How does the Command Line help in SEO?
Using the command line for SEO can help you more easily to identify file structure when you want to manipulate data, verify status code when the site is using a service worker and split huge files into more manageable chunks. It can aid you with downloading and transferring data directly to a server, and you can also use it to search for a specific string of characters in a large file, and slice data by fields and output to a new file. This is just the tip of the iceberg too!
In this guide specifically, we’ll cover how to navigate a file system without relying on a Graphical User Interface (GUI), and how to create and modify files and directories, manipulate data, and even interact with the web.
You’ll learn the commands for:
- Changing Directory
- Listing Files
- File
- Making Directories
- Moving Files & Directories
- Removing Files & Directories
- Touch
- Copy
- Head & Tail
- Concatenate (Cat)
- Word Count
- Grep
- Sort
- Split
- Cut
- Stream Editor
- Awk
- Curl
- Wget
- Clear
What is the Command Line?
A command line interface – also known as a terminal, command prompt, or console – is a text-based interface that can be used to interact with a computer’s operating system (OS). CLI’s predate the introduction of graphical interfaces; it’s a living relic of our not-so-distant past, when commands had to be typed out in order for you to navigate and activate a computer’s files.
So what possible advantages can be gained from learning to master this archaic method of interaction now for SEO? Fair question! There are definite advantages to using a command line instead of a GUI, including:
- Speed: A GUI is effectively a presentation layer that sits on top of a CLI to make things more user-friendly. Ultimately, this means that it will never be as fast, and performing tasks can take significantly longer.
- Necessity: Sometimes it’s only possible to interact with a remote server via a CLI. The same is true for running scripts unless you go to the extra effort of creating a GUI.
Accessing the Command Line
The way in which you access the command line is heavily dependent on your operating system. On Mac, command line is called the terminal, and you can find it under Applications > Utilities. On Windows, command line is the command prompt and can be located by searching cmd in the navigation bar. It’s important to note that Windows and Mac/Linux differ on many commands, both by name and functionality. This is because Mac and Linux are both UNIX-based operating systems, whereas Windows is… well… Windows.
We’ll be focusing on UNIX, as the command line is far more developed than the Windows equivalent (unless you use PowerShell) since Windows has always heavily focused on its GUI.
If you’re a Windows user, to follow along, you’ll need to either:
- Enable Windows Subsystem for Linux.
- Install an emulator such as Git Bash or Cgywin.
Move your business forward with content marketing
Enhance your online visibility, reach new customers, and drive sales with this all-in-one content marketing toolkit.
The images in this post are all of Git Bash, which I’ve always used, but your mileage may vary.
What’s the difference between the Command Line and Shell?
One final nuance worth explaining is the difference between the command line and shell. A command line is essentially an interface that is used to send commands and display the output, whereas a shell is the interpreter that sits behind it and processes the commands.
UNIX has a range of different shells available, Bash being the most commonly used (and historically, also the default shell on macOS, until it was switched to Zsh in 2019 when Catalina was released).
Got it? Great, let’s dig in.
Note: Square brackets in the examples below signify a placeholder. They are not part of the commands.
Navigating Files & Directories
Loading up a non-Windows CLI for the first time can be intimidating. As well as being entirely text-based, it provides limited information on your current working directory — in other words, where you’re presently located. To find this out, enter pwd (print working directory):
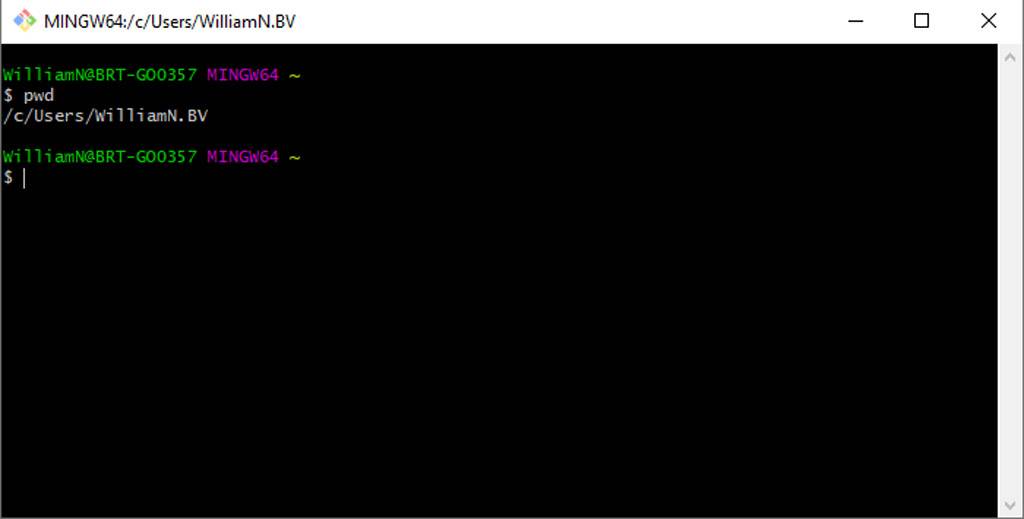
In my case, you can see my home directory – indicated by the tilde (~) – is /c/Users/WilliamN.BV.
To make running scripts and command line utilities easier, you’re best served storing files inside child directories within your home directory. This makes navigating to the files you require as easy as possible.
Changing Directory
Cd (change directory) is one of the most commonly used commands and is universal across both Windows and UNIX operating systems.
- To navigate to a directory within your current directory, simply type: cd [directory]
- To access a subdirectory that sits below this, input the file path: cd [directory]/[sub-directory]
- Need to go back to the directory you were previously in? Navigate to it using a hyphen: cd –
On a UNIX based OS, the directory you are currently in is represented by a singular dot, so specifying ‘cd.’ will run but do nothing.
Two dots, however, is representative of the parent directory and can be used to efficiently navigate to directories above your existing location.
- Navigate to the directory above your current directory: cd ..
- Navigate two levels above your current directory: cd ../../
- Navigate to a directory within the directory above: cd ../[directory]
As an example, I have a “Public” folder within /c/Users and can navigate to it by inputting ‘cd../Public’
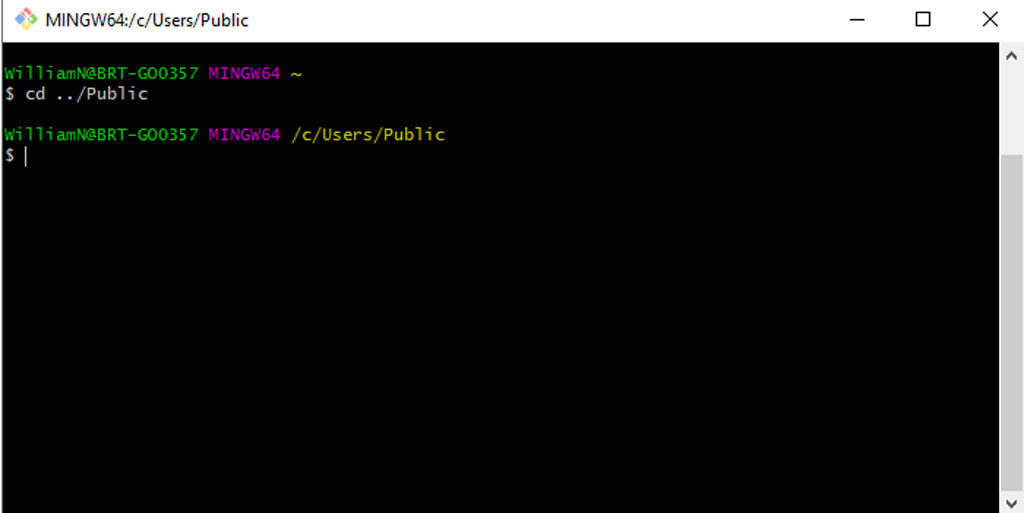
One final thing to note is that directories with spaces in the path need to be escaped when using cd. The easiest way to achieve this is to wrap the folder in quotation marks or apostrophes: cd ‘my directory’
Listing Files
So far, we’ve managed to work out where we are in our directory tree and navigate around it, but what if we don’t know where specific files and directories are located?
In those instances, we need to use the list command: ls [directory]
The exact formatting will vary, depending on the command-line interpreter you’re using, but there is almost universally some differentiation for different file types. As you can see in the image above, directories are blue in Git Bash and have a trailing slash.
- List the contents of a subdirectory: ls [directory]/[sub-directory]
- List only directories in your current directory: ls -d */
- List the contents of a directory and its subdirectories: ls *
- List a specific type of file using pattern matching: ls *.[file-extension]
Options
Up to this point, we’ve gotten by with minimal optional argument usage, as the commands we’ve been running have been relatively simplistic. But many commands, such as list, have numerous valuable options that can be specified to modify how a command functions. The easiest way to find these out for a command is to type: [command] –help
Useful options for ls include:
- Show all hidden files (which feature a dot before the name): ls -a
- Display the size of files: ls -l
- Display files in the long listing format (file names, permissions, owner, size and time/date modified): ls -l
- Sort by file size: ls -S
- Sort by modification time: ls -t
- Sort by extension: ls -X
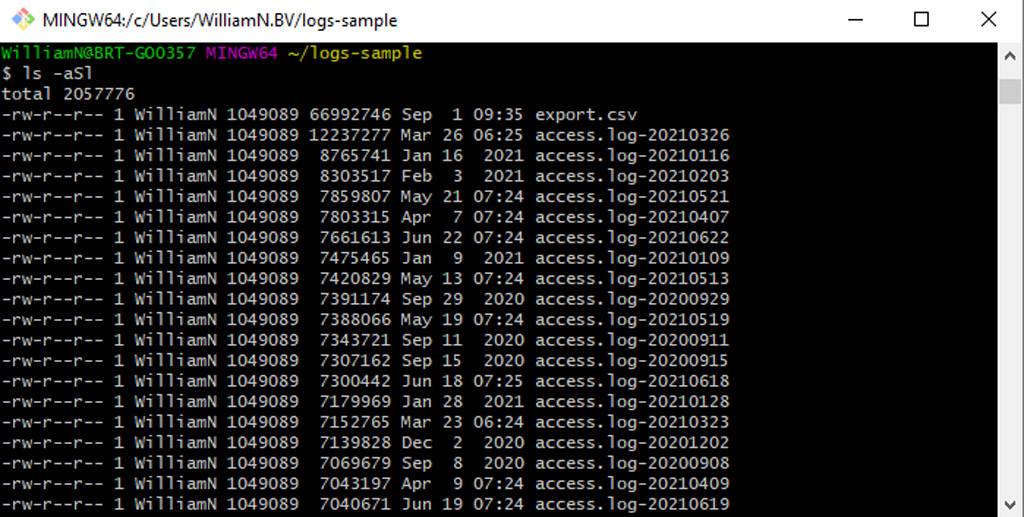
It’s also possible to stack up options if you desire, either by combining these into a singular argument or specifying multiples. For example, inputting either of the following will display files – including hidden files – in long listing format, sorted by size:
- ls -aSl
- ls -a -S -l
File
While ls in long listing format provides high-level information on individual files, it doesn’t provide detailed information about the file type. This is where the file command comes in.
- Find the human-readable type of a file: file [file-name]
- Find the file types for an entire folder: file *
- Find the file type for a specific extension: file *.[file-extension]
- Find the mime type for a file: file -i [file-name]
A good SEO use case for the file command is identifying whether CSVs are in the expected format. Opening and saving CSVs in Excel can cause havoc with special characters. By using file, it’s easy to establish whether files are encoded with UTF-8, ASCII, or something else. It will also highlight the presence of any BOM characters, which can potentially invalidate a robots.txt or disavow file!
Creating & Editing
Making Directories
Continually swapping between a GUI and a text-based interface can be a pain. Thankfully, there’s a command for that, too.
- Make a directory: mkdir [new-directory]
- Make multiple directories: mkdir {one,two,three}
- Make a parent directory and subdirectories: mkdir –p directory/directory-2/directory-3
The -p option enables users to define a directory structure and will create any missing folders required to match it.
As an example, if we wanted to create a directory to download some compressed log files, a second directory for the uncompressed logs, and a third folder for Googlebot requests, we could run: mkdir -p logs-new/uncompressed_logs/googlebot_requests
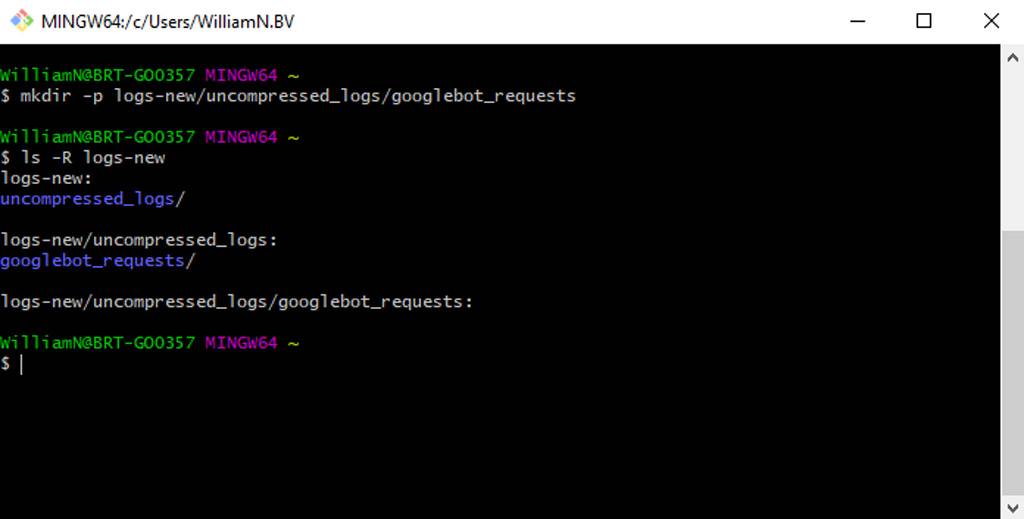
In the image above, Ls -R logs is used to display the created directory tree structure.
Moving Files & Directories
As well as being used to move files and directories, the move command (mv) is also utilised for renaming and is therefore well worth remembering to avoid more pesky clicks.
- Move a file: mv [file-name] [directory]
- Rename file: mv [file1] [file2]
- Move multiple files: mv [file-1] [file-2] [directory]
- Move directory: mv [directory-1] [directory-2]
- Move files with a specific extension: mv *.[file-extension] [directory]
Add the -i parameter to provide a prompt before overwriting an existing file, and -n to prevent a file being overwritten. Shortcuts like the tilde and dot operators that we learned earlier can also be leveraged to move files and folders up the directory structure.
Removing Files & Directories
Very much the inverse of the move command is the remove command (rm), which is an easy one to remember because the syntax is almost identical. A remove directory command (rmdir) also exists, but this isn’t especially helpful because it only works on empty directories.
- Remove a file: rm [file-name]
- Remove multiple files: rm [file-1] [file-2] [file-3]
- Remove multiple files with a specific extension: rm *.[file-extension]
- Remove an empty directory: rm -d [directory]
- Remove a non-empty directory and files: rm -r [directory]
Again, the -i parameter can be specified to provide a prompt before removal on a per-file basis. If three or more files are listed, -i will consolidate this down into one prompt.
Touch
The touch command can be used to modify timestamps and create empty files.
- Create a new file without any content: touch [file-name]
- Update a files last accessed time: touch -a [file-name]
- Update a files last modified time: touch -m [file-name]
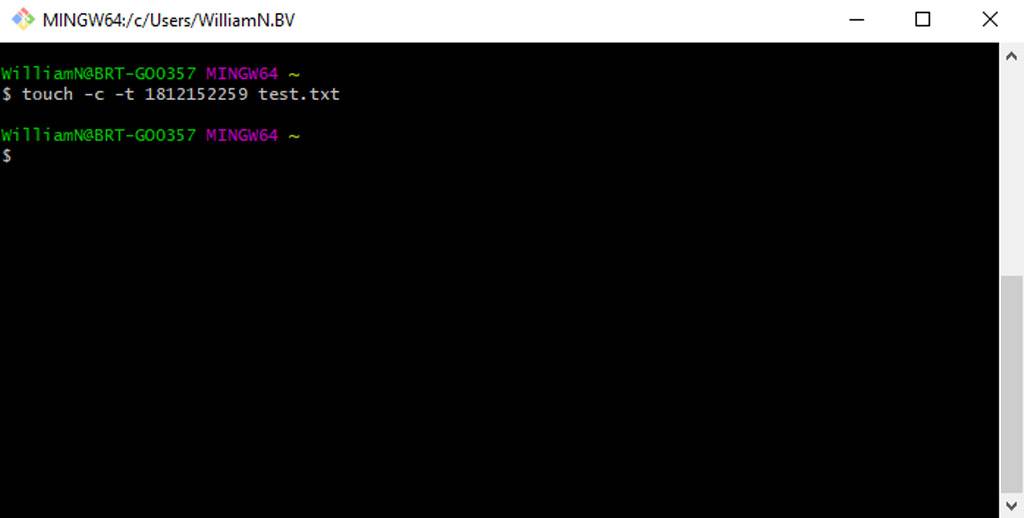
- Set a specific access and modification time: touch -c -t YYDDHHMM [file-name]
Copy
On a UNIX CLI, the copy command (cp) is used solely to copy a file or directory from one place to another. This is worth bearing in mind to those more familiar with the Windows command prompt, where the copy command can also be used to combine files.
- Make a copy of a file: cp [file-name] [new-file-name]
- Copy file to directory: cp [file-name] [directory-name]
- Copy multiple files to directory: cp [file-name] [another-file-name] [directory-name]
- Copy all files to destination directory: cp -r [existing-directory] [new-directory]
- Copy all files with a specific extension: cp *.[file-extension] [directory-name]
Once again, -i can be used to provide a prompt before a file is overwritten, and -n can be used to prevent this entirely.
Displaying & Manipulating
Head & Tail
Large files can take a long time to load when using a GUI – if they load at all…This is where the head and tail commands come in, allowing you to preview the first – or last! – (n) rows of data. It’s incredibly helpful if you’re about to undertake some form of data manipulation but are unsure how the file you are working with is structured.
- Preview the beginning of a file: head [file-name]
- Preview the end of a file: tail [file-name]
Both commands display 10 rows of data by default, which can be modified using the -n option: head/tail -n 5 [file-name].
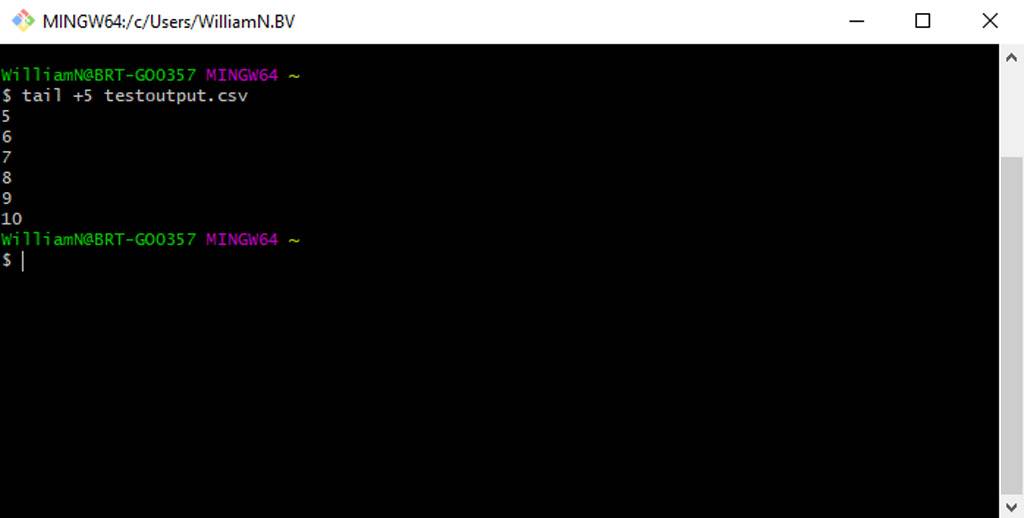
One nuance worth noting is that the tail command comes with a plus option, which prints data starting at a specific line rather than the end: tail +5 [file-name]
Cat
The cat command – short for concatenate – is used to read, combine and write files.
- Print the contents of a file: cat [file-name]
- Concatenate multiple files into a combined file: cat [file-1] [file-2] [file-3] > [combined-file]
- Combine multiple files with the same extension: cat *.[file-extension] > [combined-file]
Above, the redirection operator (>) is what indicates that the output should be saved as a new file (or overwrite the existing file). To prevent the existing data within a file being overwritten, specify >>.
- Concatenate two files without creating a new file: cat file1 >> file2
A good SEO use case for the cat command is when you’re performing link research. Unless you’re using an API, this will entail downloading multiple exports, all of which will have the same format. To combine, pop the exports in a folder and run a cat command with pattern matching on the extension.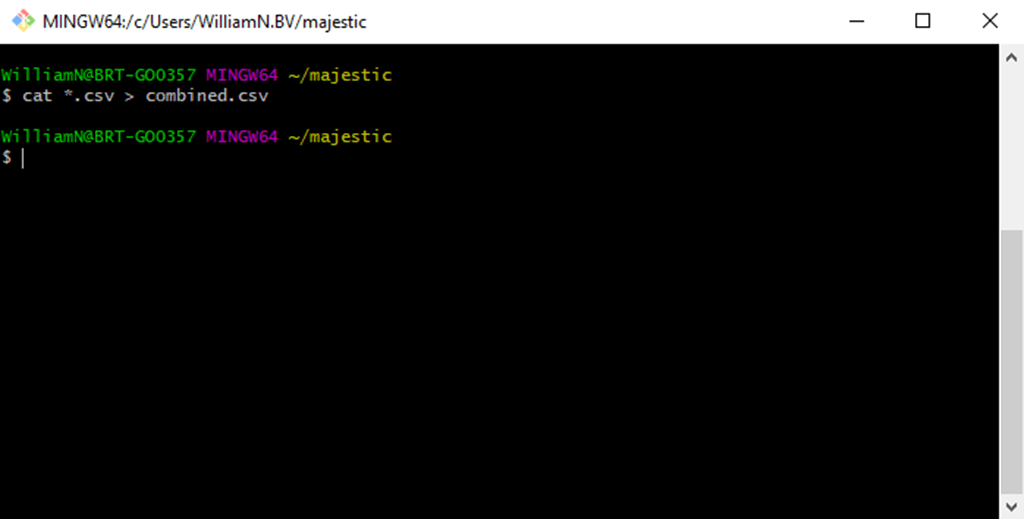
Word Count
More than just a one-trick pony, the word count command also supports the counting of characters and, more importantly for SEO, lines.
- Count the number of words in a file: wc -w [file-name]
- Count the number of characters in a file: wc -m [file-name]
- Count the number of lines in a file: wc -l [file-name]
At this point, it’s important to introduce the pipe command. Rather than being used in isolation, multiple commands can be chained together using the pipe character (|), enabling users to perform more complex operations. When used well, this can be tremendously powerful.
- As a basic example, here’s how to count the number of CSV files in a directory: ls *.csv | wc -l
- Or count the number of lines in multiple files and list the combined total: cat * | wc -l
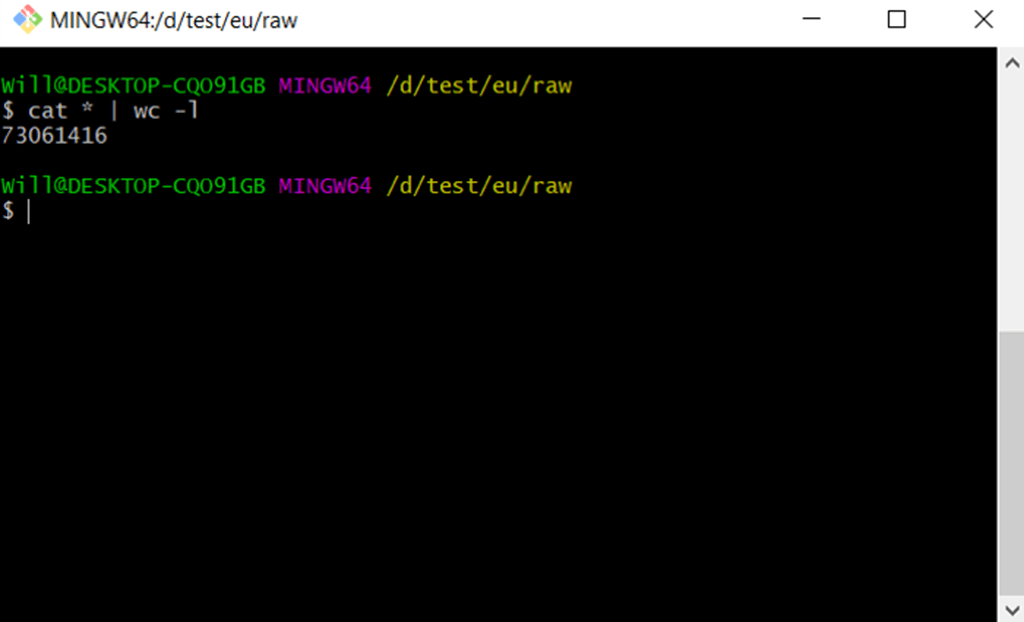
The above shows that a line count on a 73 million row dataset took < 20 seconds.
Grep
The grep command is used to perform a search for a specific string of characters. This is incredibly useful for SEO, where extracting data from large files is an almost daily occurrence. As an example, when parsing log files.
- Extract every line that features a pattern (in this case Googlebot) from a file: grep “Googlebot” [file-name]
- Extract every line that features a pattern from multiple files with a specific extension: grep “Googlebot” *.[file-extension]
- Extract every line that features a pattern from multiple files with a specific extension and write it to a new file: grep “Googlebot” *.[file-extension] > [file-name]
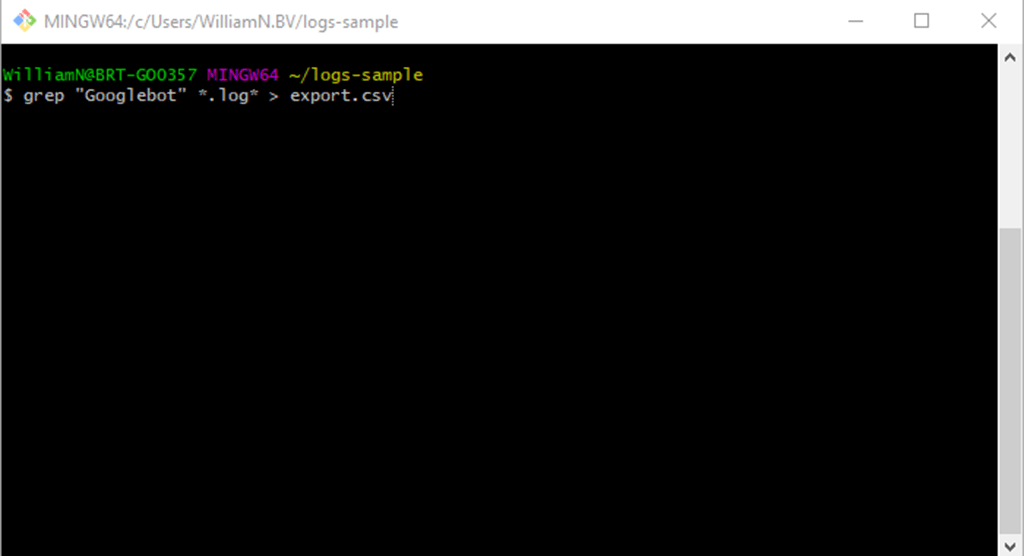
Due to the potential file sizes involved, logs are almost universally stored in one-day increments, so using pattern matching to perform a grep on multiple files is very much the norm.
Grep’s default behaviour in this instance is to prefix each line with the name of the file: access.log-20200623:66.249.73.221 – – [22/Jun/2020:07:05:46 +0000] “GET / HTTP/1.1” 200 75339 “-” “Googlebot-Image/1.0” – request_time=24142
This information is totally irrelevant when performing log file analysis for SEO and can thankfully be removed by using the -h option e.g. grep -h “Googlebot” *.[file-extension] > [processed-file]
Multiple pattern matches can be performed per line by using the pipe command. A good use case for this is when requests for multiple domains are stored in the same location, and you only want one.
- Extract every line that features two patterns from multiple files with a specific extension and write it to a new file: grep -h “domain.com” | grep “Googlebot” *.[file-extension] > [processed-file]
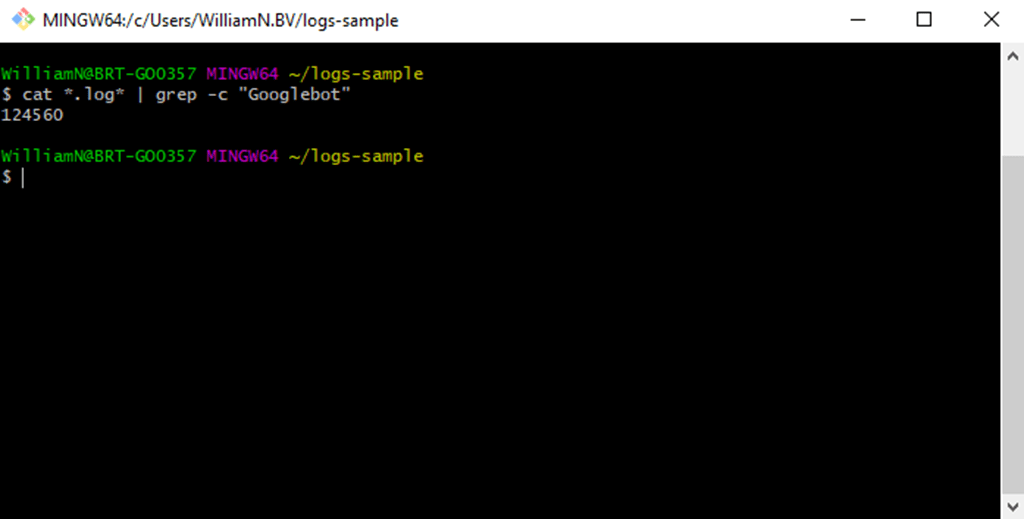
- To count the occurrences of a pattern in a file, use the -c option. It’s worth bearing in mind that this will perform a count per file though, as with wc –1. To get the total matches across multiple files, combine with the cat command: cat *.[file-extension] | grep -c “Googlebot”

- Extract every line that does not feature a pattern from a file: grep -v “pattern” [file-name]
- Extract every line that features a pattern from a file (case insensitive): grep -i “pattern” [file-name]
- Extract every line that features a pattern from a file using Regex: grep -E “regex-pattern” [file-name]
Sort
Of limited usage on its own, sort can be combined with other commands to sort the output alphabetically or numerically.
- Order alphabetically and output to a new file: sort [file-name] > [sorted-file]
- Reverse the order and output to a new file: sort -r [file-name] > [sorted-file]
- Order numerically and output to a new file: sort -n [file-name] > [sorted-file]
- Order alphabetically on the n column (in this instance 3) and output to a new file: sort -k3 [file-name] > [sorted-file]
- Order using multiple columns and output to a new file: sort -k[column-1],[column-2] [file-name] > [sorted-file]
- Sort can also be used to remove duplicate lines: sort -u [file-name] > [sorted-file-unique-lines]
- Or stacked with word count to get a tally of unique lines within a file: sort -u [file-name] | wc -l
Split
Struggling to open something? The split command is perfect for separating huge files into more manageable chunks.
- Split a file into smaller chunks (1000 lines by default): split [file-name]
- Split a file into smaller chunks with a specified number of lines: split -l[number] [file-name]
- Split a file into a given number of chunks: split -n[number] file-name]
- Split a file into smaller chunks with a specified file size: split -b[bytes] [file-name]
Files can also be split based on kilobytes, megabytes and gigabytes:
- split -b 100K [file-name]
- split -b 10M [file-name]
- split -b 10G [file-name]
While the above commands will split a file, they will not automatically maintain the files extension. To do so, use the --additional-suffix option.
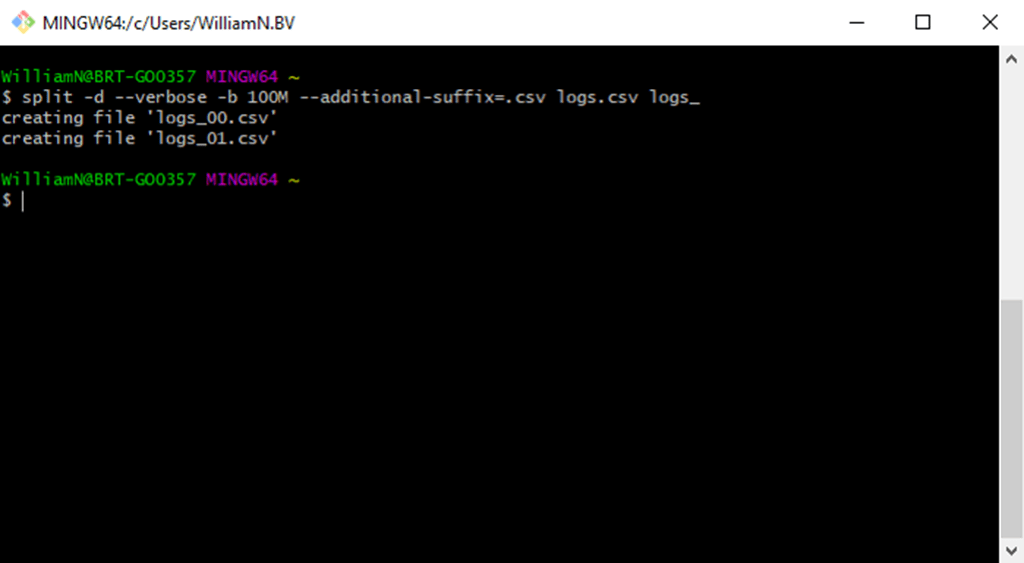
Here’s a more practical example of how to split a large CSV file into 100MB chunks using this option. In it, we’ve also specified the -d option and added a custom suffix. This means that the output files will follow a naming convention of ‘logs_[number]’, rather than alphabetic characters: split -d -b 100M –additional-suffix=.csv logs.csv logs_
When testing a script, it’s often helpful to grab a random data sample from a file. Unfortunately, the split command does not have an option for this. Instead, use shuf: shuf -n [number] [file-name] > [new-file]
Cut
Cut allows you to access parts of the lines of an input file and output the data to a new file. Although it can also be used to slice by bytes and characters, the most useful application for SEO is slicing data by fields.
- Slice file by field: cut -f [number] [file-name]
- Slice file by multiple fields: cut -f [number-1],[number-2] [file-name]
- Slice file by a range of fields: cut -f [number-1]-[number-2] [file-name]
- Slice file by a range of fields (from the selected number to the end of the line): cut -f [number]- [file-name]
- Cut slices using the tab delimiter by default, but this can be changed using the -d option (e.g. space): cut -d ” ” -f [number] [file-name]
It’s also possible to stack multiple ranges together. To provide a more practical illustration, if you wanted to extract specific columns from multiple links files that share the same format: cut -d “,” -f 1,3-5,13-15 *.csv > cut.csv
Sed (Stream Editor)
The sed command can perform a range of useful text transformations, including filtering, find and replace, insertions and deletions.
- View lines within the middle of a document (which isn’t supported by head and tail): sed -n ‘[number-1],[number-2]p’ [file-name]
- Perform a find and replace and save the output: sed ‘s/[find-text]/[replace-with]/g’ [file-name] > [new-file]
- Perform a find and replace save inplace: sed -i ‘s/[find-text]/[replace-with]/g’ [file-name]
- Perform a find, replace with nothing and save the output: sed ‘s/[find-text]//g’ [file-name] > [new-file]
- Find and delete lines with a specific pattern, saving the output: sed ‘/[find-text]/d’ [file-name] > [new-file]
- Find and delete blank lines (using Regex), saving the output: sed ‘/^$/d’ [file-name] > [new-file]
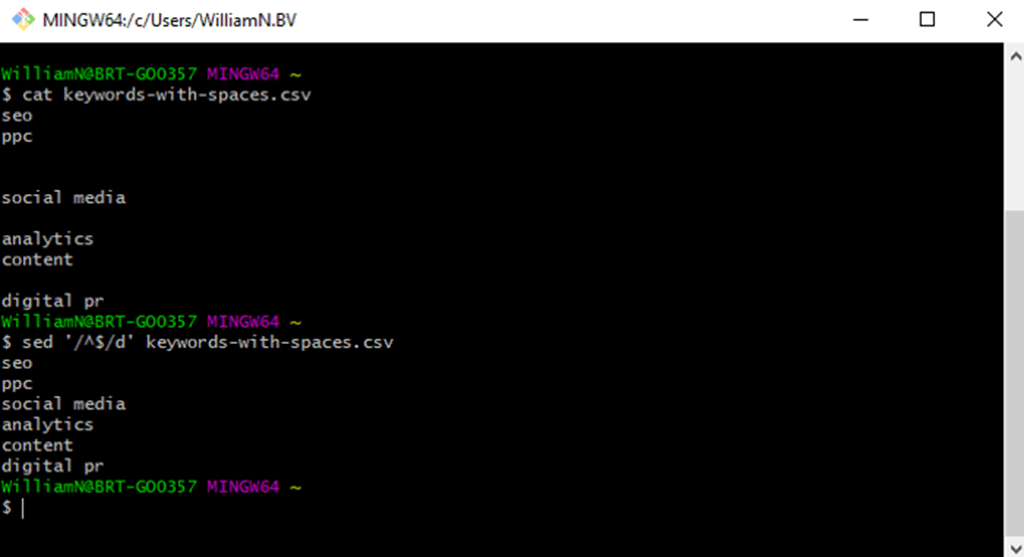
- Delete spaces at the end of lines of text and save the output: sed ‘s/[[:blank:]]*$//’ [file-name] > [new-file]
- Run multiple find and replaces on a file and save the output: sed -e ‘s/[find-text]/[replace-with]/g; s/[find-text-2]/[replace-with-2]/g’ [file-name] > [new-file]
Awk
For really heavy-duty data manipulation using the command line, learn how to use awk. Awk is a scripting language in its own right, and is capable of a range of different transformations.
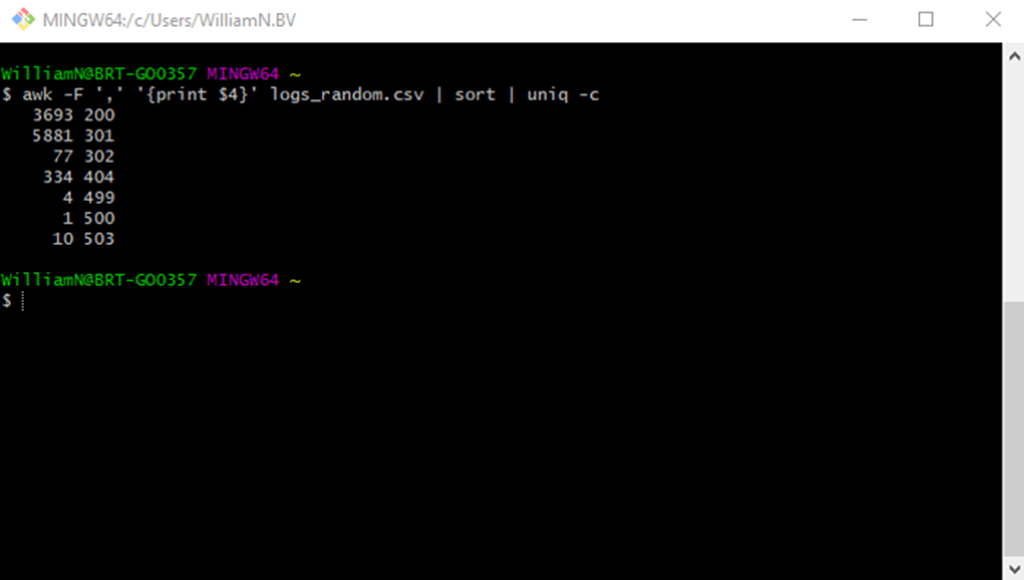
- Count the unique values in a column: awk -F ‘[delimiter]’ ‘{print $[column-number]}’ [file-name] | sort | uniq -c
Below shows count of status codes in a log file.
- Perform a find and replace on a column and save the output: awk -F ‘[delimiter]’ ‘{ gsub(“pattern”, “new-pattern”, $[column-number]) ; print}’
- Filter rows down based on a column meeting a condition (greater than): awk ‘[delimiter]’ ‘$[column-number] > [number]’ [file-name]
- Filter rows down using pattern matching on a column (contains): awk -F ‘[delimiter]’ ‘$[column-number] ~ /[pattern]/’ [file-name]
- Count word frequency within a file: awk ‘BEGIN {FS=”[^a-zA-Z]+” } { for (i=1; i<=NF; i++) words[tolower($i)]++ } END { for (i in words) print i, words[i] }’ *
As you can see in the examples above, the syntax for an awk query is a bit more complex than what we’ve covered previously. Awk supports many constructs from other programming languages, including if statements and loops, but if you’re more familiar with another language, this may be the complexity level at which it’s worth transitioning over. That said, it’s always worth doing a quick search for an awk solution first.
Interacting with the web
Curl (Client URL)
Curl is a command line utility that allows users to download data from, or transfer data to, a server. This makes it incredibly useful for SEO, where we have to continually check status codes, headers and compare server and client-side HTML.
- Get the contents of a URL: curl [url]
- Save the contents of a URL to a file: curl -o [file-name] [url]
- Download a list of URLs from a file: xargs -n 1 curl -O < [file-of-urls]
- Use curl with the -I option to display only the headers and status code: curl -I [url]
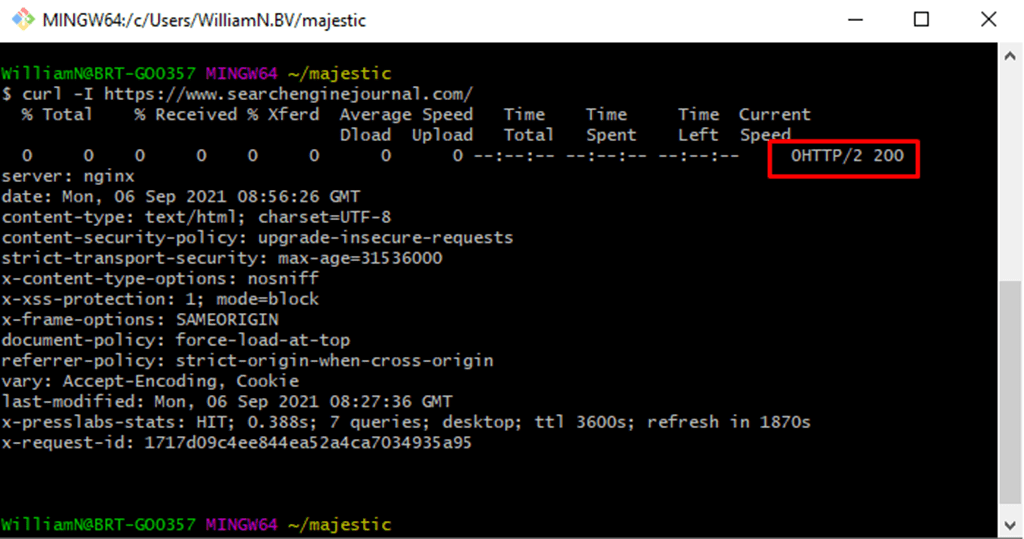
Curl -I is a great way to verify status codes when a site is using a service worker, which often conflict with browser extensions.
It’s also excellent for verifying if a CDN’s bot mitigation is causing issues when you’re attempting to crawl a site. If it is, you’ll almost certainly be served a 403 (Forbidden) status code.
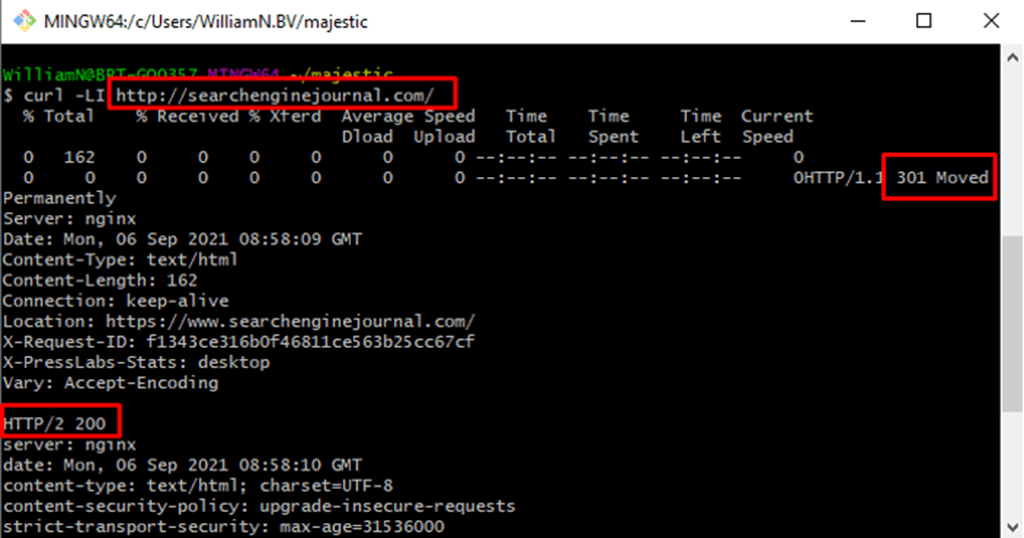
To fully replicate a redirect tracing extension, enable follow redirects with the -L option: curl -LI [url]
- Get the contents of a URL using a custom user agent: curl -A “User-Agent” [url]
- Use a different request method with a custom header: curl -X POST -H “Content-type: application/json” [url]
Test whether a URL supports a protocol (e.g. whether a site supports HTTP2, or a site on HTTP2 is backwards-compatible with HTTP/1.1):
- curl -I –http2 [url]
- curl -I –http1.1 [url]
Wget
Wget performs a similar function to curl but features recursive downloading, making it the better choice when transferring a larger number of files (or an entire website!). Wget is included in most distributions automatically, but if you’re using GIT Bash, you’ll have to install it.
- Download a file: wget [url]
- Download a list of URLs in a text file: wget -i [file-name].txt
- Download an entire website: wget -r [url]
- By default, wget will only download pages recursively up to five levels deep. Extend this using the -l option: wget -r -l [number] [url]
- Or, if you’re feeling brave, enable infinite recursion: wget -r -l inf [url]
- If you want to download a local copy of a site – with the links updated to reference the local versions – then use the mirror option instead: wget -m [url]
- You can also restrict the types of files downloaded. If, for instance, you only wanted JPGs: wget -r -A jpg,jpeg [url]
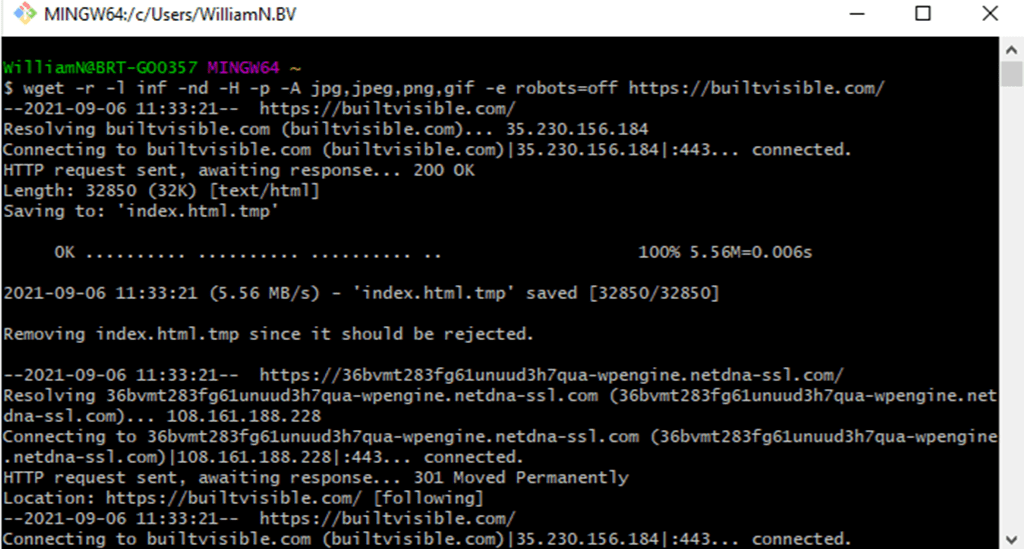
- Or wanted to download all images on a website to a single directory, including those on a CDN, ignoring the robots.txt: wget -r -l inf -nd -H -p -A jpg,jpeg,png,gif -e robots=off [url]
Cleaning your output
To finish things off, a bit of housekeeping is on order.
If you’ve been following along and trying out commands, the chances are that your command line is starting to look messy. Thankfully, clearing – or quitting! – the interface is very simple.
- Clear the output of the command line: clear
- Exit the command line: exit
Taking things further
The above commands will have given you a good idea of the types of tasks you can accomplish using the command line, but this is really just a jumping-off point. With the ability to chain commands together, the possibilities are virtually endless – especially if you start exploring Bash scripting. To provide a few more ideas, you could:
- Automate Screaming Frog.
- Run web performance tests like Lighthouse in bulk.
- Perform en-masse image compression.
- Or publish a website using a JAMstack architecture.
Lastly, a degree of competency using the command line is essential when you begin coding. It’s a skill you’ll use constantly when navigating to, and running, your scripts. And with the popularity of Git repositories such as GitHub and Gitlab, I hope you’ll use it to contribute to projects and share your work with the world as well!
More Resources:
- A Guide to Popular PHP Frameworks for Beginners
- How to Improve Site Performance: 4 Speed Audit Quick Wins
- Advanced Technical SEO: A Complete Guide
Originally written for and published on the Search Engine Journal website.