Getting started
Configuring a site for crawl is simplified down into 4 easy steps, the second of which includes the option to hook up data from a variety of sources:
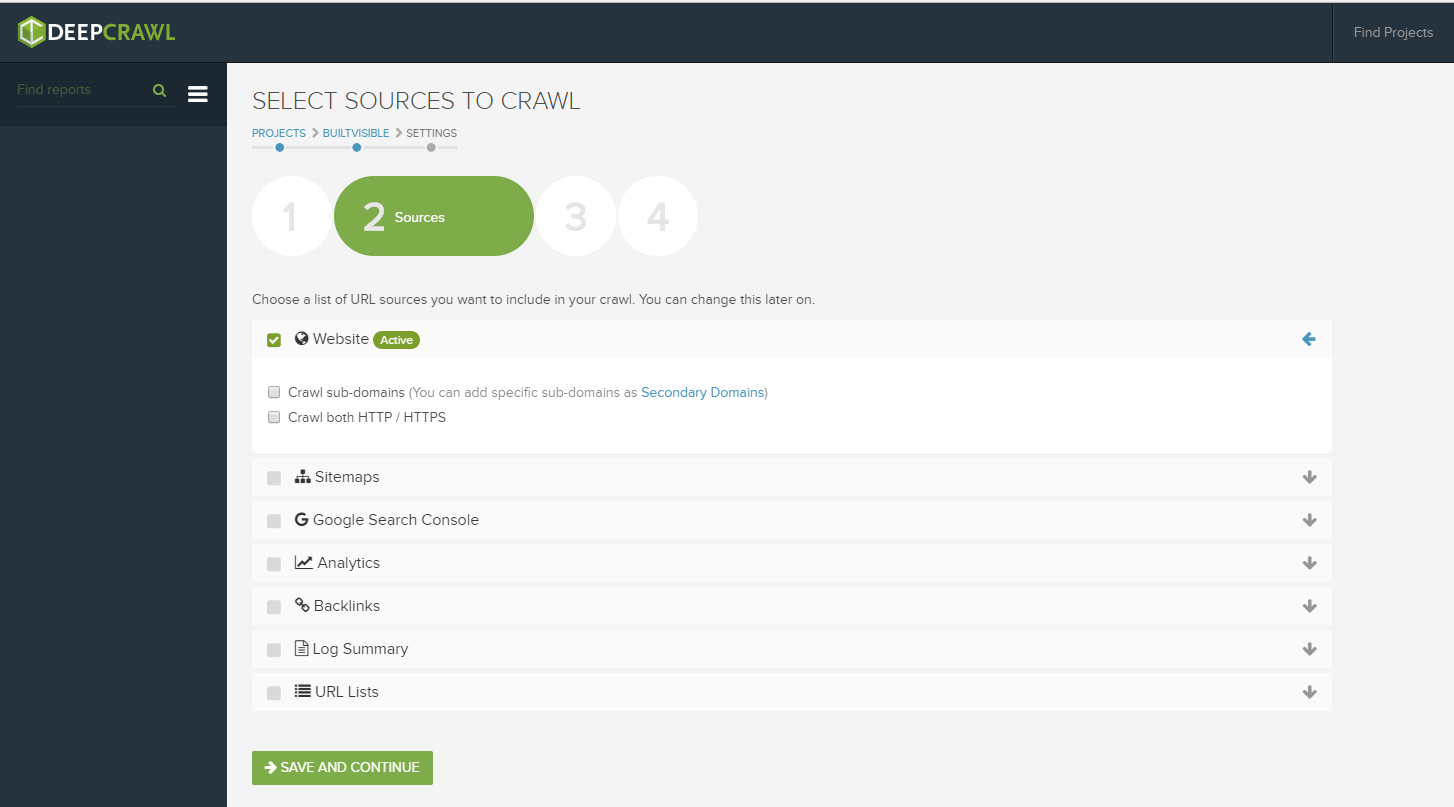
To supplement your crawl, data can be automatically retrieved from XML sitemaps, Search Console, Google Analytics, Backlink data, a simple URL list or your own log file data. Everything you really need to conduct a thorough technical analysis all in one place!
The platform is already configured to work with common output files including those from popular tools such as Majestic, Ahrefs, OSE, or if you’re working with a more custom data file you can upload the basic elements using the CSV template provided.
In terms of log files, DeepCrawl unfortunately cannot process log files directly yet and requires exports from other log analysers in a URL summary format to begin its analysis. However, I’m always happy to open up the SF log analyser so that’s not a drawback by any stretch, and DeepCrawl have simplified the upload process by aligning with the summary exports typically provided by the likes of the SF log analyser, Splunk, and Logz.io.
Once you’re happy with the usual config options and begin a crawl you’ll see the same real-time progress dashboard and will be notified upon completion.
The dashboards
If you head to the log file overview dashboard once the crawl has been finalised you’ll be presented with something like this:
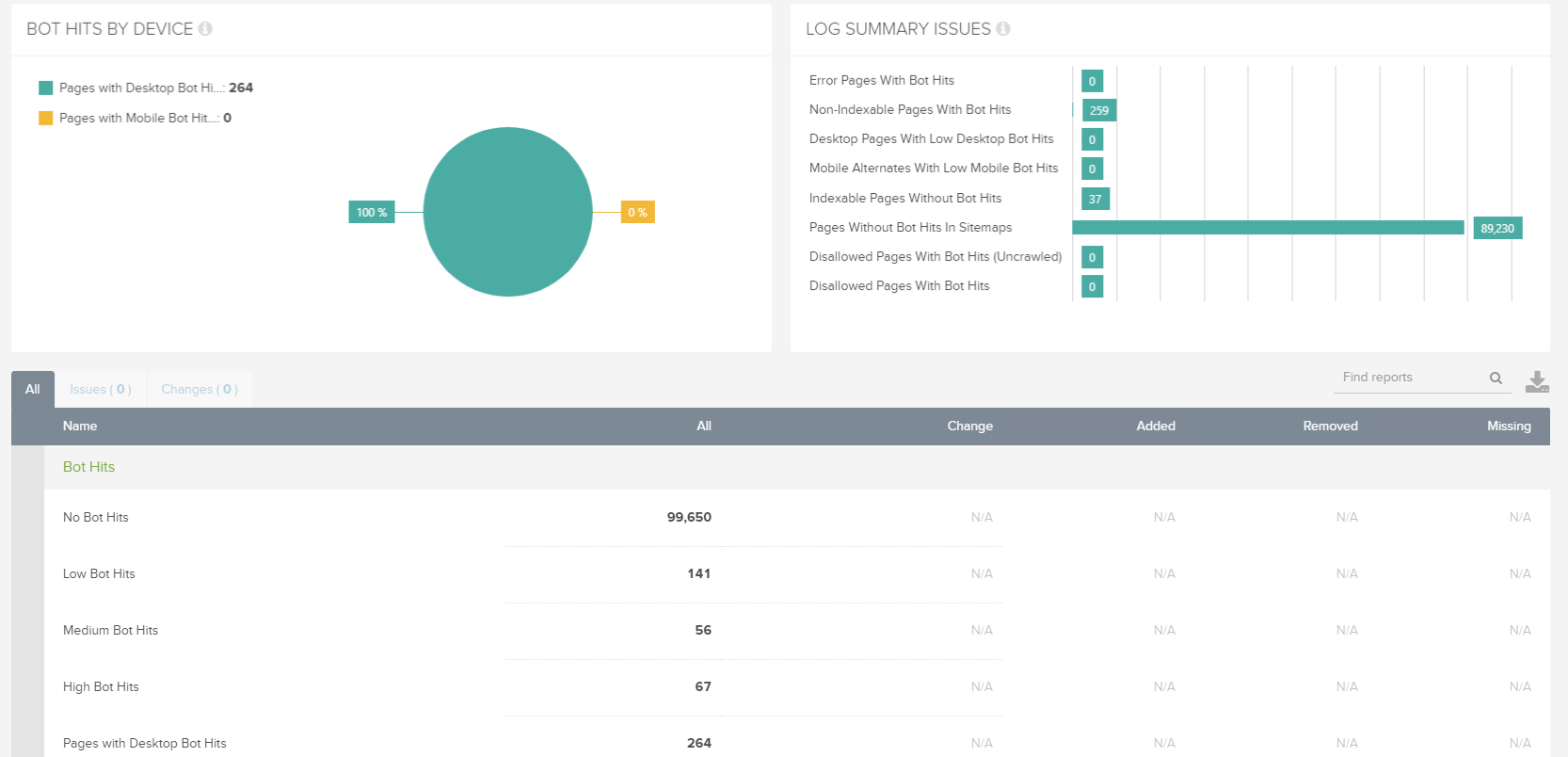
The first chart shows a quick breakdown of all requests by desktop and mobile user-agent (if applicable), along with a visualised summary of key issues and a more detailed data table populated with a full list of issues encountered during crawl, each of which can be mined further for more information.
What makes this data so powerful is that it draws and analyses data from all the sources provided at config and then overlays log data to help identify and qualify different types of error:
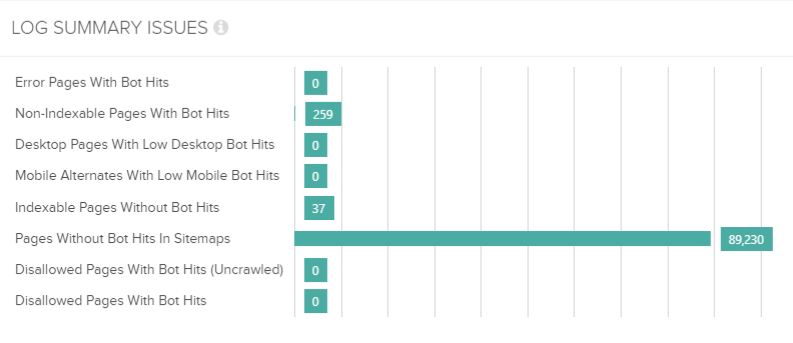
Crawl budget utilisation is so important, especially if you’re dealing with a large website. In the example above we can see that most URLs contained within the XML sitemaps haven’t been requested at all, even though our log sample was based on a month’s worth of data.
This data may indicate a lack of internal links within the site architecture, an architecture that is so deep that search engines cannot reach the deepest tiered content, or more simply that the XML sitemap is out of date and no longer reflects active URLs.
This isn’t simply a crawl report of URLs and associated properties, it’s converting the crawl into something tangible that can be actioned quickly.
Drilling deeper
The deeper analysis is split into two views ‘Bot Hits’ and ‘Issues’.
‘Bot Hits’ broadly categorizes the requested URLs based on the number of requests made within the log file provided, along with views to split desktop or mobile requests:
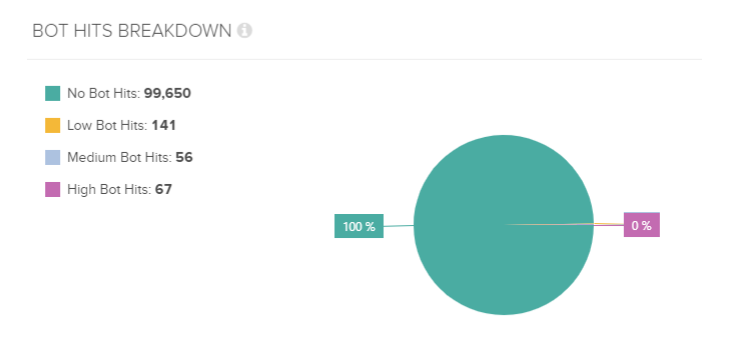
These views allow you to see exactly where search engine crawlers are spending the majority of their time and in turn help to pinpoint errors that are burning unnecessary crawl budget, or conversely identify areas of crawl deficiency (potentially out dated, thin, or orphaned pages).
Once you’ve identified an error you can use the filters provided to dig deeper for additional URLs affected by the same problem, or export to Excel and manually manipulate as required.
‘Issues’ is where DeepCrawl guides you through the data to identify issues that may be affecting your domain, along with providing some details on specific errors again through the log file data:
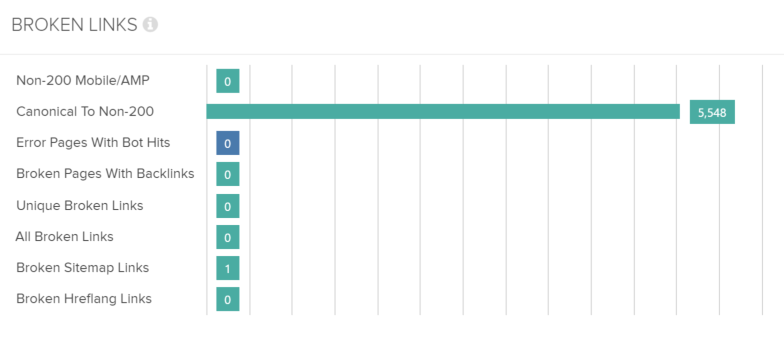
Error Pages with Bot Hits
This view provides a list of URLs encountered within the log files that return a 4XX or 5XX server response code, along with details on all the links encountered within the wider site crawl that point to them:
Non Indexable Pages with Bot Hits
This section highlights URLs that have been set to noindex, contain a canonical referencing an alternate URL, or blocked in robots.txt for example yet are still crawled by search engines. The URLs displayed are then sorted based on the number of hits registered within the log file, like this:
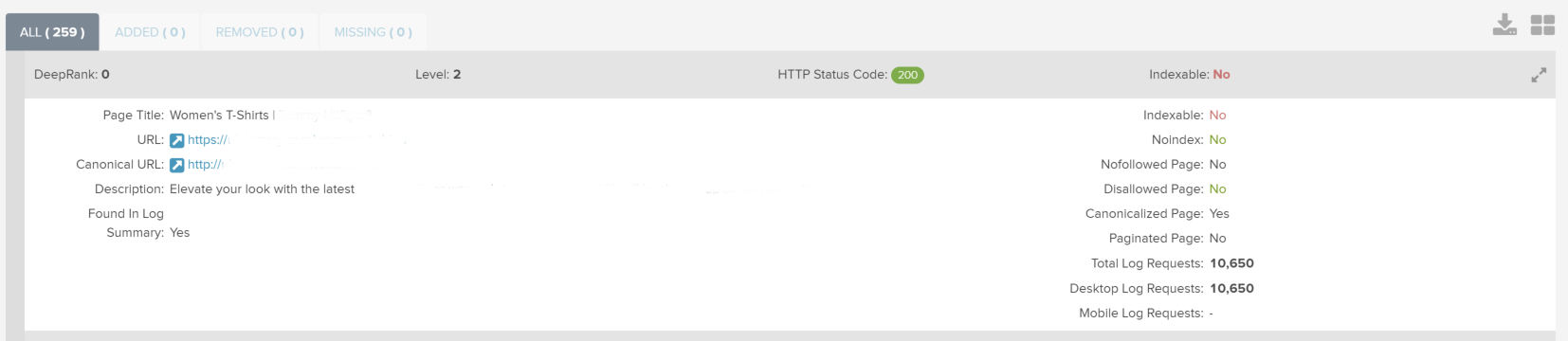
Whilst not all URLs here are necessarily bad, it’s a great way to highlight just how much crawl budget is actually being assigned to specific pages and therefore allow you to question whether the appropriate action is being applied.
Disallowed Pages with Bot Hits
Typically results here will be at a minimum, but just because a URL is blocked in robots.txt it doesn’t always mean there will be 0 requests in logs. This view for example can be useful for locating URLs that remain indexed despite being blocked in robots.txt and are likely missing a ‘noindex’ tag, or a strong enough signal for search engines to drop the pages from its index.
Indexable Pages without Bot Hits
Based on URLs from the log files, site crawl, link data etc provided at set up, we can quickly see a list of URLs that have not generated any requests from search engines in the log files provided. This view will ultimately depend on the extent of coverage and depth of the log file data, however for the majority of small – medium sized sites this view will display what are likely orphaned pages (those with very few or 0 internal links).
Desktop Pages & Mobile Alternates with Low Bot Hits
The remaining two dashboards break down the user-agents between mobile and desktop to understand whether the appropriate page is being served to the corresponding user-agent. This view is particularly useful for sites utilising a standalone mobile site, for responsive and adaptive sites this presents another view to drill into lower requested (likely old, thin or irrelevant) URLs.
Verdict:
An incredibly powerful tool that compares and analyses crawl errors based on the full breadth of data readily available to most SEOs and digital marketers. Whilst an integrated log parser would have been useful given the size of the data we’re typically working with, there’s no single better tool out there for handling scale (and that’s coming from a huge fan of Screaming Frog!). When log data is combined with the standard DeepCrawl toolkit and stored for comparison in the cloud. It’s not only easily accessible but hugely flexible to the needs of its users.

Max
Have you compared how the the log analyser part of deep crawl comperes to Botify or oncrawl.
Actually I would like a post where every feature of Deepcrawl, Botify and Oncrawl are compared.
Daniel Butler
Hey Max, looking forward to reading the post ;)
Filip Zafirovski
Thanks for the share Daniel!
Do you strictly use deepcrawl for these purposes, or do you have other tools on your “menu”?
Daniel Butler
Hey Filip, this is just one tool in the arsenal it really depends on what you’re trying to achieve. I’d have DeepCrawl to handle scale and the ability to easily compare crawl on crawl over time, and Screaming Frog to follow up on more granular details and checks as required.
Maurice
Log Parser Lizard (https://www.lizard-labs.com/log_parser_lizard.aspx) is another tool for log extraction if your not a CLI/Perl Wizard.
Daniel Butler
Thanks Maurice, will check it out.
Mikael Soerensen
Great read ! :-)
I use SF my self but, i better check this out then haha.
Sahar
Grate poset, it´s nice to read somthing new about online and Google. thanks for sharing :)
Search My Websites
Excellent Article on DeepCrawl..!!
Awesome topic and awesome points you have covered here.
Thanks for this post.
Zjakalen
Nice article! Thank you for sharing awesome material :-)
Chris Lever
I’ve got a question, let’s suppose you’re blocking sections of your website in the Robots.txt, yet many URLs are showing up in the index.
Would that contribute towards your crawl budget?