
The problem:
My client uses beautiful images with embedded text as headers for their categories and subcategories. My client doesn’t use that text on page. I want them to, but it’s going to take a lot of work. Things that take a lot of work tend not to get done. I want my client to get this done, because it will make them more money.
Once you’ve been rebuffed with “it’s in the pipeline”, or “progress is slow” in following up recommendations, then sending over something that will save them time (like the following) can be very valuable.
So how do we get hold of this text without sitting through it ourselves (or making our client do it)?
Enter Optical Character Recognition (OCR).
If you’ve ever used Captcha Breaking software (tut-tut), you’ll know that purposefully obfuscated text can be solved by machines. When text is not purposefully obfuscated, recognition becomes remarkably more accurate. When the text in the image is a legible font on a standard background, it becomes much easier.
Fictional example:

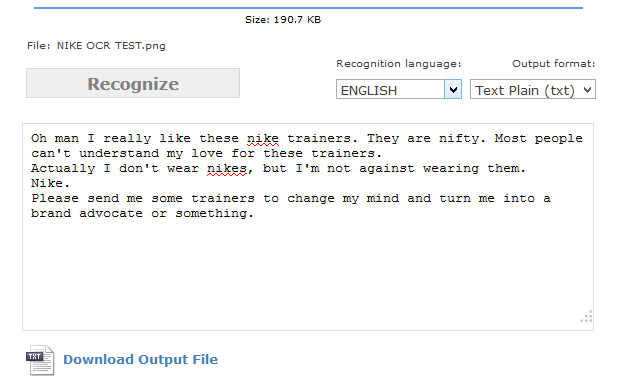
Looks great, for a cherry-picked example.
Actual live examples:

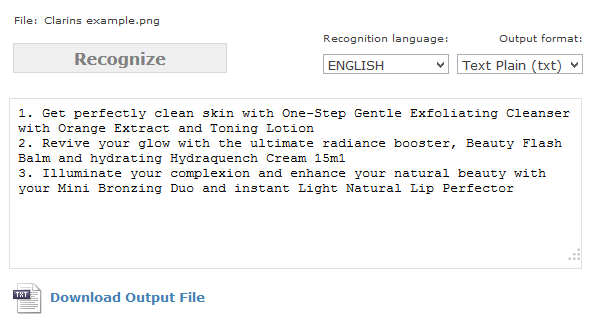

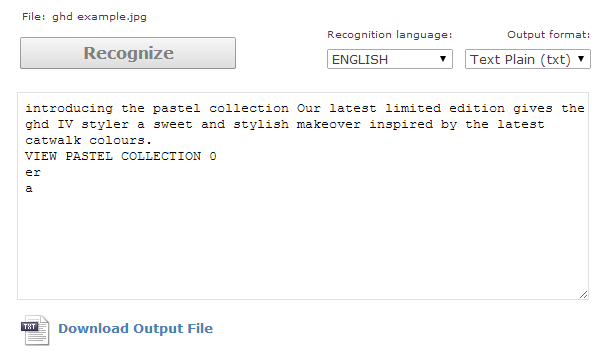
A few extra characters from a mistaken button isn’t a bad result at all. You can see in these cases that any stylistic emphasis isn’t carried over, which is unfortunate, but a limit of the output format. All the examples in this article were made using OnlineOCR.net, which has been good enough for my purposes.
They let you batch process images and accept command line style arguments via emailing or uploading images/zip files:

I’ve also been using a program called FreeOCR, though I’ve found the email setup from OnlineOCR.net to be more convenient and accurate.
Essentially, you’ll be in luck if the images you want to batch have simple backgrounds, or a high contrast between the foreground and the background. Anything more complex, and you’re going to need more time doing the corrections. You’re going to struggle getting any meaningful output from anything like this:

The process:
- Identify all images that fit the imagetype of your recommendation. This can typically be done by URL structure of file name if there’s a useful identification string like “landing-banner”, or “brandhero”. Since this will tend to be a recommendation regarding the same kind of image (e.g. category and subcategory header image), then filtering a crawl by image dimensions will usually get you what you need.
- If you want to be more accurate, crop the images to contain only the text you need transcribed. If the image contains additional not-really-text text (like a product label), you’ll not want this throwing off the output.
- Batch run these images through text recognition.
- Have a human quality-check the OCR output against the originals to spot any spelling discrepancies.
- Create a new CSS template for the text.
- Input the text into these templates on the live site. Tweak as required.
Please think of this not at an individual level, but as a batched task. For a single image this does not save time, but if you have 200 category header images to work through it’s lifesaving.
In this case the recommendation for our client “get that text out of images and onto the page” didn’t actually change, but the fact they were able to implement it faster was very valuable. The design team handling the work were happier since they didn’t have to slog through the transcriptions stage quite so much. Their manager was happier since the task took them less time than anticipated, and freed them up to do actual design work. We were happy because the category and subcategory rankings improved.
Other options:
I know there’s a case to be made for using Mechanical Turk or Elance/Odesk to perform this sort of transcription task, but as automation is easy (you need to files in an OCR ready format before you send them to freelancers anyway) you may want to instead have them approve or amend the OCR transcribed text, instead of transcribe it from scratch.
Although Google drive can automatically convert image content into text, I’ve only had mixed results so far, which is a shame given the ease of use.
Here’s the setting.
Essentially I thought this idea was worth sharing: it made one of my clients happier and got my recommendations implemented faster. If you know a better/more accurate way to batch OCR work, let me know in the comments below.
