What is indexation?
I became interested in collecting data that could help me understand indexation levels on a website.
Actually defining the meaning of indexation, though, is an important first step. Search engines like Google “crawl”, “index” and “rank”. Being crawled doesn’t mean you’re indexed and being indexed doesn’t mean you rank. But questions like, how many pages do I have in the index are important because you can gauge a measure of health of the site.
Let’s say that you checked your server log files (guide to log file analysis here) and found the number of URLs crawled by Googlebot greatly differs from the number of URLs that are indexed. That’s probably not good; in fact we find that it’s usually a detrimental performance issue as your site’s allotted crawl bandwidth is being consumed inefficiently. We find sites that consume a lot of crawl bandwidth but far fewer valuable pages tend to find themselves at risk of Panda penalties.
Put simply, if the number of pages crawled is much higher than the number of pages indexed, you should take a closer look.
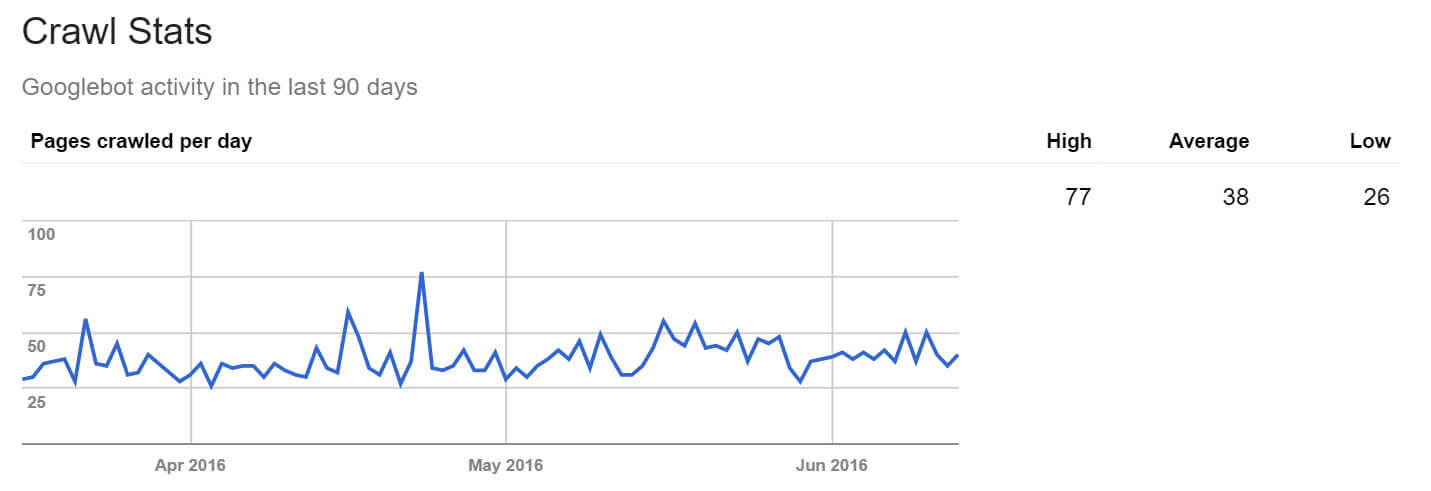
Search Console’s Crawl Stats report will tell you how many pages are crawled on a daily basis, but proper log file analysis will give you the definitive view.
So where can we find better indexation numbers from?
Use URLprofiler and ScreamingFrog
I’m a big fan of the good work of our friends at URLprofiler and ScreamingFrog. Between the two you can build a really comprehensive data set on link profiles, site health and so on. Today we’ll use some crawl data extracted from ScreamingFrog in URLprofiler to see which URLs are indexed.
Assuming you’ve run a Screamingfrog crawl and have a list of URLs to crawl, you’ll need to open up URLprofiler and set up your proxies:
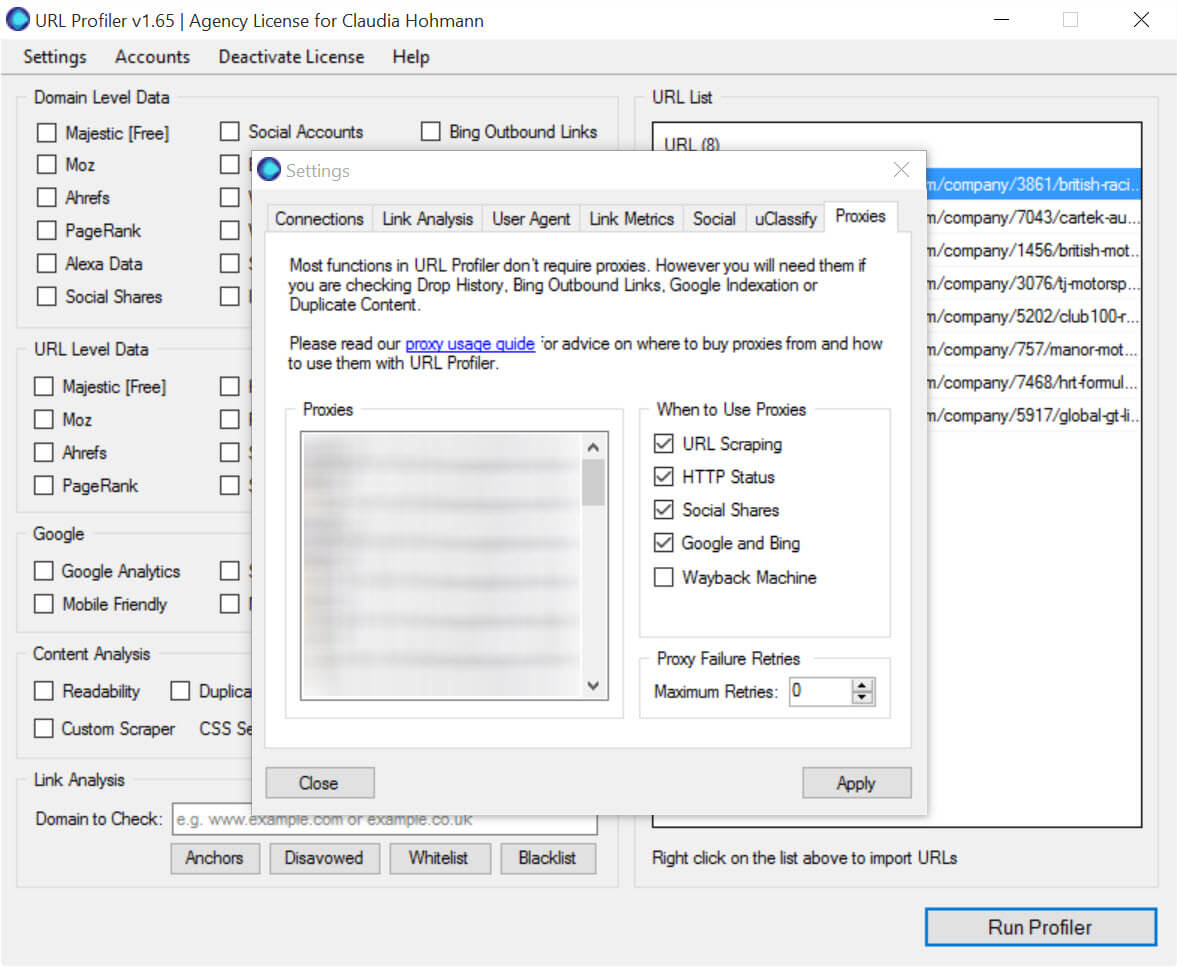
Once that’s done, import your list as usual and run profiler.
This is the type of data you’ll get:

In your export you’ll see the following useful data:
- Google Indexed: “Yes”, “No” or “Alternative URL”
Google Info: Indexed: Only checked if “Yes” in Google Indexed. “Yes”, “No”, “Not Checked” or “Alternative URL”.
- Google Index: Which index the URL is in. “Base”, “Deep” or “None”.
- Google Indexed Alternative URL: The alternative URL is displayed here if one was found in either result.
- Google Cache Date: The last cache date for each URL.
Generally the result you’d expect is Google Indexed: “Yes” with the URL appearing in the base index. Sometimes you’ll get URLs that are not indexed in the base index. URLprofiler will then execute an Info: query, which may indicate the URL is in the Deep index. As far as URLprofiler themselves can tell, URLs in the ‘Deep’ index don’t appear under normal circumstances, aren’t in the base index and will never get you any traffic.
If you’re seeing lots of alternate URLs you may have an issue with canonicalisation in your URL structure. Take this query as an example:
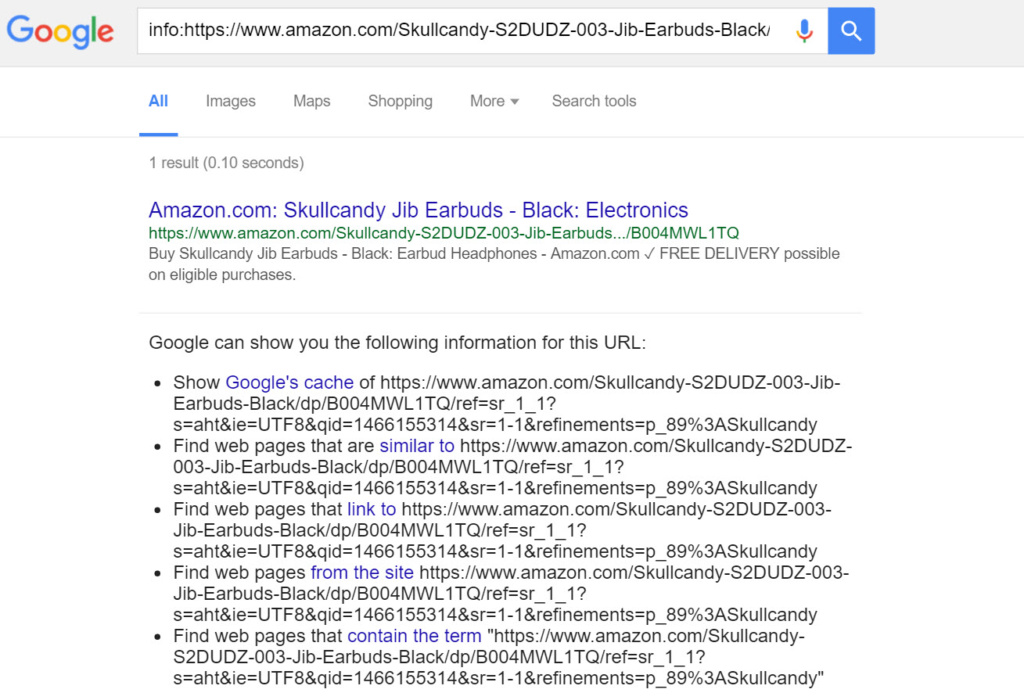
The info: query looks like this:
info:https://www.amazon.com/Skullcandy-S2DUDZ-003-Jib-Earbuds-Black/dp/B004MWL1TQ/ref=sr_1_1?s=aht&ie=UTF8&qid=1466155314&sr=1-1&refinements=p_89%3ASkullcandy
And yields this alternate, canonical URL:
https://www.amazon.com/Skullcandy-S2DUDZ-003-Jib-Earbuds-Black/dp/B004MWL1TQ
A real world example of this situation might be that the URLs you’ve discovered in your internal links via your Screamingfrog crawl don’t match the indexed, canonical version of the URL. Or that your sitemap URLs don’t agree with the canonical.
Next steps
With a complete view on a. how many pages your site generates and b. how many of those are indexed, you’ve got a great data set to base your own technical changes on. Typically, issues such as URLs appearing as alternates or pages banished from the base index will be caused by issues in internal linking, crawl bandwidth optimisation problems like soft 404 pages, unintentional internal 301 redirects, server errors and duplicate content issues via query parameters.
I’d recommend combining this data with your log file audit data for maximum use.

Modi
Nice post.
Re scraping cached dates Scrapebox does a pretty good job. Combining scrapebox and Xenu one can easily figure out what the indexation rate is in each level as Xenu does split sites per level.
Also, using Scrapebox again it’s very easy to detect which URLs have been indexed as not all URLs detected by Xenu may be indexed.
Adam Bradley
Great post, I started playing with the info: and the related: search modifiers. This got me thinking, have you seen the related: query show pages from another domain before? That would be helpful in identifying sites with very similar content and potential areas of duplicate content concerns.