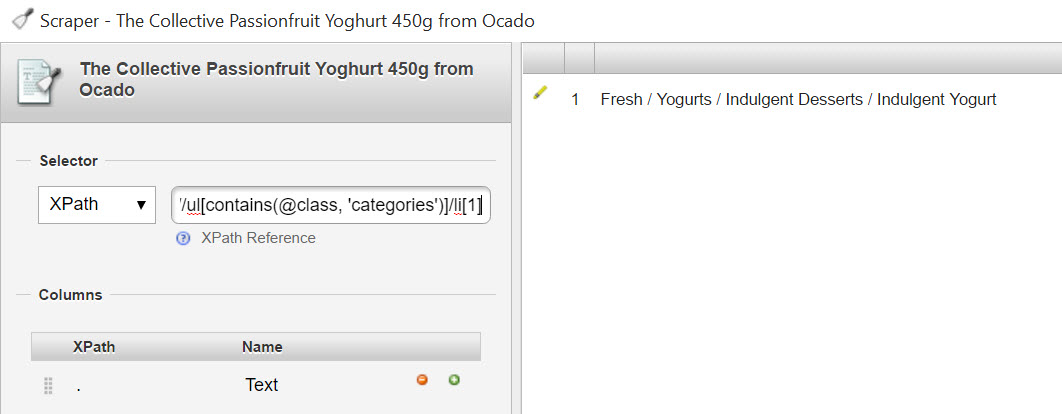
So, to grab the brand name, here’s the Xpath://span[contains(@itemprop, 'brand')]
And to grab the category://ul[contains(@class, 'categories')]/li[1]
Using Scraper for Chrome it’s very easy to test your XPath:
Fire up Screaming Frog
This is my favourite bit. We’re going to extract data about our products by crawling the URLs with Screaming Frog.
Fire up the software and head to configuration > custom > extraction. Add the Xpath you’ve devised:
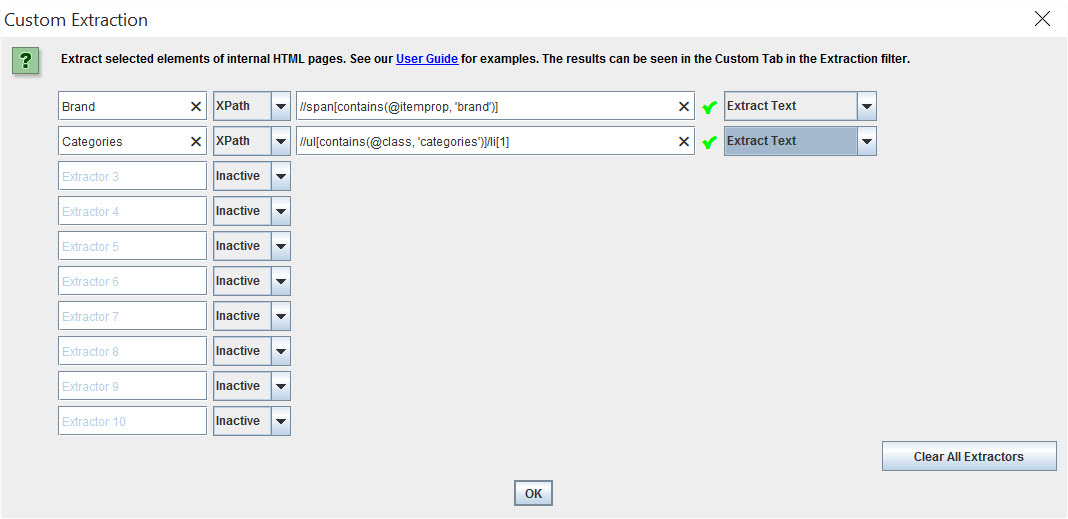
Put Frog in list mode, and paste / upload your URL list, and crawl. Don’t forget to scroll to the right and check everything’s working as planned!
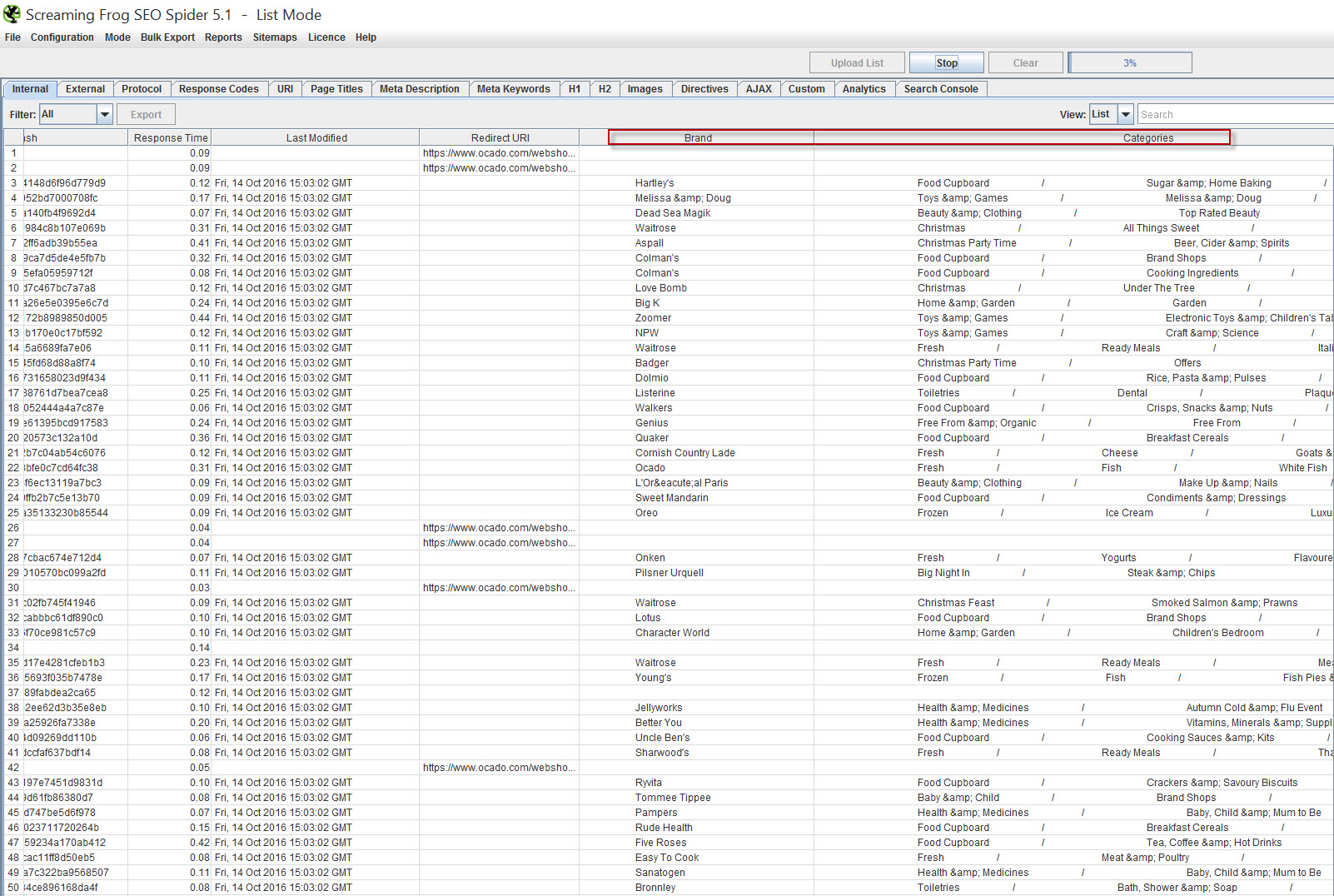
Consolidate the data
With some simple data cleaning using TRIM and SUBSTITUTE, and some consolidation with VLOOKUP, you end up with something like this:
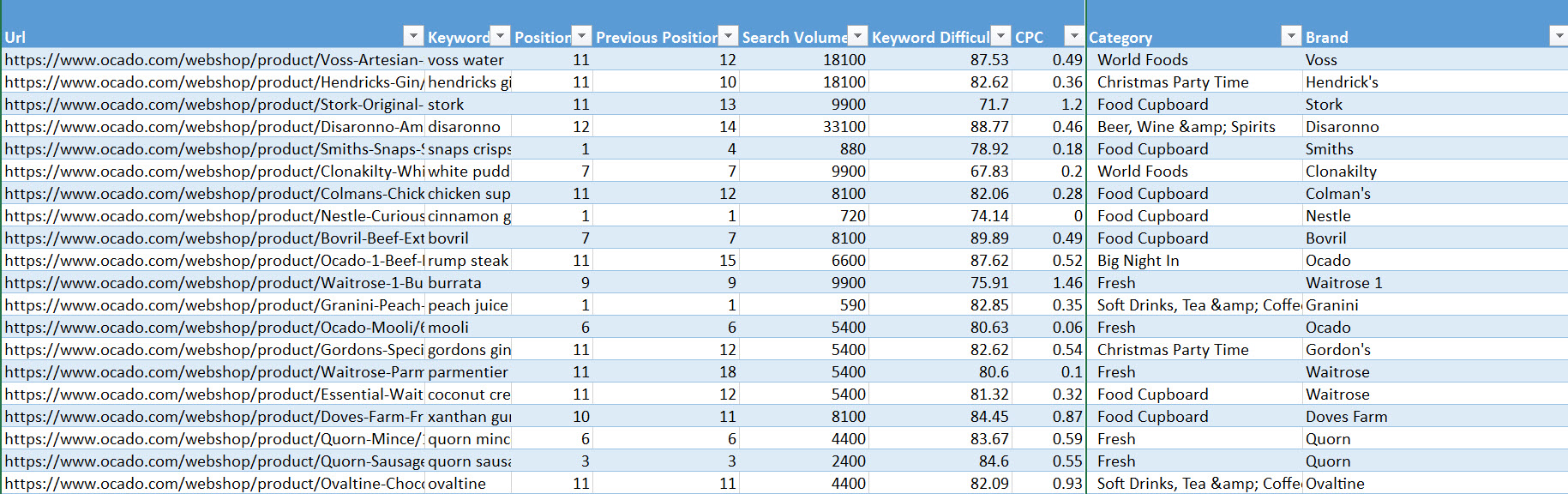
SEMrush data augmented with product brand name and relevant categories. This could have included stock levels, delivery times, price, review count and so on.
An example analysis
With the data and a pivot chart you can carry out some pretty interesting research.
In this view, we sort brands by importance based on the total search volume their individual products are exposed to:
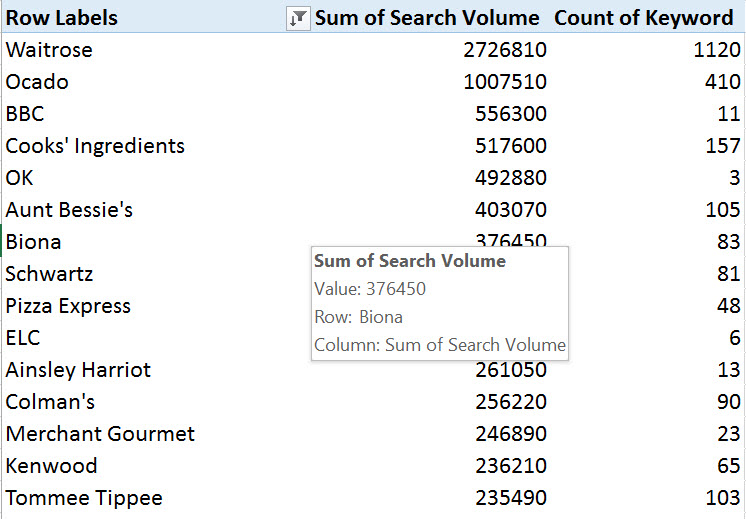
It’s important to understand this is not search volume for the brand term itself! It’s cumulative exposure based on the rankings of all of the product URLs belonging to the brand, based on data we gathered from SEMrush.
In this analysis, we can tell Which categories on the site are most important by sorting using SEMrush’s Traffic % score:
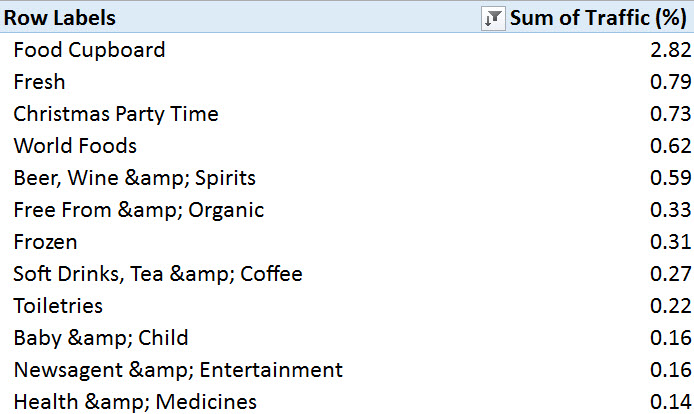
Next, let’s take a look at which products are Ocado’s potential top traffic drivers, sortable by brand or category or both:
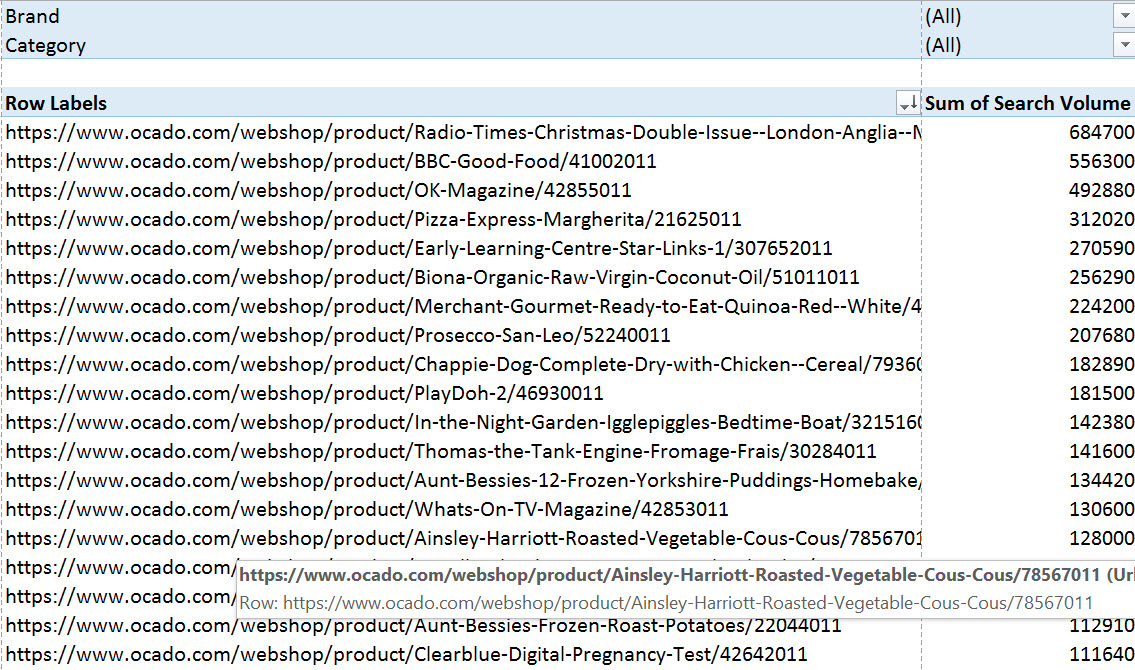
For Ocado, food magazine and recipe books seem to be very popular, one of their top selling products might very well be the Pizza Express Margherita Pizza, Organic Coconut Oil is massive and the Clearblue Pregnancy Test is one of their top 20 products.
*Where a product that appears to have lots of potential isn’t actually performing well, you now have a seriously viable business case to invest in SEO for that product.
Not bad for a few hours work. Imagine what this might look like after a full week of research. You could probably hire us to tell you…
I think this is very powerful
Isn’t the art of research to find creative new ways to answer questions you didn’t know existed? I think this is one of those moments, and I find the options made available by combining classic keyword data techniques with advanced site scraping techniques very exciting.
Procurement and product marketing managers don’t have this kind of data, or, they pay an awful lot more than they need to for it. Marketing Directors would love it. SEO teams have insider data for the performance of their own products but what about the gaps and opportunities that become available by studying a competitor’s strengths? Amazing.
Keyword research is dead, long live competitive intelligence driven keyword research.

Dean
Thanks for the article. Will try to replicate this in SERPstat, I hope it’ll work.
How long did it take for SF to create a list, what if I take a huge website, do I just leave it overnight? Thanks.
Richard Baxter
You can although it crawls pretty quickly. Don’t forget to increase the allocated memory if it’s a really big site…
Cristian
Wow, Amazing research
Joe Robison
Absolutely love this approach. The Screaming Frog extraction is mind blowing, didn’t know that existed.
I’ve been using a competitors-ranking-pages-keywords model as my primary approach, then followed by using their keywords as a seed for more keyword ideas. Glad to see you do this as well.
Definitely think seeing exactly what competitors are ranking for realistically is the best place to start.
Would love to see more ecommerce keyword research posts on here as it’s so time consuming!
Richard Baxter
Thanks Joe! Agreed, I’d love to do a few more posts like this one. Thanks for the feedback.
Stefan
This is brilliant, I never thought it would be so easy to find out the popular items on a website such as ocado, or on any website for that matter, just with the screaming frog software and some tweaking of the xls databases. I have to try this!