Why knowing your website’s indexation status is important
As an SEO specialist or website owner, you want to attract potential users/customers to your site through Google Search. If your website (or part of your website) is not indexed, then you won’t appear in the search results and you’ll forfeit any potential organic traffic, conversions and revenue.
You can also have the opposite problem. If your website creates URLs exponentially (a common issue on ecommerce sites) or allows uncontrolled user-generated content, then Google might be crawling and indexing more than it should. This can quickly lead to enormous inefficiencies that are to the detriment of your core architecture.
Common challenges when gathering Google indexation data
Right now, you can either use Google Search Console or a few third-party solutions to gather indexation data. However, both options come with their own set of drawbacks when it comes to checking indexation data at scale. These generally fall into two groups: accessibility of the data and accuracy of the results.
Google Search Console limitations
Google Search Console (GSC) is an incredibly accurate source when it comes to indexation status data. After all, it has the benefit of a connection to Google’s Indexing System (Caffeine). The new version of GSC brings three super-useful reports that provide indexation status data: the URL Inspector Tool, the Coverage Report and the Sitemaps Report.
However, none of these reports are suitable for large-scale websites because GSC limits the number of URLs you can check per day. I know this because Hamlet Batista built an amazing tool to automate the URL Inspector Tool and I found out about it the hard way!
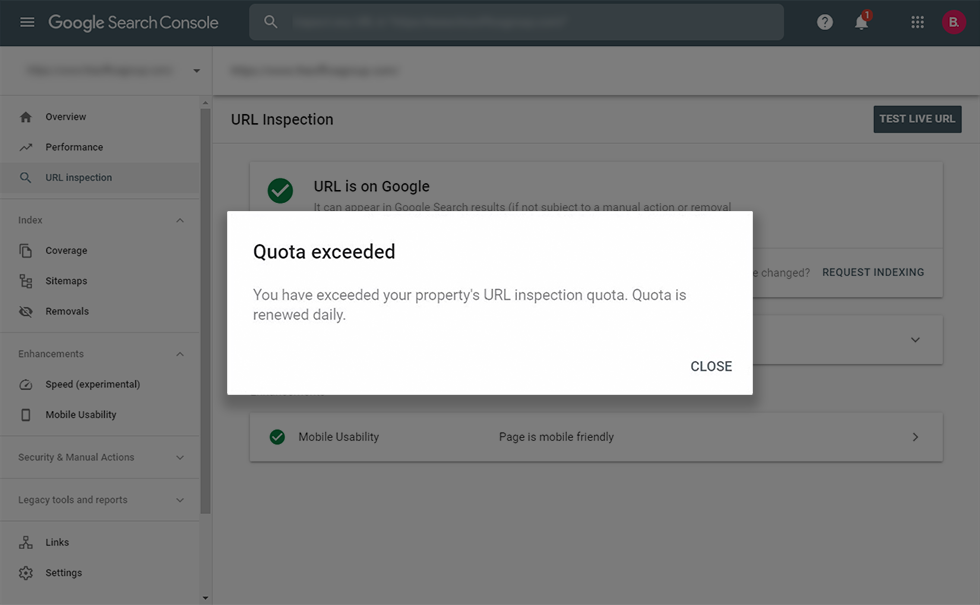
Quota Limit for GSC’s URL Inspector is around 100 URLs/day
In theory, the Coverage Report and the Sitemaps Report could do the trick, but unfortunately Google Search Console limits the export report to 1,000 rows of data and there is currently no API access to extract more.
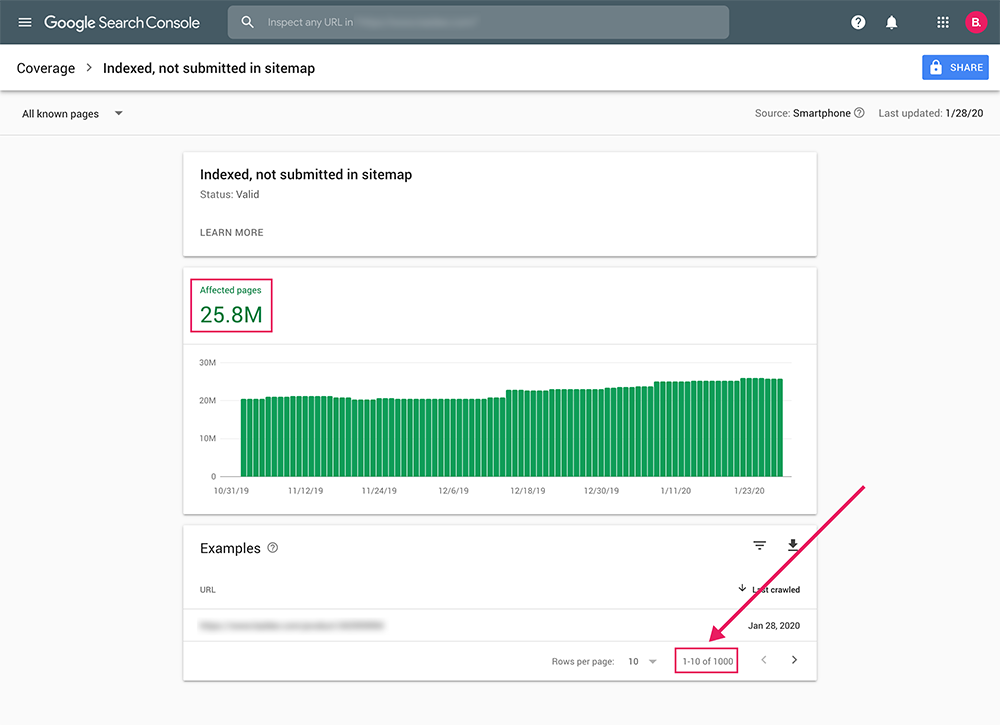
GSC Limits Exports to 1,000 URLs – but I have 25 million pages…
The only way around it would be to divide your whole architecture into XML sitemaps of 1,000 URLs max. Therefore, if you have 100,000 (known/important) URLs, you would need to create 100 XML sitemaps. This would be very hard to manage and is therefore not really an option.
Additionally, this will not give you the indexation data you need about uncontrolled URLs generated via faceted navigation or user-generated content.
URL Profiler limitations
As mentioned in Richard’s post, URL Profiler was a valid option to gather indexation data in some cases. Although we love this tool for other tasks, we realised that it had a lot of issues getting accurate data for “non-clean” URLs.
Some examples include parameterised URLs, URLs with encoded characters (i.e. non-ASCII characters) and symbols, URLs with varied letter casing and URLs with unsafe characters.
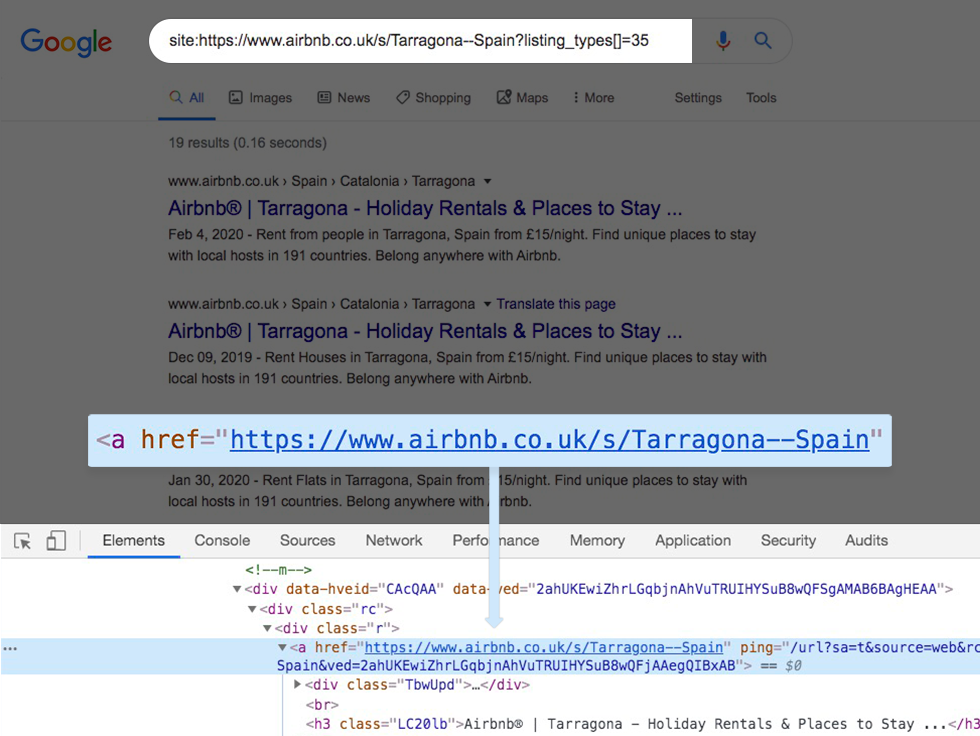
Confusing results using site: operator – Results not showing the requested URL.
I’m yet to find a tool that solves all of these issues – so we built our own.
The solution: Builtvisible’s Indexation Checker
Builtvisible’s Indexation Checker is a script developed internally by our Senior Web Developer Alvaro Fernandez, it was built to deal specifically with the limitations that I’m sure we’re not alone in experiencing.
Our script is able to verify an unlimited number of URLs with any kind of problematic characters: parameters, encoding, reserved characters, unsafe characters, different alphabets – if Google has indexed it, our script will find it.
Here’s how it compares to other solutions:
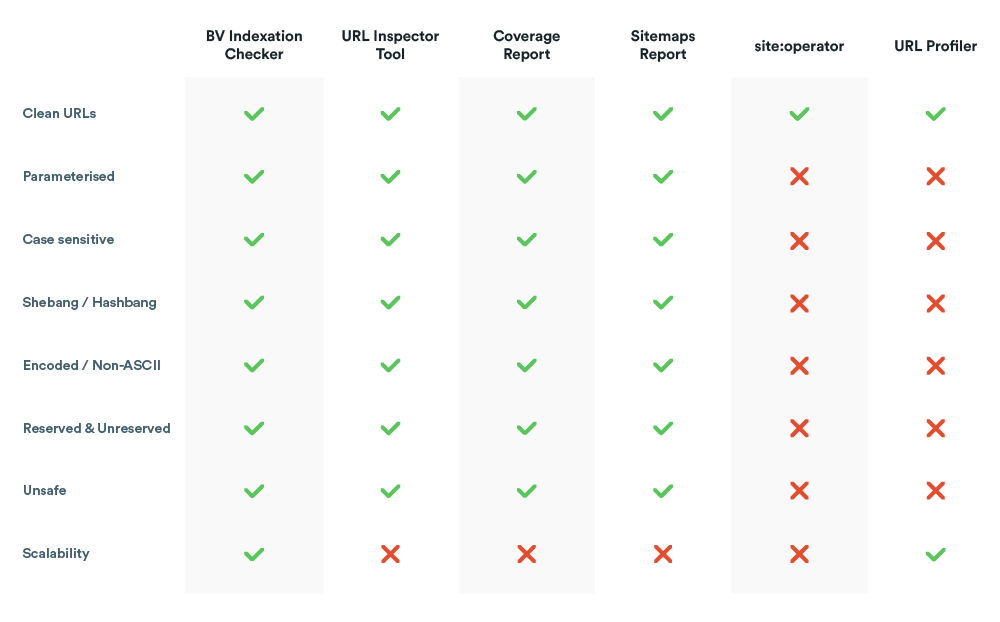
How to set up the script
You’ll need to be confident with the command-line environment on your computer.
First, install the latest version of Node.js on your machine.
Next, download or clone our repository from Github.
git clone https://github.com/alvaro-escalante/google-index-checker.gitGo to the folder you have just downloaded. Open your terminal and install the necessary modules using the following command:
npm installPreviously, if you were to scrape Google SERPs, you would have needed many proxy servers, but thanks to the guys at ScraperAPI that’s no longer an issue. They have thousands of proxies around the globe, so all you have to do is request the desired URL using the same API call format and they’ll do the rotating proxy engineering in the background.
Go to ScraperAPI and create a free account. Don’t worry, there’s no need to add a credit card as they have very generous free tier. The first 1,000 requests per month are completely free, which is more than enough to test our script.
Go to your dashboard and get your API Key.
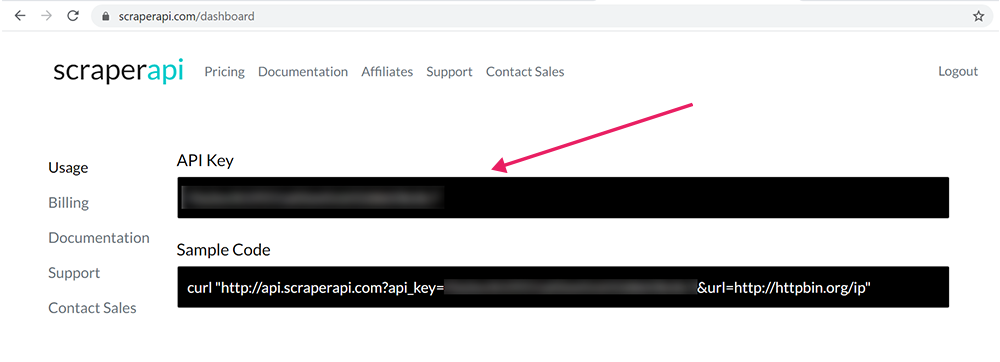
Add your scrapper API key on the APIKEY.js file

Time to run the script
Get the list of URLs that you want to check and save it without headers as a CSV with the name urls.csv. Be sure to use the complete URLs, including protocol. Place the file in the google-index folder.
If you don’t have a list, you can use my Ultimate URLs List. I prepared this when we were developing the script and it includes almost every problematic URL type under the sun, plus a few fake URLs to check that we didn’t have false positives.
Go to your terminal and run the script with the following Node command.
npm startAnd that’s it!
Now you should be able to see the URLs from your CSV popping up in your terminal with the HTTP status code from the API call.
Because we’re using a proxy, you’ll likely get some 500 status code, the script will recycle these errors and re-run the list until all URLs have been checked. ScraperAPI won’t charge credits from your account for these errors.
Once the script has finished, you will get a success message and a new file called “results.csv”. Inside, you’ll find your list of URLs with the indexation status checked.
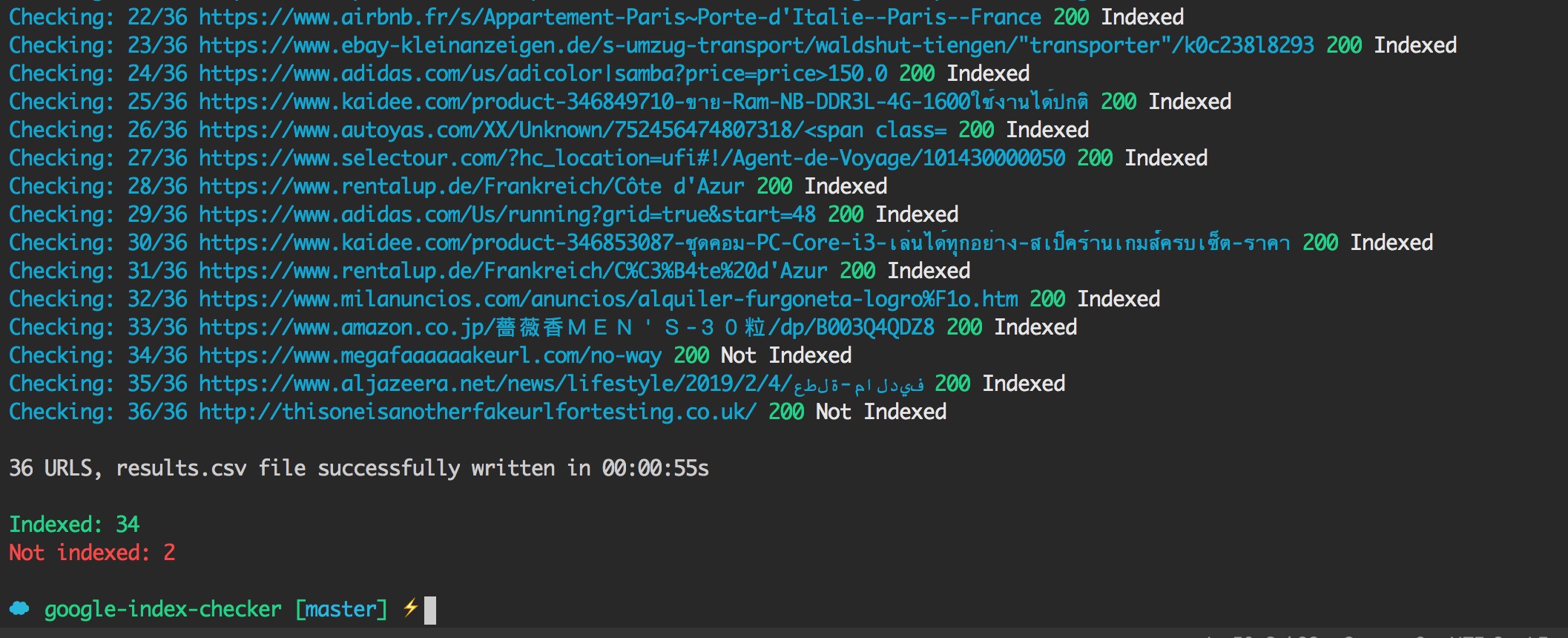
Success! Now is time to check the results
We’ve found that, on average, it takes about an hour to check 2,500 URLs, so if you’re planning to use this script for thousands of URLs bear that in mind.
Final thoughts
The web is filled with weird URLs and, if you’re reading this, the chances are you’re dealing with a mammoth website that has their fair share. Knowing which ones Google has indexed can be a massive pain.
Using our script, you’ll be able to check the indexation status for any type of URL and the size of the list will no longer be a problem – we hope you enjoy it as much as we do!
A few additional concepts
Before I go, I’d like to clarify a few things that I think are necessary.
Firstly, it’s important to make a distinction between Indexing and Serving. We, as users, do not have direct access to the actual Google Index (outside of the data we get from GSC). The second-best option is to therefore understand what Google serves through Google Search.
What this means is that we can be sure that a URL is in Google’s Index if we see it on Google Search, but we cannot be 100% sure that a URL is not in the Index if Google doesn’t serve it through Google Search.
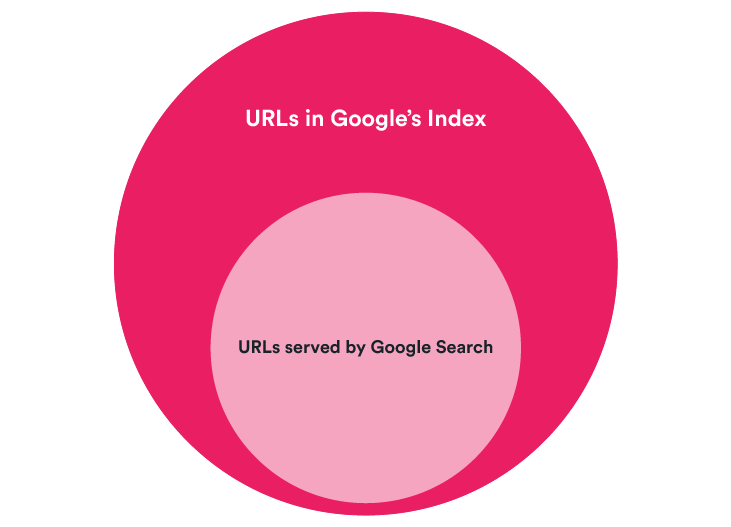
However, in practical terms, if a URL is not served in the SERPs, users cannot see it. Therefore, to us, it would be like it’s not in the Index and we might want to find out why this is the case.
Secondly, having your URL indexed doesn’t mean that the content in your page is indexed. For example, if your site is using a JavaScript framework that renders client-side (CSR), it could be that Google has indexed an empty page. Hence the need to understand if and how Google has rendered your site.
Lastly, a small disclosure: the only way to gather indexation data outside of Google Search Console is by getting information out of Google SERPs. Google does not allow automated queries according to their Terms of Service. So, if you use our script, please use it responsibly.
I hope you’ve enjoyed this article and if you have any thoughts, please consider sharing them!
Want a live demo?
If you’re interested in a step by step tutorial on how to install and run this script from scratch and see a few real case scenarios to use this script please register your interest for a webinar where I’ll be happy to showcase the tool and take any questions.

Manish Singh
This is an amazing :) module to check the Google index.
However, some of the URLs are getting 429 staus code despite being indexed.
Thanks to ScraperAPI for providing 1000 free API requests.
Looking forward to the new version update. :)
Thanks.
Noah Learner
Hi Guys, Killer tool. I had to take a different approach to get it to work though as the NPM install method didn’t work on my mac.
After I ran “npm install” it showed that the semver module was not found. NPM would not allow me to install semver, but when I switched to run “yarn install semver” that worked properly.
I then had to run “yarn start” instead of “npm start” to get it to run smoothly.
Alvaro Fernandez
Hi Noah, we run the script on both Windows and Mac with the latest current version of Node.js – at the time, it was version 12, and we encountered no problems with npm. I developed the app on my Mac, and I always install the current version of Node.js and not the LTS. Maybe that was the issue.
Meagan Morris
I get this error when trying to install the files from the download folder:
npm ERR! code E404
npm ERR! 404 Not Found – GET https://registry.npmjs.org/google-index-checker – Not found
npm ERR! 404
npm ERR! 404 ‘google-index-checker@latest’ is not in the npm registry.
npm ERR! 404 You should bug the author to publish it (or use the name yourself!)
npm ERR! 404
Is there a fix for this? Any guidance is appreciated.
David
Thank you very much! This tool is very useful for me! :)
I’ve made some tests with URLs that are indexed but the tool always returns “200 Not Indexed” status
I’m pretty sure that these URLs are indexed…do you know about something that can be producing this behaviour?
Best regards