What exactly are log files?
Every time a user or bot performs an action on a page of your domain, the server will create a log of that action, adding a new line to the file. An action occurs every time a request is made by either a user or a bot for any resource on your site, including pages, images, or JavaScript files.
Each log stores a lot of valuable information including status code returned by the server, user-agent that made the request, its IP address, time stamp and much more.
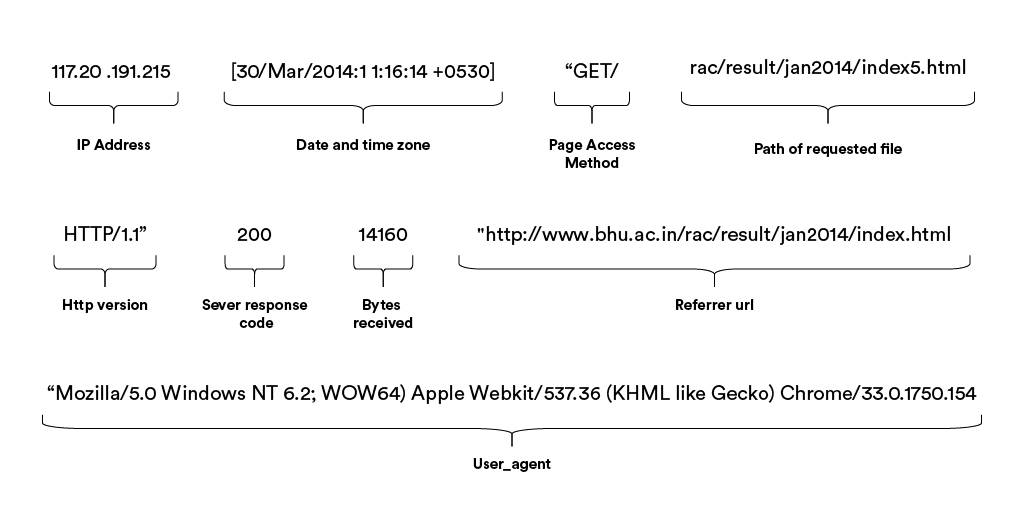
This can be used by developers to spot and fix malfunctions across networks and operating systems, and can also be very valuable for SEO auditing.
What is a log file analysis?
Log file analysis is the dissection and analysis of these logs, to determine crawlability and indexation issues on your site, which might be negatively impacting the performance of your key pages.
They are the only way to get an accurate picture of how Google is crawling the site, meaning you don’t need to rely on less accurate crawlers and incomplete Google Search Console data to get a picture of it. Instead, the log file analysis allows us to see what Google is crawling, how frequently, and any issues being encountered.
Is log file analysis right for me?
All websites can benefit from a log file analysis, as it will always provide a unique insight into how Google crawls your site. However, depending on the type of website you’re running and the technical state of it, conducting a log file analysis may be more impactful to you than others.
For example, large sites such as most ecommerce domains, can be a huge challenge to monitor and manage to ensure key pages are crawled efficiently and that key revenue-generating pages aren’t experiencing any issues. Having log files to look at means you can simply see where Google may be prioritising or deprioritising its time, and fix it to ensure all high value pages are crawled effectively.
Similarly, many news, magazine or ecommerce sites frequently add new pages, and update existing or remove old content. Having such a dynamic site ensures the brand is both providing accurate information to the user and maintaining a positive user experience on site. It’s therefore vital that we understand how quickly Google is discovering these changes and make the necessary fixes to make these changes more discoverable.
How often?
The next question that you should consider is how often you should look at your logs. Often, with our clients, log file analysis is conducted consistently every 12 months (depending on how static their site content is) to both validate the work an SEO is doing and indicate where further improvements can be made. If you work inhouse, it would be beneficial to put an integration in place so that logs are automatically piped to your tool/dashboard of choice for ongoing monitoring.
Log file analysis can positively impact your revenue
Ultimately, the goal with SEO is to generate traffic and revenue. Ensuring your traffic and revenue-generating content is visible and regularly crawled will have a significant impact on the ranking ability of your pages.
For example, if a site has a number of revenue generating pages, but you’ve noticed some perform below par without any obvious reason why, log files can often provide the answer.
Similarly, log files can highlight site-wide errors that may be impacting the authority or trust a search engine has in a site. By looking at logs, you may discover that your page retirement plan isn’t working as Google continues to crawl retired or empty pages. This may be because some links haven’t properly been removed from the site, meaning they continue to be crawled. The extent of this issue can only be discovered by looking at the logs, and fixing it could improve the authority passed to priority pages on your domain, leading to an increase in both traffic and revenue.
Conducting a log file analysis provides invaluable insight to improve your organic visibility
Log files can provide insight into issues that may otherwise be missed. It can answer questions such as:
What pages are search engines prioritising?
Understanding how search engines are prioritising not just the subfolders, but the pages themselves, can be hugely insightful. It can highlight any differences between subfolders or product categories.
If a search engine is crawling a subfolder far less than another, it may suggest that a subfolder isn’t prominent enough for a search engine to consider important
While this isn’t technically an “issue”, it does flag a missed opportunity as it shows an important area of the site is performing significantly worse than other areas or products of equal importance. This may lead to a change in strategy to redress the balance.
Additionally, a log file analysis can highlight any correlation with crawl depth. Recently, our team conducted a log file analysis on a major ecommerce brand, and the data showed there was a direct correlation with the number of requests and the crawl depth of a URL. Specifically, it highlighted that there were almost no requests for URLs that were too deep in the site architecture, which was significantly harming their ability to perform and drive revenue to the site. This level of insight is invaluable and will shape our strategy over the next 12 months.
What is Google ignoring that may be driving revenue loses?
Whilst Screaming Frog or Oncrawl can be fantastic tools for many things, it’s important to remember that these crawlers can’t mimic Googlebots behaviour exactly; Google doesn’t follow everything you tell it to do to the letter, and it often uses its own intelligence to determine what’s important and what isn’t.
For example, as you might already know, there are “hints” and there are “directives” that Google follows. The directives are followed to the letter. An example being the robots.txt file. Google won’t crawl any pages that fall into any of the disallow rules in the robots.txt file (though they may index the page if they arrive on a disallowed page from a third party domain, but let’s not dwell on that just now).
A hint on the other hand just gives a strong suggestion to Google that it should crawl the site in a particular way. Canonicals are a good example of those as Google will most likely follow these quite closely, but they don’t have to (and they often don’t). In fact, we’ve seen many times Google ignoring them if there are too many mixed signals on the site (such as internal links pointing to canonicalised pages).
In a recent tech audit we completed, it was discovered that canonicalising colour variations to a “master” colour in an attempt to reduce cannibalisation and duplicate content issues, was contributing to a significant waste in crawl budget:
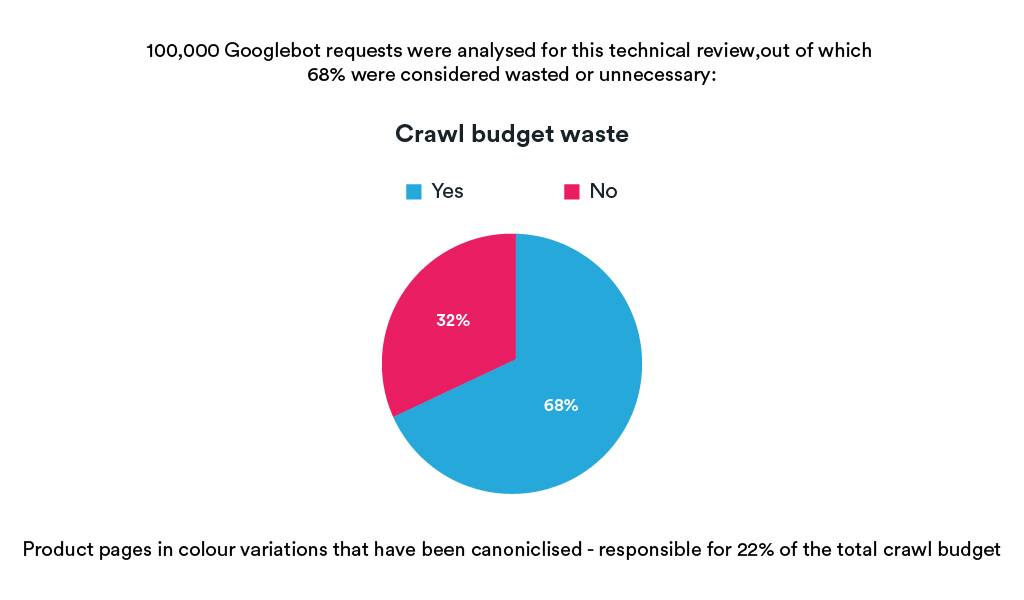
This is a perfect example of why log file analysis is so important. Only by looking at the log files can we determine whether Google is following the hints we’re providing or not.
Log files can also highlight how Google is interacting with expired content. For example, the logs may show Google continues to crawl pages that were removed 12 months previously and this may highlight a need for a change in retirement strategy.
How many crawled pages are actually being indexed?
One of the key elements of a log file analysis is understanding how efficiently the site is being crawled. While there are inevitably going to be redirects and 404 errors included in the logs if the site is updated regularly, the logs will also highlight any major issues that would largely go unnoticed without them.
For example, we currently work with an ecommerce brand that use the following rule in the robots.txt file to block any crawling agent from crawling the price parameter:
Disallow: /*?price*
Despite the above rule, when analysing the logs, it showed that price was the most frequently used parameter in the log files, and almost none of these URLs were indexed at the time. This was eating into a significant chunk of the crawl budget and potentially preventing a more valuable URL to be crawled.
Through this discovery, we could begin researching where the error was sitting and quickly determined the robots.txt rule was missing a simple asterisk, resulting in a huge number of URLs with the price parameter continuing to be crawled and that the rule should be changed to the following:
Disallow: /*?*price*
Now, some of you may already notice where the error in the above rule is, but if you can imagine this tiny mistake sitting on a site with 1m+ URLs and 150+ rules, it can be hard to spot, and determining the size of the problem is almost impossible without the log files.
Avoiding crawler traps
Similar to the above, crawler traps can result in a large portion of the crawl budget being used on parts of the site that are either not indexable or provide little to no value. This can include:
- Internal parameters that aren’t stripped when navigating the site.
- Wrongly implemented pagination that leads to page requests that either don’t exist or contain no content.
- No facet control – ecommerce sites that use multiple facets to create their product listing pages have to have some limitations to what is accessible to a robot, otherwise an unlimited number of pages may be accessible.
- Internal search pages.
By looking at the log files, we can diagnose the problem and start working on a solution to eradicate the crawl trap before it’s too late.
Are the revenue-generating pages or folders visible enough on my site?
Sometimes, log files can provide insights that aren’t necessarily considered “errors”. For example, we might simply want to know how often category X or page Y is crawled relative to the rest of the site, in order to improve the efficiency of our crawl budget and ensure we are making the most of it.
As you might already know, Google often makes its own priorities based on various signals such as:
- Sitemaps – while Google doesn’t always follow these, it will often use them as a signal that the webmaster sees these pages as a priority.
- Internal links – If a page or category is linked to often, it’s a signal that page or category is an important part of the site.
- Site structure – in general, the further down the architecture, the less likely the page is to be crawled and indexed. This is heavily tied to the internal links signal mentioned above, as pages further down the architecture tend to be linked to less.
By looking at your log files we can see what sections Google may be deprioritising, and subsequently look at why that might be.
For example, when looking at the logs, you may discover that Product X is crawled much less frequently compared to other products, despite still being a key, top revenue-generating product. This discovery will allow us to quickly start looking into why that is and how you can fix it. For example, it may be that while the product is included in the navigation bar, there are very few contextual links across the site, meaning the page is discovered less and sits lower on the priorities list for Google.
How do we conduct a log file analysis?
To conduct a log file analysis, we request at least 2 weeks of data (ideally 4 weeks). This is then parsed to remove all logs that aren’t Googlebot (including fake ones) and any external data sources such as Screaming Frog crawls, Google Search Console data and Google Analytics data are combined into one.
Once the log files are prepared, we begin analysing the contents. This includes collecting data such as status code responses, URL folders data and crawl frequency. To ensure the analysis is digestible to everyone, the analysis is summarised in a written document, along with prioritised actions, simple charts and graphs to showcase the data.
To read more about how we analyse log files, read Dan Butler’s guide to log file analysis.
Next steps
As you can see, there are a whole host of reasons why log file analysis is a very important and insightful project to complete for any brand, and will give you a competitive advantage in understanding exactly how search engines are interacting with your pages.
This level of insight can be a major contribution to your organic strategy going forward and drive your priorities list to ensure resource is spent in areas with the greatest impact on traffic and revenue, so that you can maximise your ROI.
My colleague Dan Butler covers this in much more detail on his amazing guide to log file analysis which you can find below, and to understand more about how we do this here at Builtvisible contact us here.