Planning your approach
As an initial step in planning your redirects, it’s best to begin with a site crawl to get a sense of the architecture you’re dealing with. If it’s a bigger site and you don’t have access to an enterprise scale web crawler then don’t worry, a sample crawl from Screaming Frog should be sufficient.
To keep this at a reasonable size, untick Images, CSS, JavaScript, and SWF (Configuration > Spider). Next, connect your GA account (Configuration > API Access > Google Analytics); this will provide another data point to pivot by when you perform your analysis.
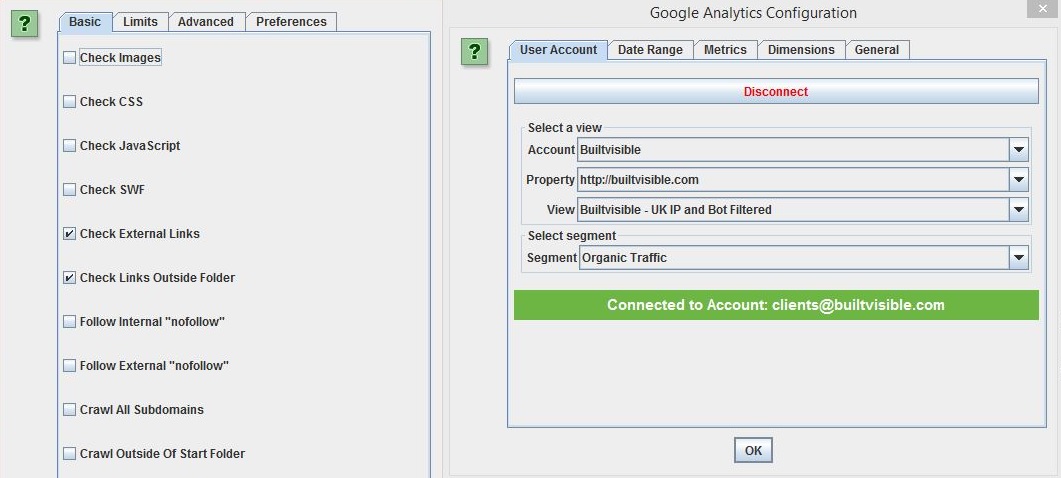
Begin a crawl and allow it to run until it begins to run out of memory. Stop and do the standard export from the ‘Internal’ tab.
I’d also recommend:
- Downloading a copy of your URL parameters report from Google Search Console
- Downloading a copy of the robots.txt file
Combine all of the above into one excel file and begin analysing the data. Specifically, you’ll want to look for:
- Page Types: What are the different page templates that make up the sites architecture? What patterns in URL structure or Meta Data do these templates follow?
- URL Parameters and File Extensions: What are the different parameters that your site uses and what are their functions? What file extensions are used?
- Canonicals and Directives: What URLs are disallowed within the robots.txt? What page levels directives are being used (e.g. meta robots noindex)? Are multiple URLs being consolidated via the canonical tag?
Considering these questions will give you a good indication of the pages you’ll want to map manually, and the ones that can be handled via redirect rules. Next, you can begin collating the full list of URLs and begin mapping.
Data collection
XML sitemaps
When deciding which pages to map, XML sitemaps are usually a good starting point. If you think about it, they’re effectively a giant list of all of the pages a website wants to be indexed; and if they want them to be indexed, then the chances are you’ll want to map them.
On large sites, these should be split into multiple parts to help diagnose indexation issues and increase indexation rates, and be accessible via a sitemap index file which is usually signposted within the sites /robots.txt. Failing that, you can check in Search Console, or, if you don’t have access, try common extensions like /sitemap.xml and /sitemap-index.xml. If all else fails try doing a ‘site:’ query; this will usually flag it up for you.
To download these files with the correct formatting, load up excel and perform an XML import (Data > From Other Sources > From XML Data Import). Next Paste in your XML files, until they’re listed in your Excel doc.
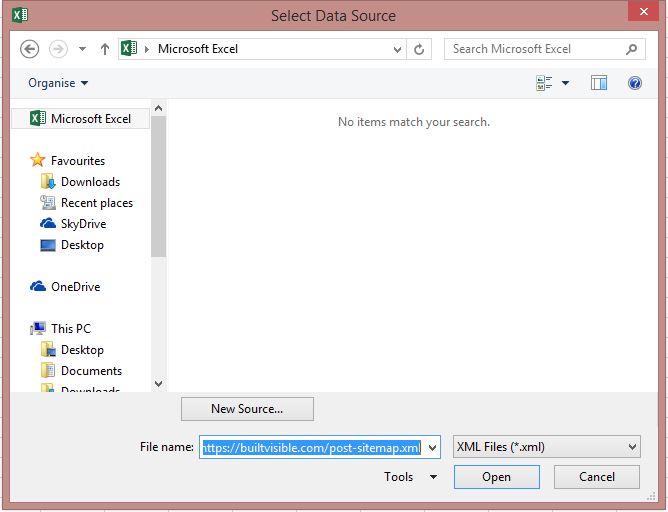
To gather information on our existing URLs, we’ll also want to crawl them in Screaming Frog. Most machines this will struggle with batches over about 25k in size, so split these up as necessary. Increasing the memory allocation will help with this.
Swap over to list mode and ensure that the ‘Always Follow Redirects’ option is selected (Configuration > Spider > Advanced). Upload your list and start crawling.
Note: If you’re working on a large site, you may be looking at 20+ individual crawls. This data is going to take some time to gather, so plan in advance and then just run crawls in the background over a few days. It’s also worth pointing out that you can open more than one version of Screaming Frog at a time; if you have a reasonable machine, then you should be able to handle two running simultaneously. This is particularly useful if there are any server settings restricting the speed with which you’re able to crawl.
As these complete, save the crawls somewhere and do an ‘Internal – All’ export for each. I like to do this into a separate excel file so I still have a copy of the raw sitemaps. Review these crawls looking for:
- Status Code Errors: 404s, 410s, 500s, etc. Remove any dead pages that are listed.
- Redirects: 301s, 302s, etc. Check redirect paths and remove/update URLs as necessary, only including URLs that successfully resolve and return a 200 (OK) status code. If large chains exist, you can easily find the correct URL to include by opening up your SF files again and performing a ‘Redirect Chains’ report.
- Meta Robots Tags: Remove any erroneous pages that are set to noindex, but included within the sitemap.
- Canonical Tags: Create an additional column and use =EXACT to compare URLs to their canonical link element. Review any that flag up as false and remove those that point at other pages included within your sitemaps.
- Blocked by Robots.txt: Remove any URLs included that are blocked by robots.txt.
Note: The amount of errors you find will be largely dictated by how frequently the sitemaps are updated. The <lastmod> will give you a good indication of this. If the sitemaps dynamically update, then the errors will likely be minimal.
Google Analytics
In addition to the XML sitemaps, GA is also a great source of URLs that need to be redirected. This can of course be obtained via Screaming Frog, but only on the URLs you are already aware of. As a secondary step, you’ll also want to perform an export of organic traffic by landing page – 1-2 months of data is usually sufficient.
You can export this via the GA platform itself, but it’s capped at 5k rows. Instead, you can use the Google Analytics Spreadsheet Add On, as denoted by Dan in this post, which will allow you to export 10k rows at a time.
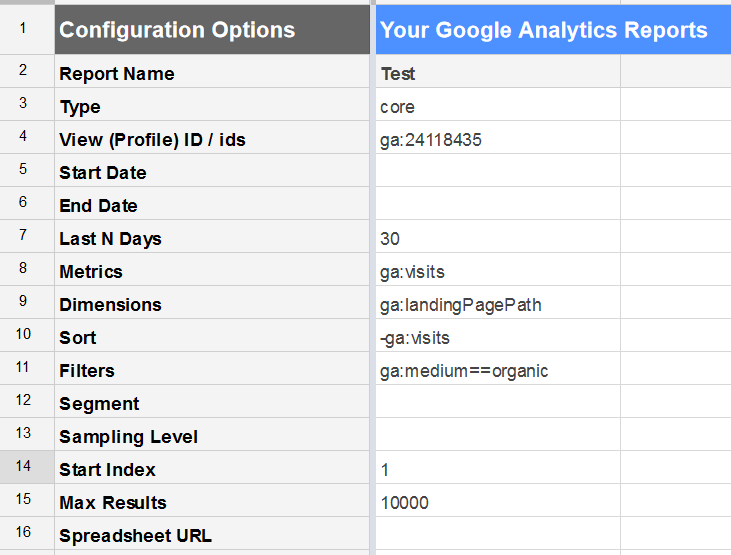
If necessary, you can pull more than 10k by using Excel and the Analytics Edge plugin. For detailed instructions, check out Glenn Gabe’s post.
Combine your cleansed Sitemap data in your Excel Workbook – grouping by page type if necessary – and add your Analytics export on to another sheet. Use =CONCATENATE to add your domain name to existing URL stem, and then perform a =VLOOKUP to check whether the URL is already within your existing data set. For ease of filtering, you can combine this with an =IFERROR, e.g.
=IFERROR(VLOOKUP(A2,Sheet1!$1:$1048576,1,FALSE),"No")
Run through any new URLs through Screaming Frog and add to the main list as necessary.
Backlink checker
On large sites, it’s likely that you’ll have link equity split across a wide subset of URLs. To ensure that this equity is passed on, you’ll need to make sure that these URLs are redirected, even if they’re no longer in use.
Using Majestic as an example, performing a pages export will provide a list of the top 5000 URLs, alongside referring domains and backlinks. Use another VLOOKUP to check to see whether these URLs are already listed. Run through any new URLs through Screaming Frog and add to the main list as necessary.
Site crawls
At this point, you should have a pretty complete list of URLs – at least those that drive the majority of organic traffic to your site – but you may still want to do a final crawl.
Do what you can to reduce the size by limiting it to indexable, HTML resources only.
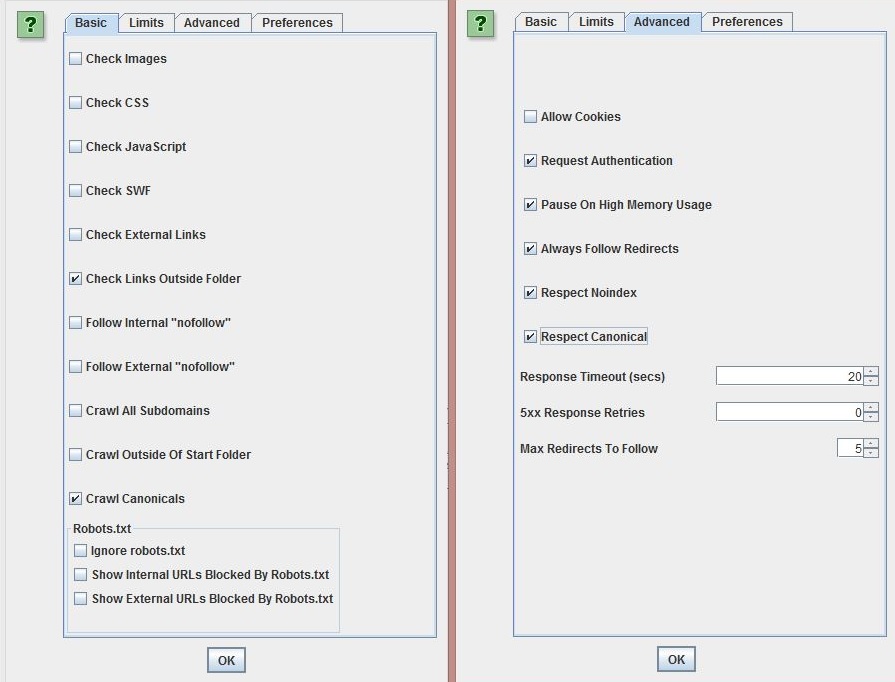
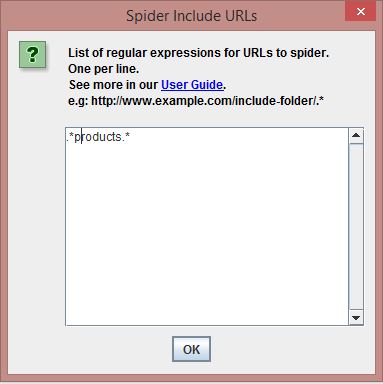
If required, you can also use Configuration > Exclude/Include to control which URLs are spidered. As an example, if you have a large quantity of products and are unsure they’ve all been included, then you can use basic regex. For example: .*products.*
Tying it together
Although we now have a complete list of URLs we need to redirect, we still don’t have any information about the site we’re migrating to. The above process will also need to be repeated for this domain; follow the steps again until you have both lists.
Redirect mapping
Following the steps in the previous points, you should now have a full list of cleansed URLs for both domains and a large quantity of associated data. Open up a fresh Workbook and paste the data for the URLs you are trying to match on to separate sheets. I like to do this by page type – e.g. products file, categories file – but it’s purely personal preference; this just prevents it freezing due to the size of the file. Next, begin mapping using the following techniques.
H1s & title tags
On large sites, both H1 tags and titles are likely to be heavily templated, making them excellent for redirect mapping. Typically, I like to start with H1’s as they tend to be shorter and are more likely to yield a positive match. To perform our mapping, we’re once again going to utilise Excel’s VLOOKUP function.
Start by navigating to the site you’re migrating to and move the H1 data into the first column; VLOOKUP always searches the leftmost column to find a value so this is necessary for the function to work.
Afterward, create a new column next to the URLs within the other sheet and perform a VLOOKUP using your H1 column as the lookup value, and the column number where your URLs are located. E.g.
=VLOOKUP([@H1],Sheet!$1:$1048576,2,FALSE)
By designating the URL column as the one to be return, you’ll end up with a matched lists of all the URLs you want to redirect with their equivalent on the opposing domain.
Presuming that not all of your pages have matched – very unlikely – you can repeat the above process for title tags. Often this will require the removal of the brand name from the end of the tag, which is easily accomplished by selecting the relevant column and replacing the brand with nothing (Ctrl + H).
URL stems
If H1’s and titles aren’t an option, or only partially worked for you, then you can also look at matching by URL stems.
On a platform like ATG, the initial URLs you have may look something like this:
- https://www.example.com/product-example-1/35742567.prd
- https://www.example.com/e/promo/promo-example-1.end
We’ll therefore need to strip out the domain name, file extensions and IDs before they can be mapped.
Create a new column next to your full URLs and use a formula such as the following to strip out the domain name:
=LEFT(A1,FIND("/",A1,9)-1)
Next, use Text to Columns to split the data (Data > Text to Columns > Delimited > Other).
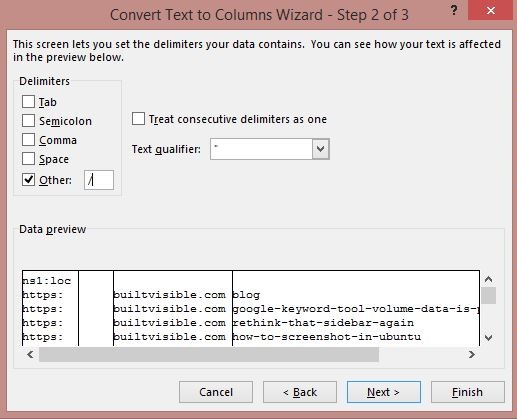
The above function will split your stems into a different column every time it encounters a slash within the URL, allowing you to isolate the text. For example:
- product-example-1
- promo-example-1
Repeat this process for both sets of URLs and add the formatted stem into a new column on each sheet. To match, follow the same process used for the Title Tags and H1’s.
Note: Text to columns will attempt to replace data in other columns. To prevent overwriting any of your existing data, perform your URL cleansing on a different sheet.
Top ranking URLs
Even if the above steps have worked for you, at this point you’ll likely be left with a few 1000 URLs that simply don’t match on any of the above techniques. In this scenario, if the pages have link value or drive traffic, then you may be forced to find the closest match manually. But if the URLs/domain you’re migrating to are already indexed, you can try using the site: search operator.
For example, if your ‘boys blue shoes’ page hasn’t matched, then a search for site:example.com boys blue shoes should return the most relevant URL. This can easily be accomplished in bulk by taking the page URL stems, stripping out the formatting and using the concatenate function in excel to merge into a large list.
At this point you can just transfer the list into your rank checking tool of choice; however, if you don’t have access to one, or its cloud based and you can’t afford to wait 24 hours, then i’d suggest using Sean Malseed’s Gdocs keyword position tool. This can be really effective if you only need to perform a few hundred requests at a time. Sometimes you may find that the tools gets stuck on ‘Crawling…’; in these instances just delete the keywords from the sheet and then undo, which will refresh the crawl.
As a final point, it is worth noting that this technique will only return the URL that Google deems most appropriate to your specific query, not the closest possible match. This can be problematic if your site has a poor architecture and/or lots of cannibalisation issues. For this reason it is always worth giving the results returned a once over, manually changing as necessary.
Final checks
Once you’ve mapped out all of your redirects, you’ll want to check that the URLs you’re redirecting to return the appropriate 200 (OK) status codes. On a live site, this is simply a case of performing another list mode crawl in Screaming Frog. If you’re on a staging site, simply do a find and replace, substituting the domain for the staging address.

Chris Hubbard
Thanks for the post. It came at a great time as I start an 80K URL project in the morning.
Will Nye
Nice. Best of luck with it, Chris!
levent güde
aşağda yazılı web sitemi gözden geçirebilirmisin 404 faund veriyor sevgilerimle