Should I use standard pagination on my site’s category pages, or implement infinite scroll?
Products, jobs, events, blog posts – any type of content that is listed and categorised in some form of taxonomy has the need for pagination.
Users recognise and understand the meaning of those little numbered links. They’re there to move you forwards through a series of pages that list the content you’re interested in.
The use of pagination also has important SEO implications. Implemented correctly it allows a search engine crawler to be able to crawl and recrawl archived content on your site.
Some websites skip pagination, favouring a Javascript based infinite scroll. Take this example from Omega Watches, and watch the address bar carefully for the updates.
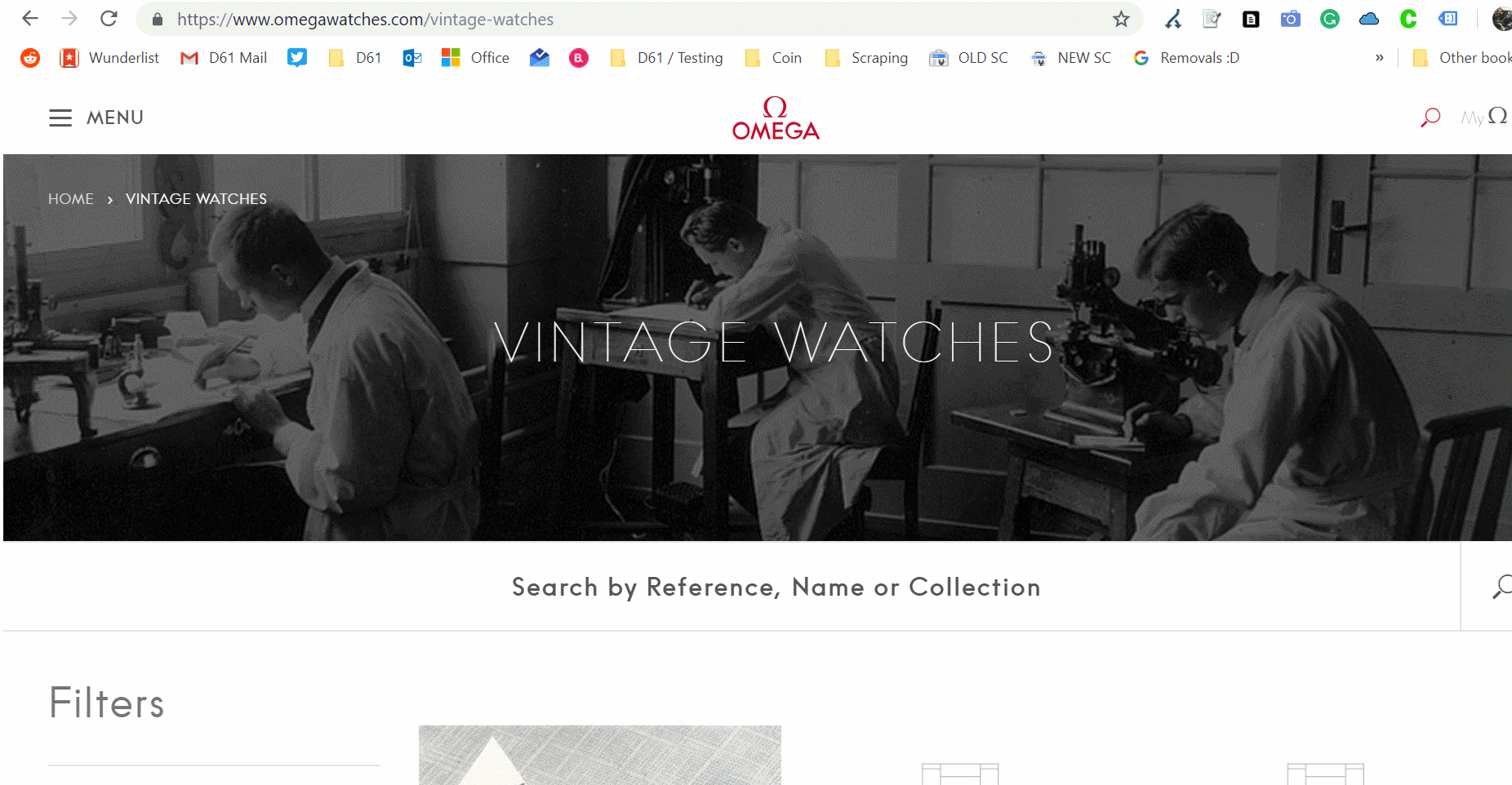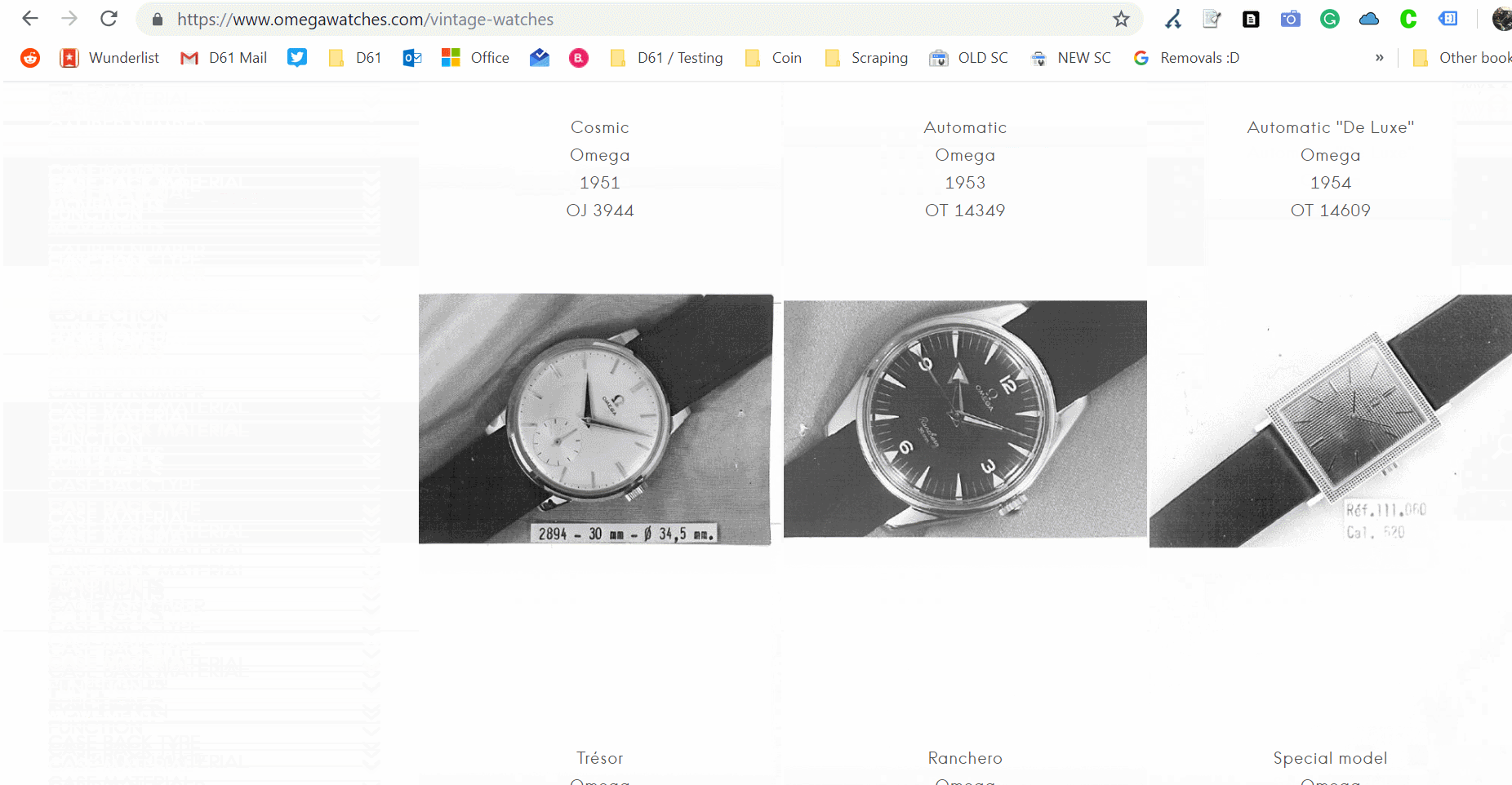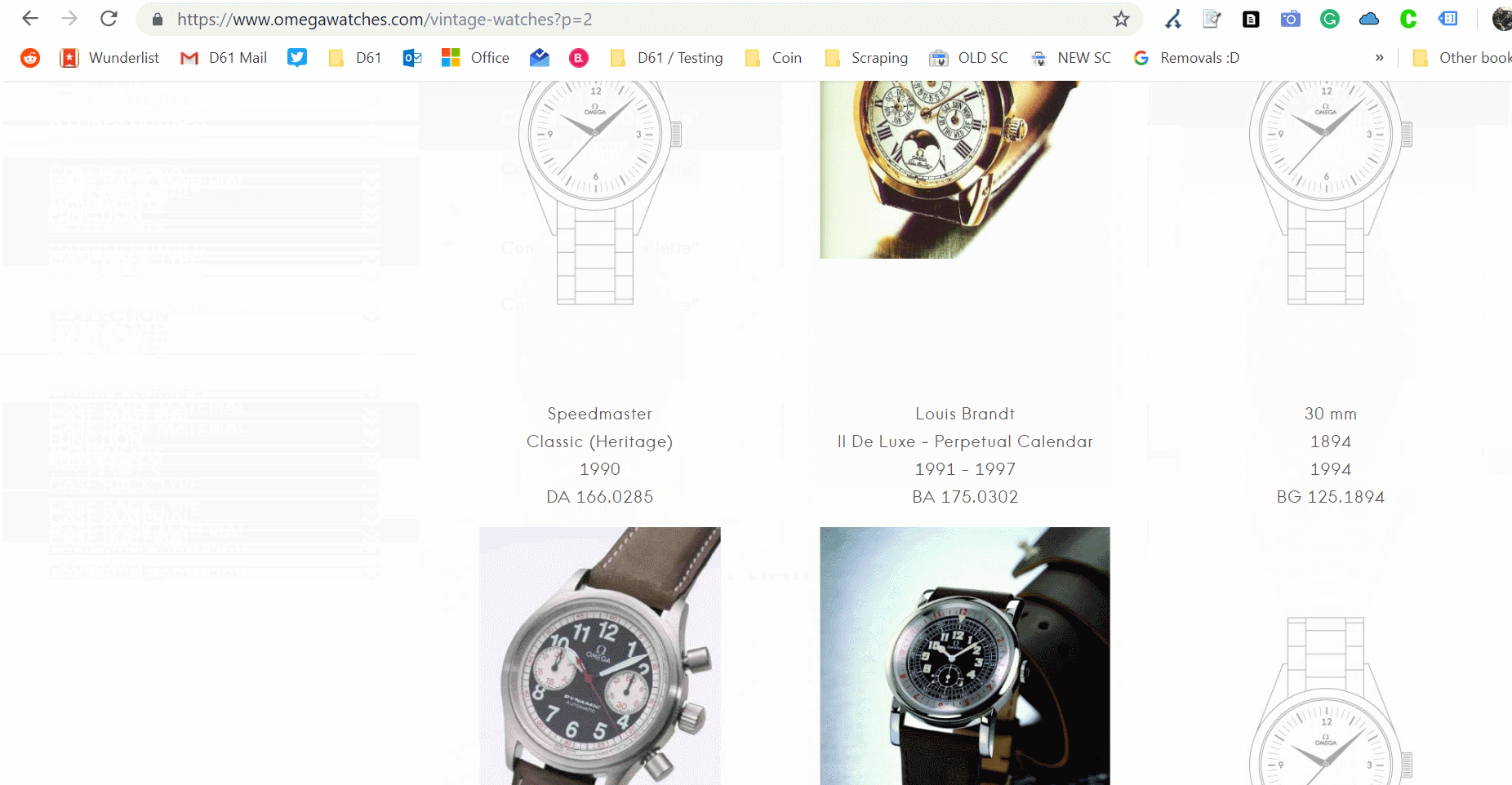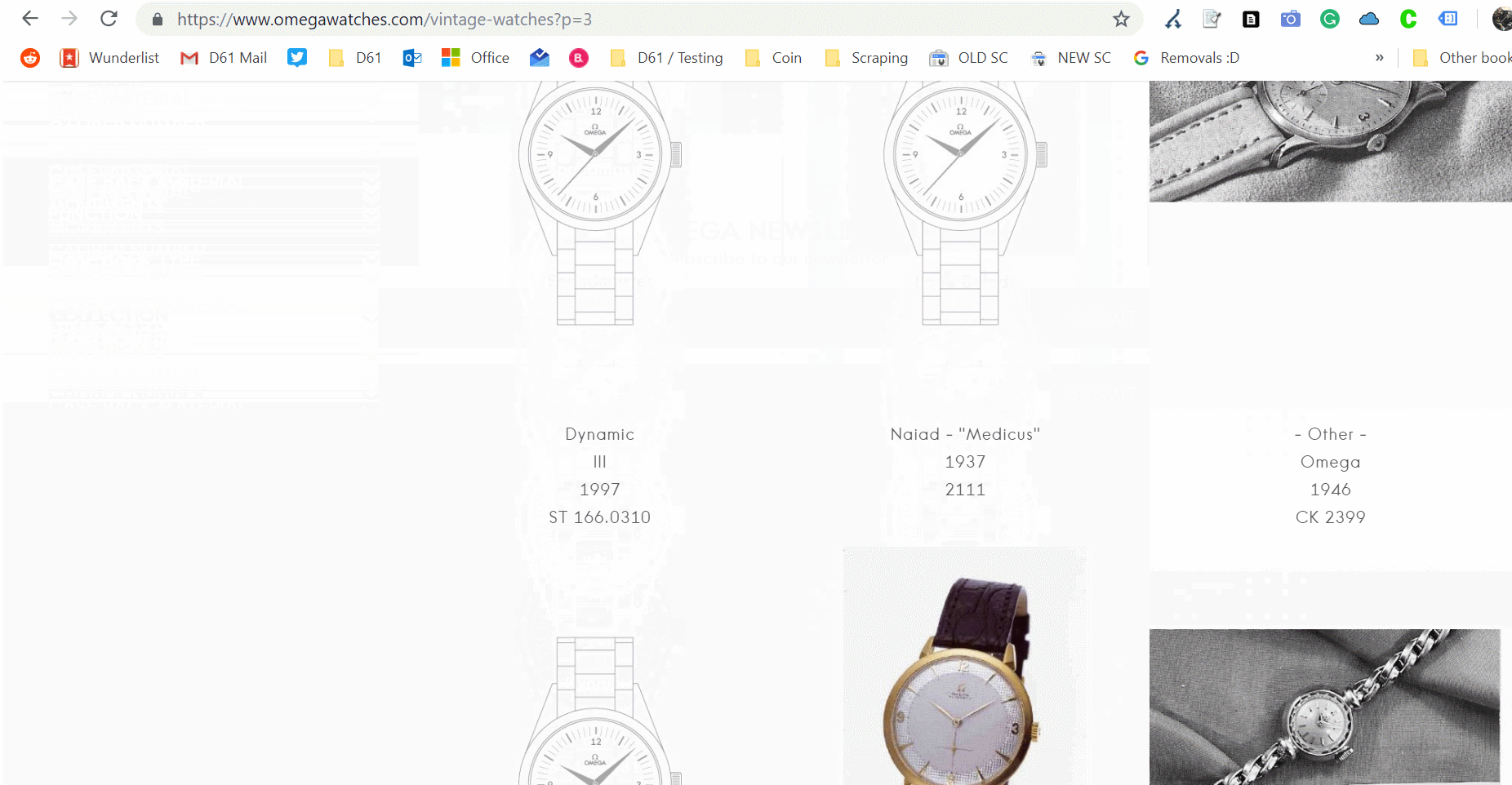
Omega’s vintage watches category is using an infinite scroll method.
The correct method of implementation is actually both. Whether you use infinite scroll or not, you definitely need to implement pagination best practices to ensure your category taxonomy is search friendly.
This article looks at how sites can achieve technical excellence when creating a paginated series on category pages, either with the classic “paginated” links or via infinite scroll.
Pagination
Here we have a Builtvisible client in the retail space:

You can see the numbered sequence of links, there are 3 pages in total.
URL structure
The URLs increase in numeric order like this:
Page 1: /product-category/racewear/racing-gloves/
Page 2: /product-category/racewear/racing-gloves/page/2/
Page 3: /product-category/racewear/racing-gloves/page/3/
As we move through the paginated sequence, the numbered links don’t link back to “/page/1/”. Our architecture has been coded well enough to avoid duplicating the root page in this way. If you can avoid this yourself, it just minimises a tiny loss of link equity through the site architecture by unnecessarily canonicalising.
Using pagination attributes rel=”next” and rel=”prev”
The rel="next" and rel="prev" link attributes are reasonably recent developments in SEO (introduced in 2011). They’re used to indicate the relationship between component URLs in a paginated series.
The attributes are placed in the head section of your paginated series and look like this:
<link rel="prev" href="https://www.example.com/product-category/racewear/racing-gloves/" />
<link rel="next" href="https://www.example.com/product-category/racewear/racing-gloves/page/3/" />
In the example above, you would currently be on /page/2/.
Implementation
Implementation is very simple. In the paginated series, always state the previous / next relationship. Use rel=”canonical” to declare the current page.
<link rel="prev" href="https://www.example.com/product-category/racewear/racing-gloves/" />
<link rel="next" href="https://www.example.com/product-category/racewear/racing-gloves/page/3/" />
<link rel="canonical" href="https://www.example.com/product-category/racewear/racing-gloves/page/2/"/>
When implementing a paginated series, using rel=”next” and rel=”prev”, follow these best practices.
- Always use a self referencing canonical tag on the current page
- Don’t use noindex or block pages in the sequence with robots.txt
- Don’t break the sequence or your paginated attributes might be ignored.
- Don’t use nofollow, avoid tracking parameters and redirects in your URL sequence.
- Don’t use blank rel=”prev” or rel=”next” atttributes on the first and last pages in the series.
- Use absolute, not relative URL paths.
Infinite scroll using pushState to the HTML5 history API
Inifinite scroll is really a feature addition to pagination, rather than an alternative. That’s because for SEO, you’re going to need paginated links visible in the HTML source to non-JS enabled browsers.
That’s supposed to be enough for search engines to crawl your pages.
What’s pushState?
PushState is part of the HTML 5 History API — a set of tools for managing state on the browser. So, the address bar is updated to match the specified URL without re-loading the page. There are lots of libraries available that do all of this for you.
Using pushState for user experience with infinite scroll
As the user scrolls down the page, the visible URL changes and new content is loaded using an Ajax method. It’s because new content is loaded (infinite scroll) that the ideal way to handle the address bar is to update the visible URL.
That way, a reader can share the right thing or return to the right place.
The SEO challenge
When you’re working with sites that are JavaScript heavy (with Javascript SEO for Angular / React etc being my most extreme example) it’s easy to forget that search engines are still somewhat dependent on the non-JS version of your code.
If we can’t pull more content because JS isn’t loaded, if the content we’re hoping to display isn’t visible, if links can’t be crawled because we’re not a JavaScript-enabled browser then all of the classic SEO problems apply.
Of course, your solution is to be mindful of the non-JS experience you’re serving.
Taken to its conclusion, applying the principles of graceful degradation in the early stages of layout, design and code go a long way dealing with that.
Unfortunately, our Omega Watches example doesn’t appear to play well initially for SEO. In JS disabled mode (I’m using the Disable Javascript extension for Firefox), the products and paginated links are obfuscated.
The links are in the code, however, so this is a very simple fix:

Although rel=”next” and rel=”prev” are missing from their paginated series. A simple Google query reveals there’s a problem here with duplicate content. At least the paginated pages are being indexed:
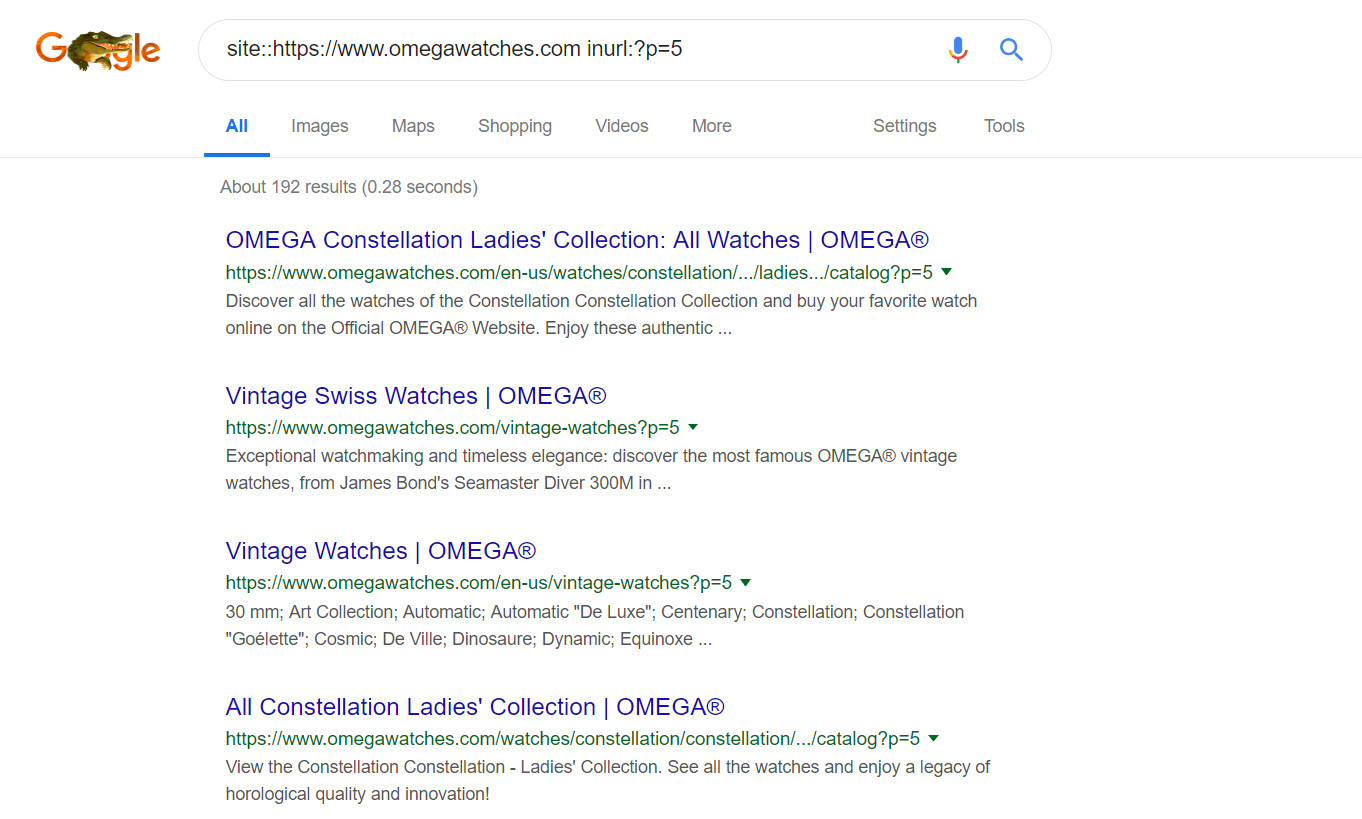
Very little would need to be done here to improve the SEO of those pages. The impact that rel=”next” and rel=”prev” has is actually astonishing, the right Google queries expose no more than just the first category page in the series indexed, without the use of anything like noindex. Very powerful indeed.
Useful resources and further reading
Infinite scroll search-friendly recommendations
Complexities of an Infinite Scroller
https://developer.mozilla.org/en-US/docs/Web/Guide/API/DOM/Manipulating_the_browser_history – Manipulating the browser history
https://blog.twitter.com/2012/implementing-pushstate-for-twittercom – Implementing pushState for twitter.com
https://tumbledry.org/2011/05/12/screw_hashbangs_building – Screw Hashbangs: Building the Ultimate Infinite Scroll
