Screaming Frog Custom Extraction & LEN + SUBSTITUTE + UPPER in Excel
This process was built with more than a little help from my colleagues (thanks Tom, Philip & Tony), utilising:
- Screaming Frog’s custom extraction tool (available to paid users) to extract the relevant page content
- A combination of LEN + SUBSTITUTE functions in Excel (with a side of UPPER) to count the keyword(s). Courtesy of Dave at Exceljet
Depending on the templates present on the site you are analysing, this process has quite a simple set-up but can save you loads of time counting keywords within the copy relevant to the user and search engine robots.
With this process, you can aim to exclude page elements like common navigation anchor text links and potentially duplicate sections of copy that sit across all pages.
Before we start, you’ll need:
- Keyword mapping (keywords mapped per URL on your site, preferably in the same row as the relevant URL)
- A Screaming Frog paid license to use the custom extraction tool*
*Note: There are alternatives for scraping on-page copy. I’ll leave you some links below.
Extracting copy using Screaming Frog
The steps below are a cut down version of the excellent, in-depth guide by Screaming Frog themselves on how to use their custom extraction tool.
It’s worth a read: Screaming Frog’s guide to web scraping.
Step one: Screaming Frog extractors
Open up the configuration tab in Screaming Frog> Custom> Extraction.
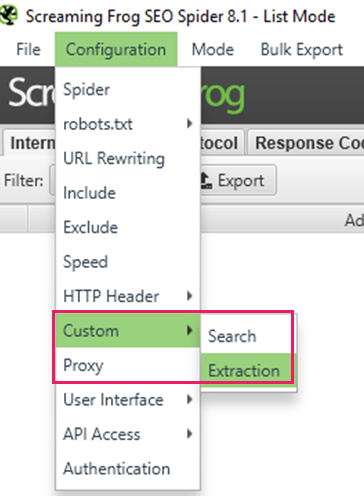
You’ll see a screen of the following extractors, up to 10. In an ideal world, you will only need to use a few to extract the relevant page copy.

Tip: if you want the clean copy, select that from the drop-down on the far right to strip out any HTML from the copy you’re scraping.
The next step is to fill out the XPath or CSS selector field that contains your copy.
Step two: Extracting the XPath or CSS Selector from your target site
For a more general introduction to XPath, take a look at Richard’s explanation here or go back to the Screaming Frog guide.
Essentially, we’re looking to use the browser’s built-in developer tools to copy a reference to element which contains the relevant page copy. In most modern browsers, you can open the dev tools simply by hitting F12.
For WordPress sites (particularly blog posts), extracting the reference is often easy as the templates are consistent across multiple pages and you don’t always need multiple extractors. Simply right click on the DOM element in question, go Copy > Copy XPath.
We’ll use Builtvisible as an example:
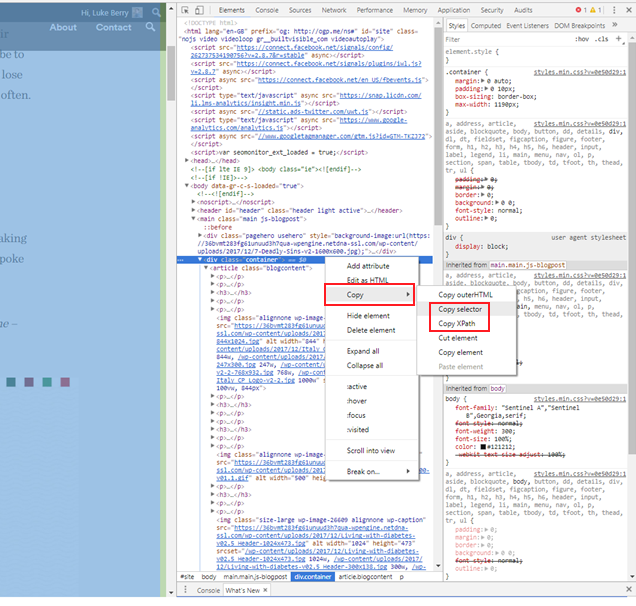
Then simply copy the XPath or CSS selector into the custom extraction fields back in Screaming Frog. Select the appropriate drop-down for XPath or CSS Selector:
Note: I have usually had more success extracting the relevant copy with the CSS selector.

Other scrapers:
Step three: Select your spider mode
Have your URLs to hand from your keyword mapping? Select the ‘List’ mode in Screaming Frog and paste your URLs.
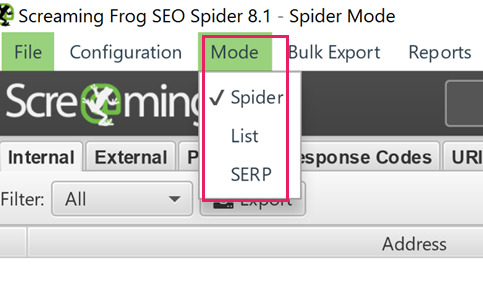
Need to crawl the site looking for your copy? Say if you’re looking for un-linked keywords on other pages to drive more internal value to their target ranking page? Use the spider mode.
Step four: Export your extraction
Using either the internal-all or custom exports, and change the filter to extraction.

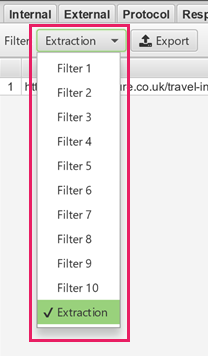
Check for errors or empty extractors missing text. If they are missing text the chances are that the element the copy is held on those pages is different, so inspect the page and do a further test on the extractors.
Remember: Screaming Frog gives you up to 10 different extractors to use per crawl.
Step five: LEN + SUBSTITUTE + UPPER
I lifted this formula from Dave over at Exceljet:=(LEN(text)-LEN(SUBSTITUTE(UPPER(text),UPPER(keyword),"")))/LEN(keyword)
Replace text with the excel cell reference where all your extracted text is.
Replace keyword with the cell reference to your target keyword. If you’ve set up your keyword mapping this can be matched to different keywords per URL.
Place this formula in a column in-line with your exported URLs and text from Screaming Frog.
Bear in mind it will only count exact matches of your keyword, but luckily not case sensitive thanks to UPPER.
Everything being well, you should get a spreadsheet that looks like this (without the blur of course):

There you go.
Note: For this site I used 5 extractors to extract copy from a few landing pages that used a different template. You can use either the ‘&’ function or concatenation to condense the copy from extractors into one ‘text’ cell (as you can see in the column ‘All current body text and headings’).
If you can think of or have used this process for other uses, please leave a comment below.

Richard Baxter
Thanks for this Luke – I’d find this process very useful if I were say, migrating a site to a new platform and I wanted to check the new copy had keyword targeting parity with the old pages. It’s too easy to make a mess of the titles and body copy.
I think there’s probably a few additional steps that seo tools for excel might offer – it’s also very easy to grab all H1’s and so on.
What I’d really like is a connector that grabs copy (product copy for a retailer let’s say) and rewrites sensibly, perhaps with a bit of AI thrown in.
Unfortunately I don’t think that exists yet but this article certainly got me thinking if it might be possible with conventional tools.
Luke Berry
@richard you’re right on that count, in fact it was exactly what initially drove this process – a full platform migration with a copy refresh and cut in the realm of 50% fewer words per page.
Thanks for the feedback, I’ll investigate adding a stage or maybe cover in a robust blog post dedicated to keyword mapping alone.
Dominic
Thanks for the article, short and useful content :>