Addressing the fundamental issues of site architecture for SEO
One of the most impactful ways to improve the traffic driving potential of your website, especially in its long tail, is to improve your site architecture.
To do that, you need to understand the sort of classic issues with PageRank distribution we encounter in complex websites, and how those issues are addressed with real world solutions.
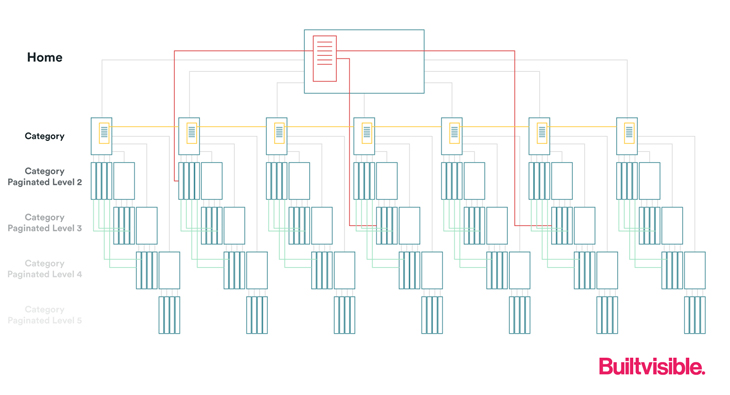
Let’s get started by addressing the classic issue of PageRank distribution in content silos. This is a typical situation encountered in a large scale website where many items are listed in a paginated series of category pages.
Naturally then, Ecommerce websites are highly prone to these issues, as are jobs board websites (read our guide to recruitment SEO here).
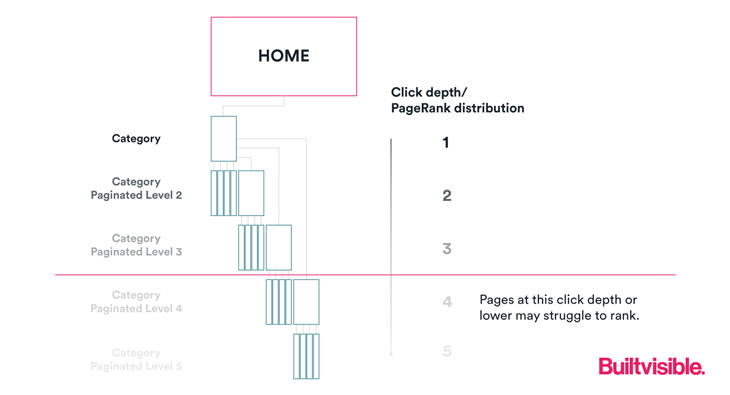
In our scenario, our home page links to a category page. That category page lists numerous products. The category page uses pagination, and therefore features paginated links that go on to pass PageRank to more product pages.
Pages at higher click depth (further “down” the architecture) receive less additional PageRank, which might mean they’re crawled infrequently (if ever). This reduces the likelihood of a new page being discovered which would naturally contribute negatively to the long tail traffic driving performance of the site overall. It also reduces the likelihood of say, a product page being recrawled – an issue should stock status change in the product’s schema markup.
Excessive click depth is a problem. It will be less likely you’ll find those pages ranking visibly in Google’s index.
In other words, the pages will rank, but at a threshold far below the 10 to 20 positions likely to drive any meaningful traffic at all. The large part of the problem is remarkably easy to address, though.
Flattening the site architecture
Great site architecture is all about helping users and search engines find their way around your site.
It’s about getting the best and most relevant content in front of users and reducing the number of times they have to click to find it.
By flattening your site architecture you can make gains in indexation proxy metrics such as the number of pages generating traffic from search engines and the number of keywords driving traffic to your site.
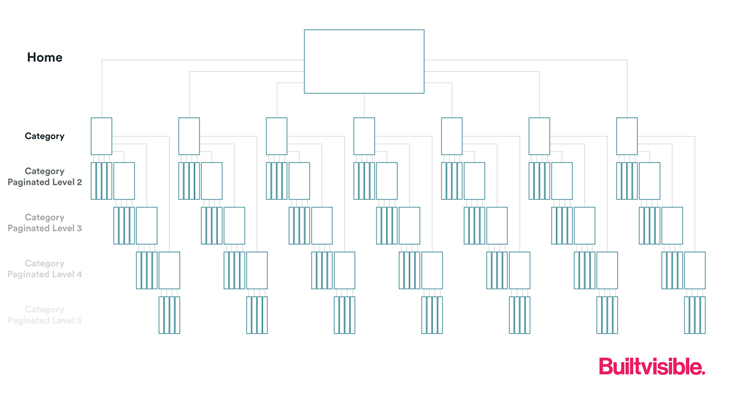
Ask: How many clicks does it take to get from your homepage to your deepest layer of content?
Let’s look at website that uses category and product page architecture. The silos are clear, with a link from the homepage being the only discovery mechanism for users and search engines to the deepest levels of content.
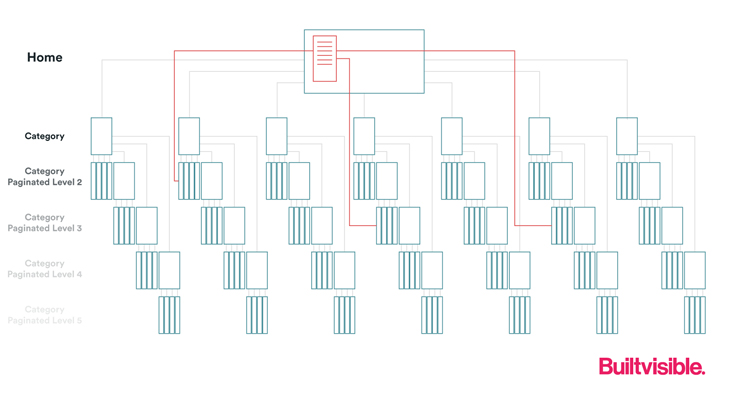
To help solve some of the discoverability problem, let’s add some feature based navigation to the homepage.
For example, featured products, latest jobs or trending searches boxes. The change to the architecture could look something like this:
Hopefully, you’ve developed your category pages as link worthy assets. Meaning, there’s a potential quick win by linking between pages at the category page level.
In the small architecture example below, these links would simply be handled by standard navigational links, though if you’re a larger website with hundreds or thousands of category pages and extensive faceted navigation, you’d need to find a more creative solution.
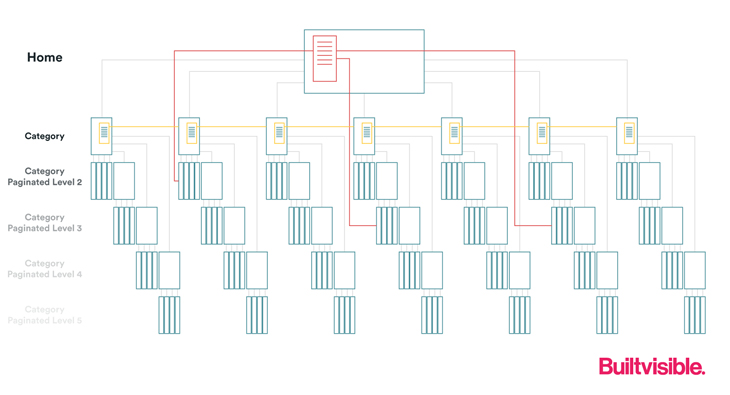
And finally, let’s add some related links between our lower tier pages. You could also have “recently added” features on the homepage and category pages or consider most popular boxes and so on.
That’s the basics over and done with; we’re going to revisit real world solutions to common architectural problems later in the article. First, though, I’d like to look the options available for us to locate pages that are weak (and need links) and very strong (pages that can give links).
Methodologies to identify strength and weaknesses in your internal links architecture
Consider the scenario. You’ve inherited a medium size, commercial retail website. On the surface, it looks OK (it has a lot of the internal link features we’ve discussed already) but, being an optimisation specialist, you want to find some new opportunities.
Before we proceed, I feel a bit like we have to do this:
About PageRank and why domain level authority metrics are a bad idea for this kind of thing
The PageRank algorithm, in Google’s words “works by counting the number and quality of links to a page to determine a rough estimate of how important the website is.”
Reading about PageRank is, to an SEO like me an interesting read but a discussion on algorithms is out of scope for this article, and slightly above my pay grade. It’s of academic interest, of course but don’t feel pressured to go too deep into this stuff. I don’t worry about it much at all.
Over to Dixon Jones, then, who can explain this stuff better than I can. This explainer from Dixon Jones shows you how the maths of PageRank works and then goes on to demonstrate how the maths can deliver some pretty unexpected outcomes.

Of particular note, his explanation on why you should not look at domain level metrics to decide anything is to the point.
I’ll be using page level metrics, from now on then.
Building your own internal link scoring data to spot weaknesses and opportunities
There’s an obvious and well known problem with Google PageRank. We don’t know Google’s PageRank scores for our pages.
Calculating PageRank derived metrics is hard. Most of us haven’t crawled the web, nor have we been running the massive computational resources required to come up with our own data. Tools providers do, though. Majestic’s Trust Flow metrics are a decent measure of the probable importance of a page in my opinion, so I’m happy to play with this as a replacement.
I’m going to take you, step by step through the process of building a dataset that can help you improve your internal links by identifying the stronger and weaker pages in your site architecture.
All gathered with everyday tools. Advanced understanding of search engine algorithms and statistics packages not required.
Diagnosing site architecture issues
Building a dataset for site architecture purposes will always be a variable process. Your work will depend very much on how advanced a client’s website already is. If, for example you’re just improving overall internal links by implementing classic real world solutions like “recently added jobs” then building a big data set probably isn’t strictly necessary on day 1.
But for more advanced applications there are some interesting ideas to apply here. Like Kevin’s internal PageRank methodology, for example. By combining data together from a variety of different sources, I think there’s scope to catch and kill site architecture issues in their tracks. There’s also scope to spot opportunities.
Take this methodology as it is: something for you to develop and modify to taste.
Tools
To get started, we’re going to get our favourite tools fired up. Among the notable contributors to this process, I must say that Sitebulb is a really interesting addition to my toolset.
That’s thanks to their internal PageRank calculation called Link Equity Score, which I’ll be using later on.
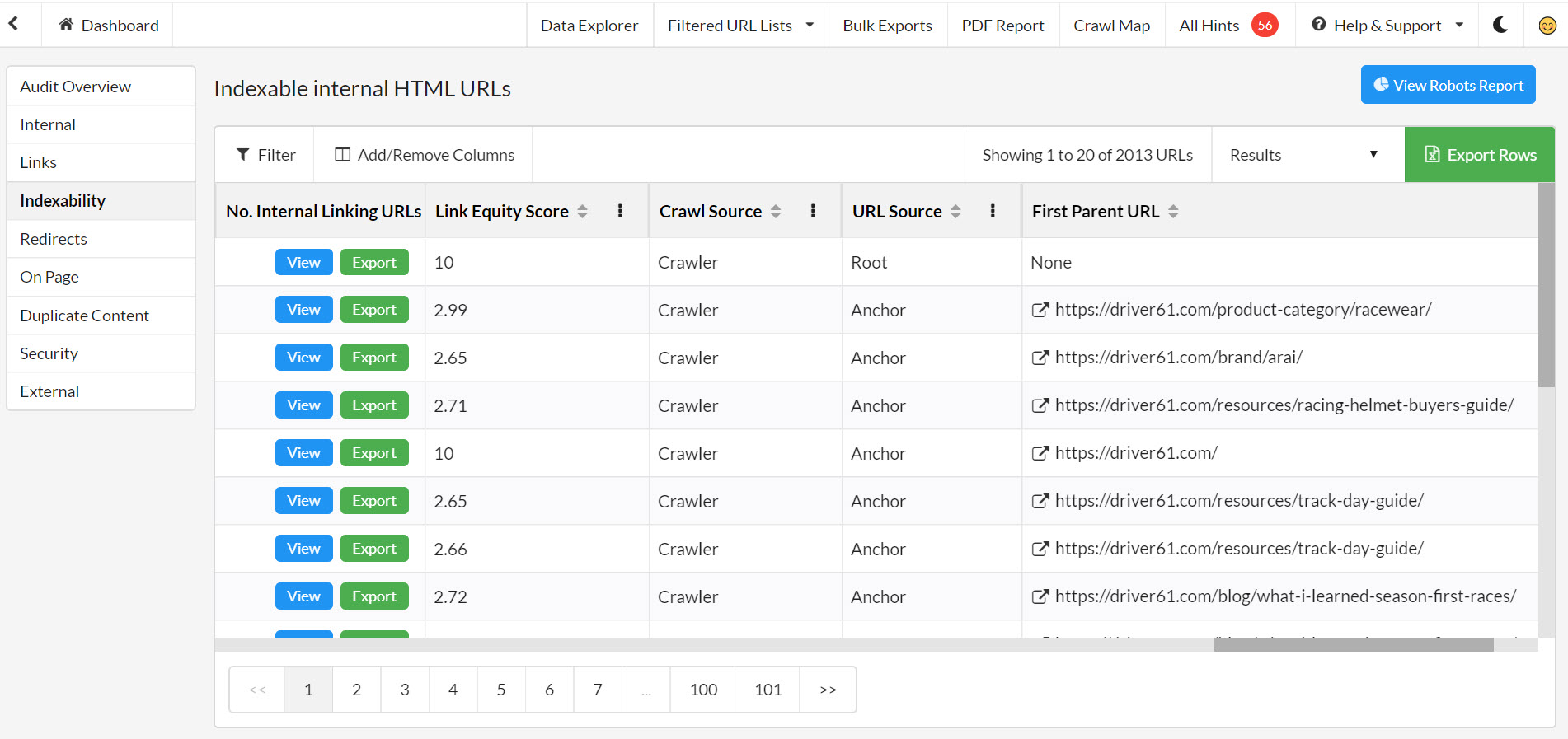
Sitebulb’s Internal links report – you could use indexable internal links report to reduce large data sets. The export comes with a handy internal link equity score, based on PageRank.
We’ll also be using the following:
- MajesticSEO API
- Log file data
- ScreamingFrog crawl and API extraction
- Search Console API
- Google Analytics API
- SiteBulb
- Excel
To build a data table consisting of:
- No. Internal Linking URLs
- Unique Outlinks
- GA Sessions
- Log Requests
- Search Console Impressions
- Majestic Citation Flow – URL (Exact URL)
- Link Equity Score
- Consolidated by VLOOKUP into a Pivot Table
Build the data set
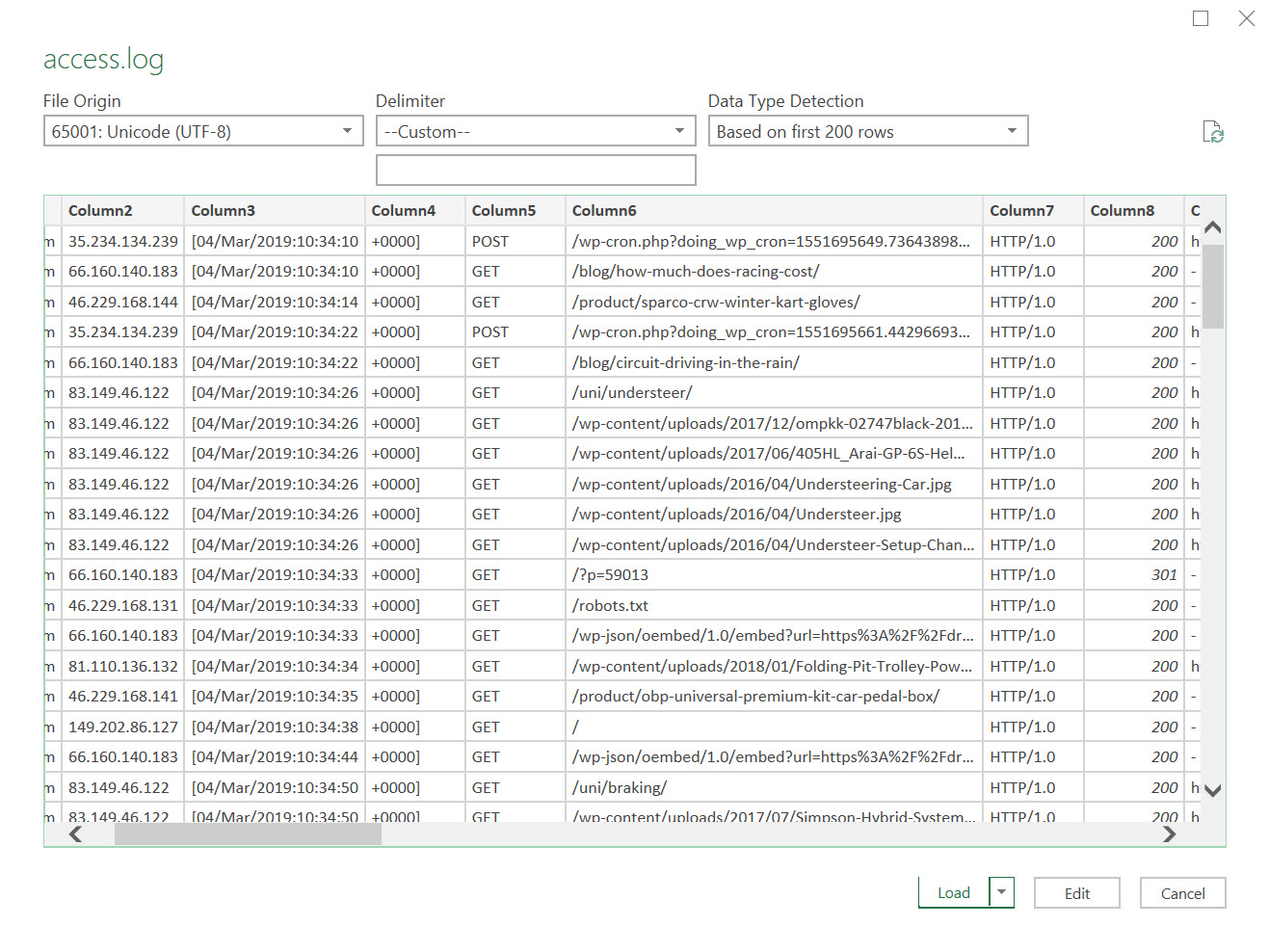
Start by collecting your raw data. I fetched some log file data from my Woocommerce website and imported the file into Excel. This import wasn’t perfect as I’m really only looking for a count of Googlebot requests per HTML page. For more advanced server log file analysis, read Dan’s amazing guide here.
I’m going to use Screamingfrog to import data via Majestic, the Google Analytics API and the Search Console API.
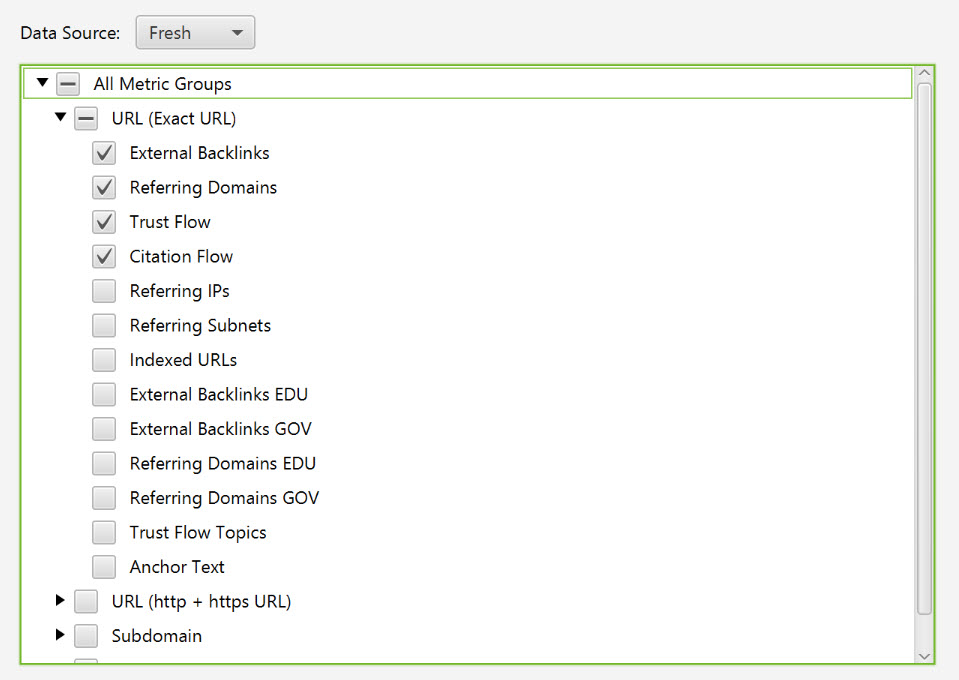
Run your Screamingfrog crawl in the usual way, exporting the data when the crawl has finished.
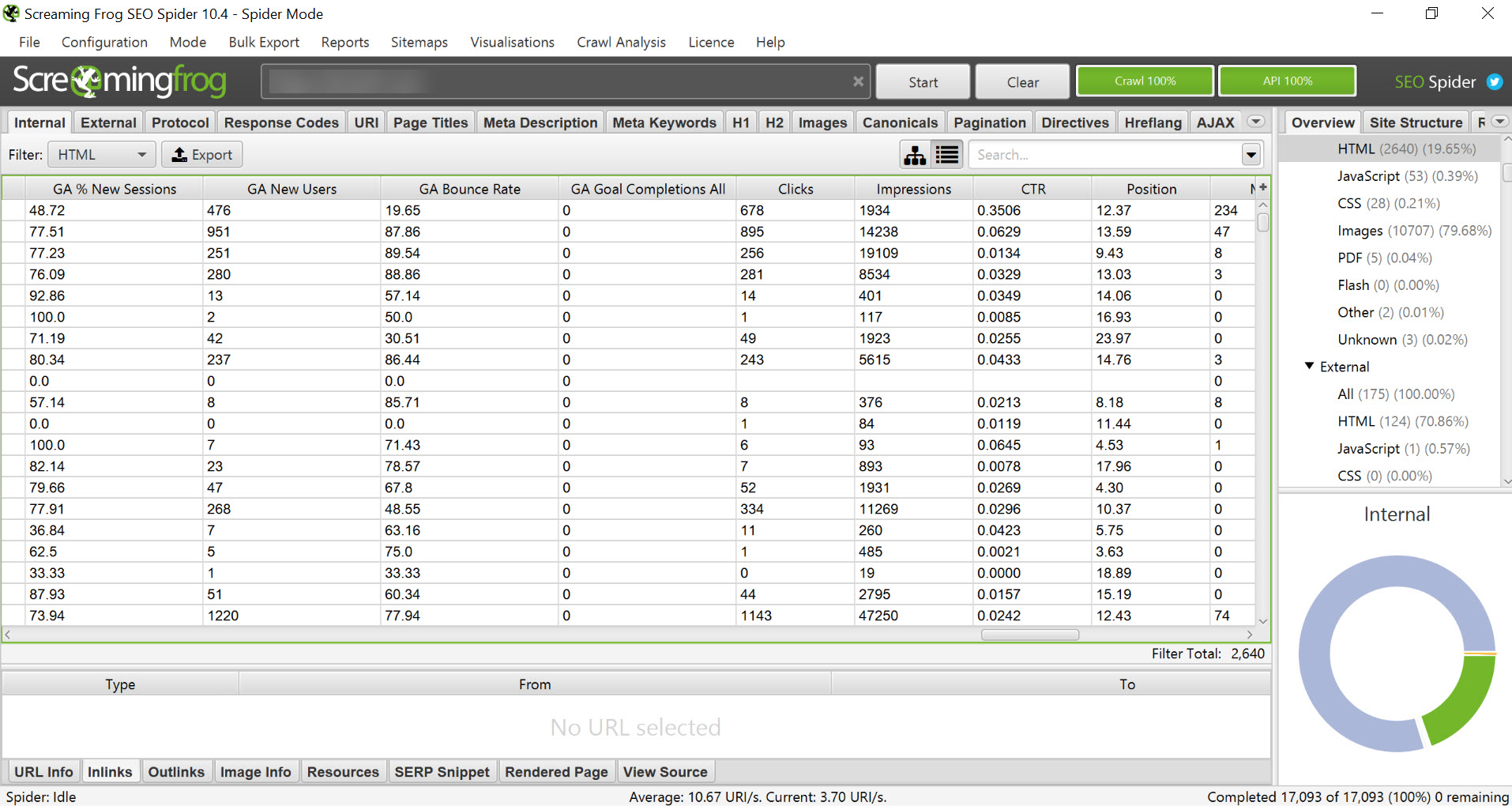
Screamingfrog getting all the cool metrics. Yes I know, they updated the version the same day I updated this article…
Once you’ve exported your Screamingfrog and Sitebulb data, consolidate into a master table with the usual VLOOKUPs:
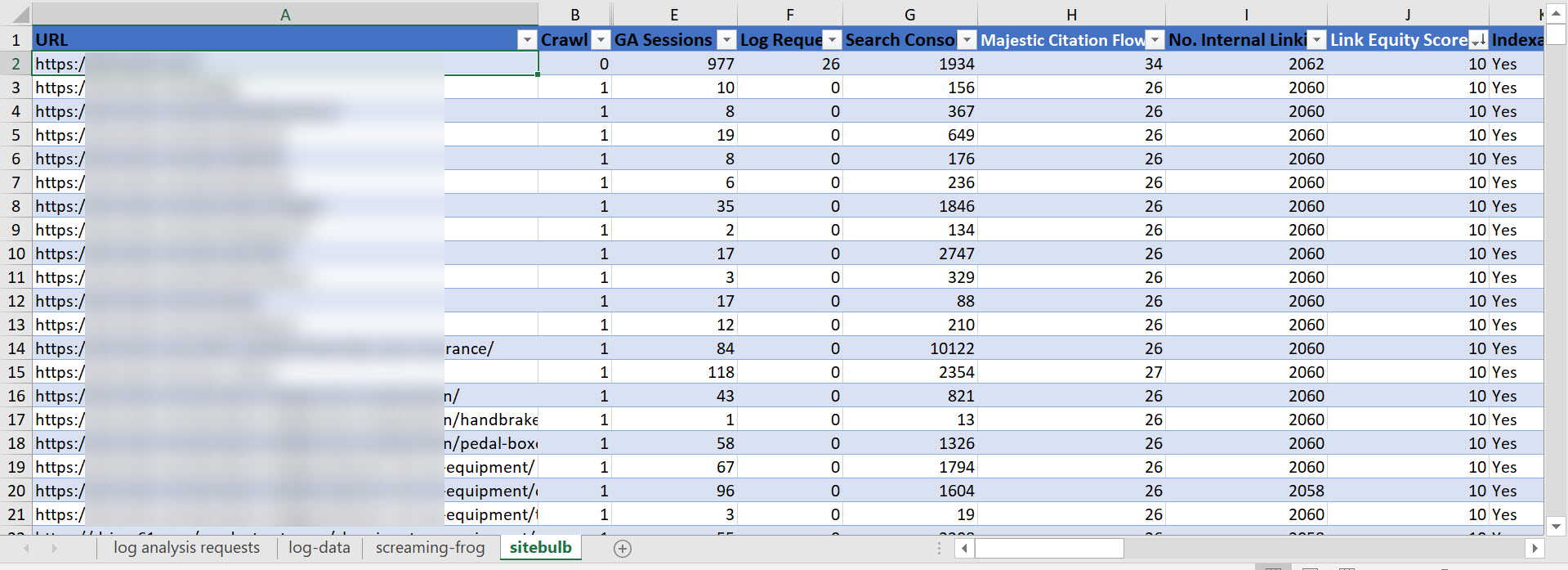
My combined data in Excel
Analysis
Here’s my completed data. I’ve created a pivot table and added filters for Crawl Depth, Search Console Impressions and GA Sessions, although it’s of course entirely up to you how you build yours.
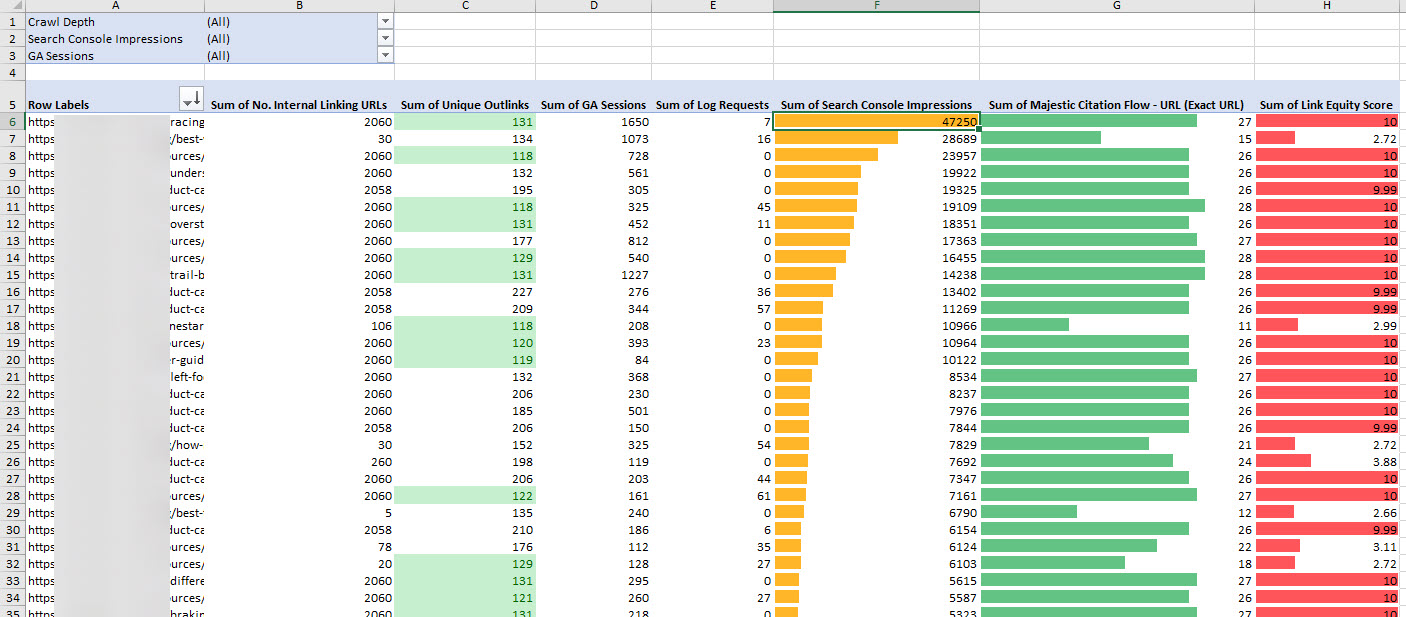
Interesting takeaways
Analysing data like this is always going to be to your particular preference and, a process likely to be unique to the site in question. There are, of course, some universal take aways that we can all gather. For example:
Sort for pages that have low numbers of internal links, but have high impressions via the search console data. You could derive that this page has traffic potential and might benefit by sending more links to this page.
Sort for pages that don’t link out very much (low outlinks) that have high citation and link equity. You might consider using the authority of these pages to improve the rankings of others.
Sort by highest search console impressions and fewest internal links to identify pages that could benefit from better internal linking.
Sort by very high click depth and then by search impressions to identify page types that might benefit from better internal links.
And so on.
Something that really stood out to me while I was prototyping this data; the smart move would be to automate this entire thing and integrated the recommendations into a dashboard for SEO use. That or develop functionality to dynamically update links across an entire website. That’s an interesting thought and I’m sure there are in-house teams at some very large companies that have these tools.
Solutions in the real world
There are lots of ways to improve your internal links in the real world. Here are some examples of ways to enhance your cross links in a site architecture:
Travel
- Similar destinations
- Nearby hotels / Landmarks
- Most popular / top countries
- Most popular / top cities
- Recently reviewed locations / hotels / resorts
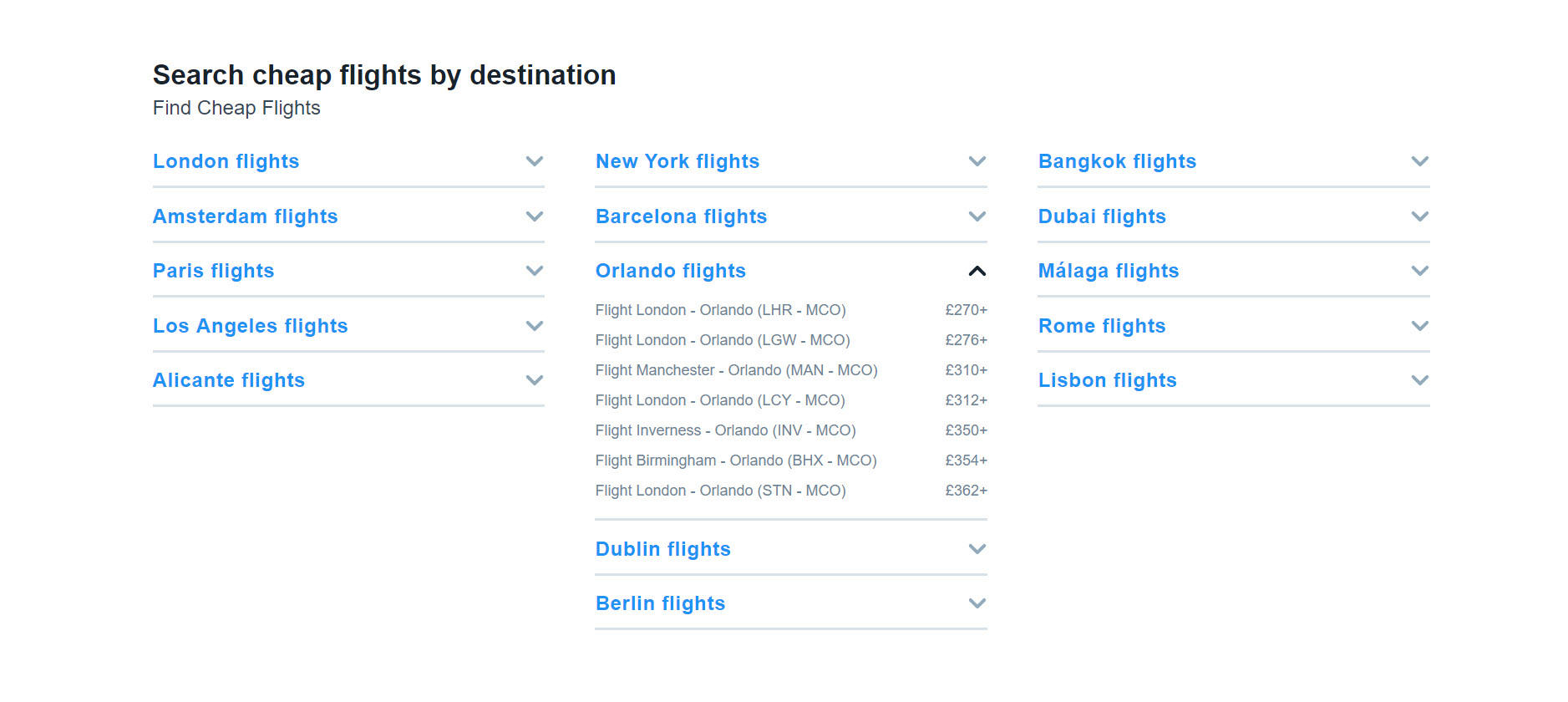
Kayak use this navigational feature to link to their destination and flight route pages.
Retail
- Popular products in this category
- Related (complimentary) products and accessories
- Related category links
- Users who viewed this item eventually bought
- Top rated / recently reviewed items
- Frequently searched items / categories
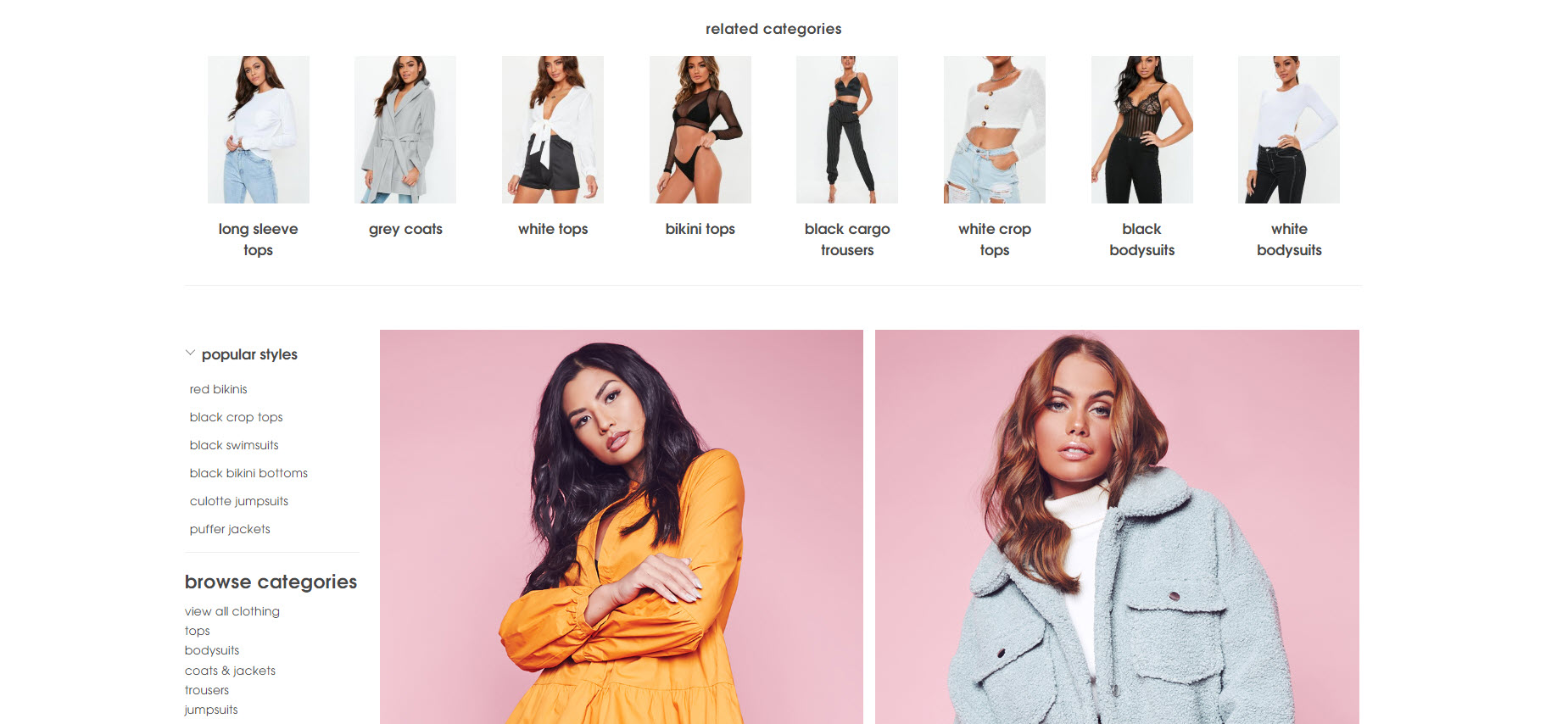
Misguided use related categories, and popular styles links to improve their category level architecture.
Jobs
- Recently added
- Related jobs
- Jobs by qualification / location and so on
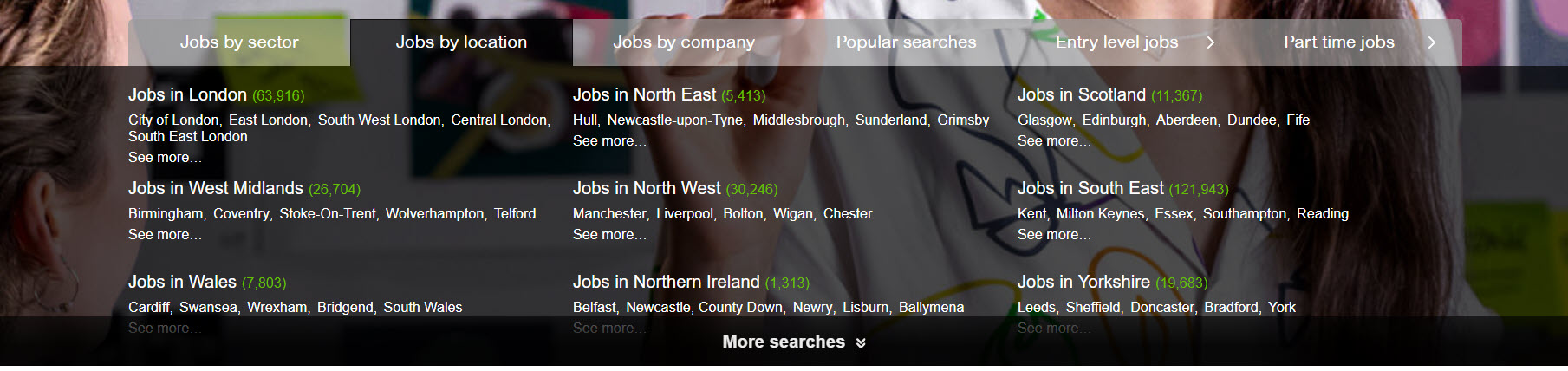
TotalJobs use this feature on their homepage to flatten their architecture.
In summary
Site architecture is an exciting, always evolving subject. Thanks to the tools we have at our disposal there’s so much scope to continually develop the process of tracking down and improving upon, issues with your site architecture.
Please leave your thoughts in the comments below…

Mathias
Hi, great article thanks !
What about old fashioned html sitemaps to flattened our site architecture ?
Richard Baxter
I’m sure there are lots of views on static html sitemaps. I think if you’ve got a smaller site, then you could make a nice sitemap page but then, if it’s a small site the architecture would probably be really easy to fix. Larger sites I’m less keen – you’d end up with a lot of really thin pages, much like a directory. So I think for larger websites there are probably more creative ways to solve any structural problems.
Dan Sharp
Hi Rich,
Excellent guide, thank you writing it. I mentioned to you on Twitter, it’s perfect timing for some internal training, and the images really help.
Just to add to the above, SF has a ‘Link Score’ as well (essentially Internal PageRank value on a 0-100 scale).
It’s hidden away under ‘Crawl Analysis’, you just need to hit ‘Crawl Analysis > Start’ for the column in the Internal tab to populate post crawl. Probably quite similar to SB, but will hopefully compliment further.
We also find ‘unique inlinks’ and ‘% of total’ for linking analysis useful, too.
Cheers.
Dan
Richard Baxter
Thanks Dan, that’ll be easy to implement into this data!
Jean-Christophe Chouinard
I agree! This post is amazing! Thank you Dan for this comment, I was just checking if SF was providing some kind of “Link Score”… Screaming Frog really is a Power SEO Tool!
Tharindu
What a great article Richard. Surely there is a lack of expert articles about site architecture like this. Worth reading to the last word.
Sam Pennington
I love this article, however, I was just getting in to it when it ended… I think there could be some iterations or additional considerations to add such as “Navigation”. Navigation can not only corrupt the Link Score metrics but also this type of analysis could highlight the importance of the URLs featured in your navigation.
In essence you could do this type of analysis on the links featured in your navigation alone and therefore evaluate the quality and usage of the links it encompasses to then go on to look at navigation ordering etc.
I also appreciated the imagery and examples but think the article would have also benefited from some bad examples too – without naming and shaming or merely as a hypothetical poor structure diagram.
Other considerations or links to other articles could be beneficial too such as: URL Structure, Orphan Pages, Sitemaps…
If you really wanted to push the boat out you could go as far as turning this in to a Rachel Costello style Whitepaper like the ones she creates for Deepcrawl.
All in all a good article – enjoyed reading it.
Richard Baxter
Thanks for the feedback Sam, you’re absolutely right. Reasonable surfer implies that links in different sections of the site should be weighted differently. The article is a “drive by” of our in-house processes aimed to help beginners and intermediates. Fortunately it’s easy to categorise links in certain types of container (like filter nav, global header, footer and so on). We’d take all that into account in a full fat architecture audit!
Jean-Christophe Chouinard
Quick question Richard!
A lot of people talk about creating closely related content silos and to try to minimize cross-linking between not related content.
So, in this case, they wouldn’t link level 3 with other level 3 pages that are not in the same category. What’s your cue on that?
Dragan
Rich, this was super informative. I’m impressed with how you actually give precise advice for people who don’t know where to start. Great
Warren Cowan | CEO, FoundIt!
Hey Richard, awesome article and a man after my own heart. We’re all super flattered and pumped here, as we actually did the smart move you suggested and built the platform to automate the whole thing… and as you allured to, it is also the very engine behind that navigation you showcased on Missguided. So from myself and our team (and I’m sure the team at Missguided) many thanks for the recognition. It’s also nice to know we’re not the only IA obsessed people walking the planet.
Its worth noting too, that this type of approach doesn’t just benefit SEO, but actually prioritisies content that shoppers want but cant find either, and so helps more people find the products they want quicker, leading to higher site wide conversion rates !
We’ve split tested this navigational approach on retail websites too to analyse this, and have found that a better architecture can increase headline conversion rate by as much as 4%. So if awesome SEO still isnt a good enough reason for a company to adopt this approach, perhaps a few percentage points on their annual growth will be!
David Carralon
Excellent guide, Richard. I do remember that session of yours on site architecture at SES London. But I think you gave an earlier one some years before titled ‘Industrial Strenth site architecture…’ which coupled with Moz’s ancient PageRank guide shaped my knowledge and direction to help me move on various inhouse roles. Thanks to Dan Sharp too for the tip on Link Score. I hadnt even noticed it. Awesome
Richard Baxter
Thanks David, yes that’s right: SMX 2009 I believe. That was a less developed version and had quite a lot of diagnostic and organisational advice too (I think!)
John Zakaria
Thanks Richard for discussing how we can solve site architecture issues, there are very rare guides on this point especially improving the internal links. Very useful guide!
Mike
Thanks Richard, I found this article (and the others it links to) incredibly useful. Much appreciated!
Si Shangase
Thanks for the article Richard, this will be my goto when building out an in-house automated version of this process to scale up for our clients. Ideally having this report dynamically would be the best option. Including indexation reports for deeper pages would also be good.
This can help surface pages that need additional links or content updates throughout the site would be useful as well.
Emer McCourt
Hi there, thanks for this… I’d love it you could include more actionable takeaways in the Interesting takeaways section – it would really help! Thanks again.
Nick Samuel
Hi Richard, I’ve seen numerous people share this on Twitter in the last month or so and have only just got around to reading it…
Once again, you make me and other SEOs feel inadequate with your Pivot Table Mash-up :-P
Joking aside, I really need to create something like this as I’m finding more and more clients having their S**T together these days. This means the usual roadmap of Technical SEO fixes is taking less time to implement, and thus we eventually need be focusing on more high-value, slightly more uncommon activities like this.
One question I have for you though, what about over-optimisation of internal links or if I’m appealing to the old-school SEO in you, PR sculpting?
In your experience is there such thing of too many internal links and “leaking” out too much link juice?!
Cheers,
Nick
Matt Ramage
Super thorough! Just bookmarked and will use this as a resource for architecture issues going forward. Thanks for putting out great content!
Zgred
A good way is to have internal linking from the blog (articles) especially when you have a lot of orphaned pages or your site is big and you can’t build internal linking to all subpages.