Cut? Prune? Include? Why?
Pruning is the removal of keywords from the research docs you present to clients, track rankings for, provide for mapping to URLs for and so on.
The more keyword research documents I do, the more I appreciate the importance of refining datasets. Less is more.
Scenarios where pruning your list is a must:
- Accurate forecasting
- Analysing commercial market share (something opportunity sizing will do)
- Product/offering has changed or is limited vs. competitors
Quick-win ways to prune big keyword lists
Please note, I’m not going to talk about how to undertake keyword research. For that, check out Richard’s post on keyword research based on your competitors’ sites.
The bulk of these tips assume you have a large CSV sitting there that needs cutting down.
Use negative categorisation to cut irrelevant and incorrectly added keywords in your data set
This process can help to:
- Categorise and remove competitor brand keywords
- Cut irrelevant keyword phrases that contain your target market, but are the wrong intent
Most keyword research processes will include categorisation of keywords based on product sets, variations of a head term, parts of the site they are targeted for, etc.
However, categorisation can also be used to cut out the erroneous keywords in a dataset. I’d recommend doing this at scale using an array formula or similar intelligent keyword search function.
Categorising keywords at scale will require some set-up but will save you so much time. Richard wrote about how to do this at scale some years ago. It’s a good write up on the approach to automating categorisation using an array formula – a method we still use today.
As an example, if your main product or service is ‘travel insurance’ you may see many multi-intent ‘travel’ and ‘holiday’ keywords appear in your research dataset. If I’m building a commercial keyword-led insight sheet, broad keywords more suited to travel providers need to go.
I have three categories below, covering branded keywords (own brand and competitors in this case) and keywords that cover travel terms (like holiday, travel, trip, etc.) and finally ‘insurance’ (which includes keywords such as insurance, cover and plan).
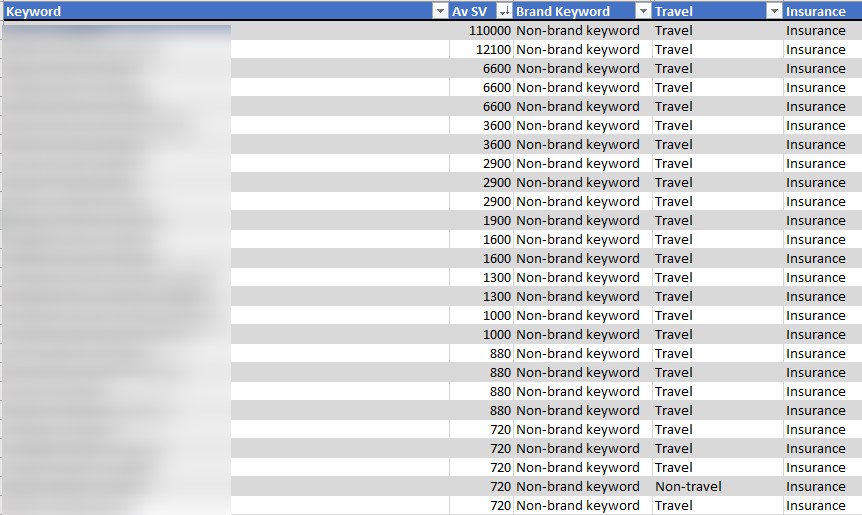
Filtering to exclude insurance and brand keywords, but including ‘travel’ terms helps me isolate and delete irrelevant keywords en masse.
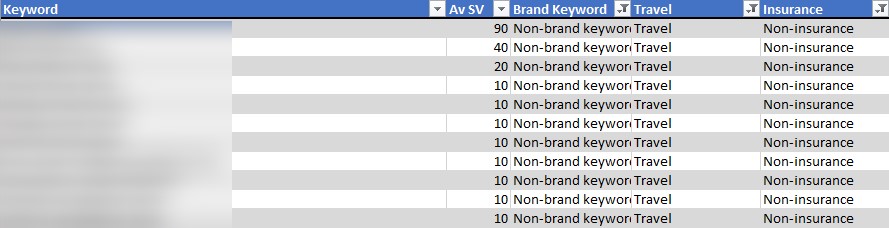
You can do this individually with text level filters using Excel’s custom auto filter if you so choose. However, that will only give you two conditions, whereas this system is only limited by the total number of categories.
Also, if you update your research further down the line, this process will automate your pruning once more.
Quick tip:
One quick way to nab competitors to add to your exclude category is if you have an ‘all sites’ ranking report for your keyword set (like AWR’s Topsites Master report). You can apply a formula to the domain:
=IF(ISNUMBER(FIND(“www.”,A1)),MID(A1,FIND(“www.”,A1)+4,FIND(“/”,A1,9)-FIND(“www.”,A1)-4),MID(A1,FIND(“//”,A1)+2,FIND(“/”,A1,9)-FIND(“//”,A1)-2))
Assuming the ranking URL is in A1, you can then remove the TLD by using the text to columns function in Excel, delimited with a full-stop (.).
Finally, replace any dashes with spaces using find and replace in Excel. That should give you a quick list of domain/brand names to exclude from your list.
Justify or prune based on historical CTR/performance
Recently the Google sheets SC API switched to the new version of Search Console, allowing marketers to look back at 16 months of data.
- Install the Search Analytics for Google Sheets Chrome plugin for easy access to the API
- Create a new sheet, navigate to ‘add ons’ and open the sidebar
- Select a date range and group by ‘query’
- Request data (and wait)
You can do this from the Search Console dashboard itself, but if you want more than 1,000 sampled keywords, use the API.
Quick tip:
Bad keywords will show a poor ratio between high impressions, low click-through rate and a decent page one average position.
For example, I once had a client who ranked on page one (position 7 consistently, but sometimes position 4) for “how old is the queen”. The ranking URL? An office on a street with ‘old’ and ‘queen’ in the name. This page received many clicks, but naturally, the CTR was terrible and it never converted.
Shockingly, this wasn’t that long ago.
Recently, using this method, I found that a client had been receiving clicks for keywords in a research document, with decent rankings on page one.

You just need to take one glance at the SERP to know this keyword has no place in a research document, however you can do this at scale with the Search Analytics for Google Sheets plugin. Filter to page one positions, sort CTR smallest to largest and look at the significant impression keywords.
Fuzzy lookups to justify or prune keywords grouped by Google Ads Keyword Planner
Fuzzy lookups are great.
Fuzzy lookups are valuable for keyword research documents if your data source is from scraping ‘people also ask’ which you can’t justify with keyword planner. Similarly, for data relevant for content research purposes, you will find it is often grouped and not return any volume in Keyword Planner (which has its flaws).
This March, Marco Bonomo wrote about how to use them for site migrations over on Search Engine Watch and it proved quite popular on Twitter (nice one Marco). Additionally, read Richard’s use case matching up and two sets of product data.
This method will help to justify a variation or long tail variants and then prune out irrelevant keywords.
I’d recommend completing fuzzy lookups at the last stage of your research to ensure the keywords that do have search volume are as valid as possible, as this method will compare your search volume terms against those with no volume.
Quick tip:
If you are using this dataset for a landscape-level piece of analysis, then you should avoid attributing search volume across keywords – as keywords are grouped by Google Ads Keyword Planner their search volumes are also ‘grouped’ into that bucket. Therefore, if you double up using Fuzzy Lookup attribution of volume, you’re artificially inflating the volume driven by that keyword.
Back to the fuzzy lookup plugin, (available here for Excel). The set-up takes five minutes. Once you’re set-up, what you want to do is take your (0) volume keywords and add them to a separate table from your main set of keywords that have volume.
- Create two tables and then open the fuzzy lookup tab in Excel (typically next to ‘Help’).
As an extra time-saving step, cut down to just the information you want to justify the keyword. It is laborious to uncheck more than a few columns from the output columns system later.
- Ensure you are on a blank sheet otherwise, it will start overwriting your data.
Name your data tables if you plan on running more than one fuzzy lookup in the same workbook.
- Select the data columns you want to fuzzy lookup, below you see both columns are named ‘Keyword’. If you then click the button between the column choices, this will output that match to the Match columns field.
You may have more than one matching column if you wish for the system to compare more than one like for like dataset for similarity.
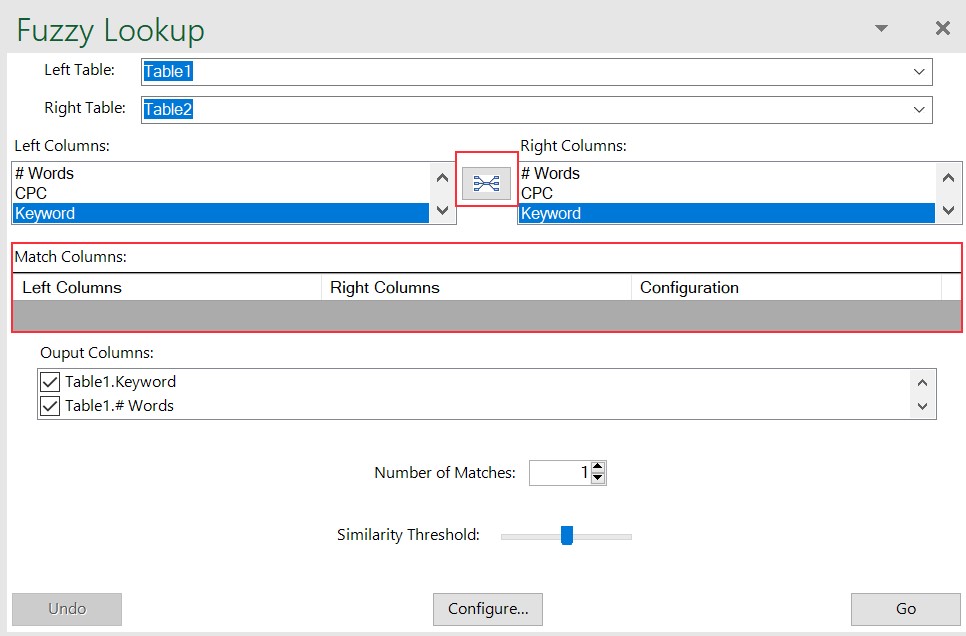
- Choose your number of matches (it will output more than one similar set of keywords) and similarity threshold. Similarity threshold, as a broad rule, should be within 0.5-0.6.
There is much more customisation to uncover in the Microsoft documentation, but for now, let’s keep things simple and leave configuration.
Your goal is output to a dataset like the below screenshot (in this case I dropped the threshold to 0.42). If any keywords show up as blank with 0 similarity, then those are your candidates for pruning from your dataset.
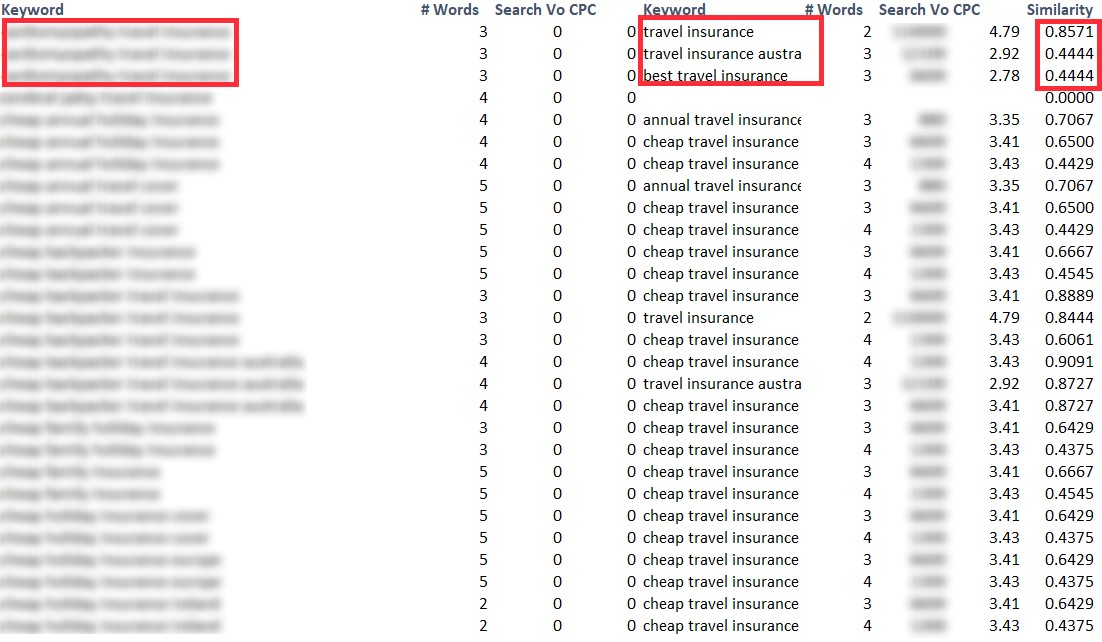
Broadly, if you’re scoring below 0.5 on the scale compared to any keywords in your dataset, then it’s likely that they are dissimilar and therefore worth pruning. Some manual sense checking will be required.
More reading on Fuzzy Lookups here, including set-up process and why they’re useful for those scenarios when you’re missing exact matches between data tables.
Pruning keyword lists by mid to long-term strategic goals
Perfection is achieved, not when there is nothing more to add, but when there is nothing left to take away
Antoine de Saint-Exupery
As a final thought, this quote is a bit lofty – however, the sentiment of having “nothing left to take away” is directly relatable to keyword targeting.
For example, it applies in the following scenarios:
- The gap between user intent and is too significant of a gap to cross, yet historically the brand used to rank position 1
- Keyword is attracting the ‘wrong’ type of traffic – i.e. traffic that converts, but is not business-level profitable
- Overly aggressive SERP features mean that even the top three are significantly far below the fold
The ideal outcome is to pivot away from those keywords. A great place to start doing that is pruning them out of the list. I’d advise starting with the approaches above as a starting point for ‘quick’ ways to prune your lists, yet I know that manually checking will always be a requirement.
Let me know if you have any quick win ways to further prune keyword sets in the comments below!
