Fundamentals: What We Know About GoogleBot and JavaScript
Google continues to make progress with their JavaScript indexing capabilities. Their web rendering service (WRS) is based on Chrome 41, which albeit a slightly older version of Chrome still behaves as a typical browser. Despite this, WRS does not retain state with each page load, clearing cookies and session data.
Through our own work in JS framework content development and some useful input from elsewhere we’re able to derive some useful facts about Google’s approach to JS and subsequently, insight into our technical SEO strategy:
Googlebot follows JavaScript redirects
In fact, Google treats them very much like a 301 from an indexing standpoint. Indexed URLs are replaced in the index by the redirected-to URL.
Much of what we learn comes from test projects we build in libraries such as React, but our experience comes from working with development teams on projects such as Red Bull.
Googlebot will follow links in JavaScript.
This includes JavaScript links coded with:
- Functions outside of the href Attribute-Value Pair (AVP) but within the a tag (“onClick”)
- Functions inside the href AVP (“javascript:window.location“)
- Functions outside of the “a” but called within the href AVP (“javascript:openlink()”)
Despite Google’s apparent improvements at crawling JS, they still require everything that manipulates a URL to be a link, essentially in an “a” container. In tests on pagination, we’d supported paging using events on spans, which moved forward and backward through the list of events, and a pagination list at the bottom of the app, using similar logic.
Interestingly, though, whilst Google can render JS reasonably well, it’s not yet trying to understand the context of that JS.
When we checked the server logs, we were able to see that they weren’t attempting to poke the pagination list, despite that it looks like pagination (albeit at that point without links). What we’ve been able to infer from further testing of this is that while Google understands context from layout and common elements, it doesn’t yet try and fire JS events to see what will happen.
Anything that manipulates URLs needs to still be dealt with using links, with the link in the anchor of that link.
Anything else risks Google not assigning weight, or not crawling to the right page at all. this is potentially a situation that an inexperienced SEO might not spot and it’s a lot more common a solution for a JS developer than an SEO might prefer.
Googlebot has a maximum wait time for JS rendering that you should not ignore.
In our tests we found that content that took longer than 4 seconds to render or content that would not render until an event was fired by a link not in an “a” container, did not get indexed by Google.
Deprecating the Ajax Crawl Directive
The AJAX crawling scheme introduced by Google as a way of making JavaScript driven web pages accessible for indexing is finally being deprecated in Q2 of 2018. This should cause few surprises given the first announcement was made back in 2015, but with a further 3 years of ‘planning’ it’s now coming to an end.
It’s important to bear in mind of course that Google isn’t the only search engine, and others still rely heavily on this pre-rendered view to crawl and extract what is relevant. By that I mean even social networks such as Twitter and Facebook rely on plain HTML to utilise relevant meta tags.
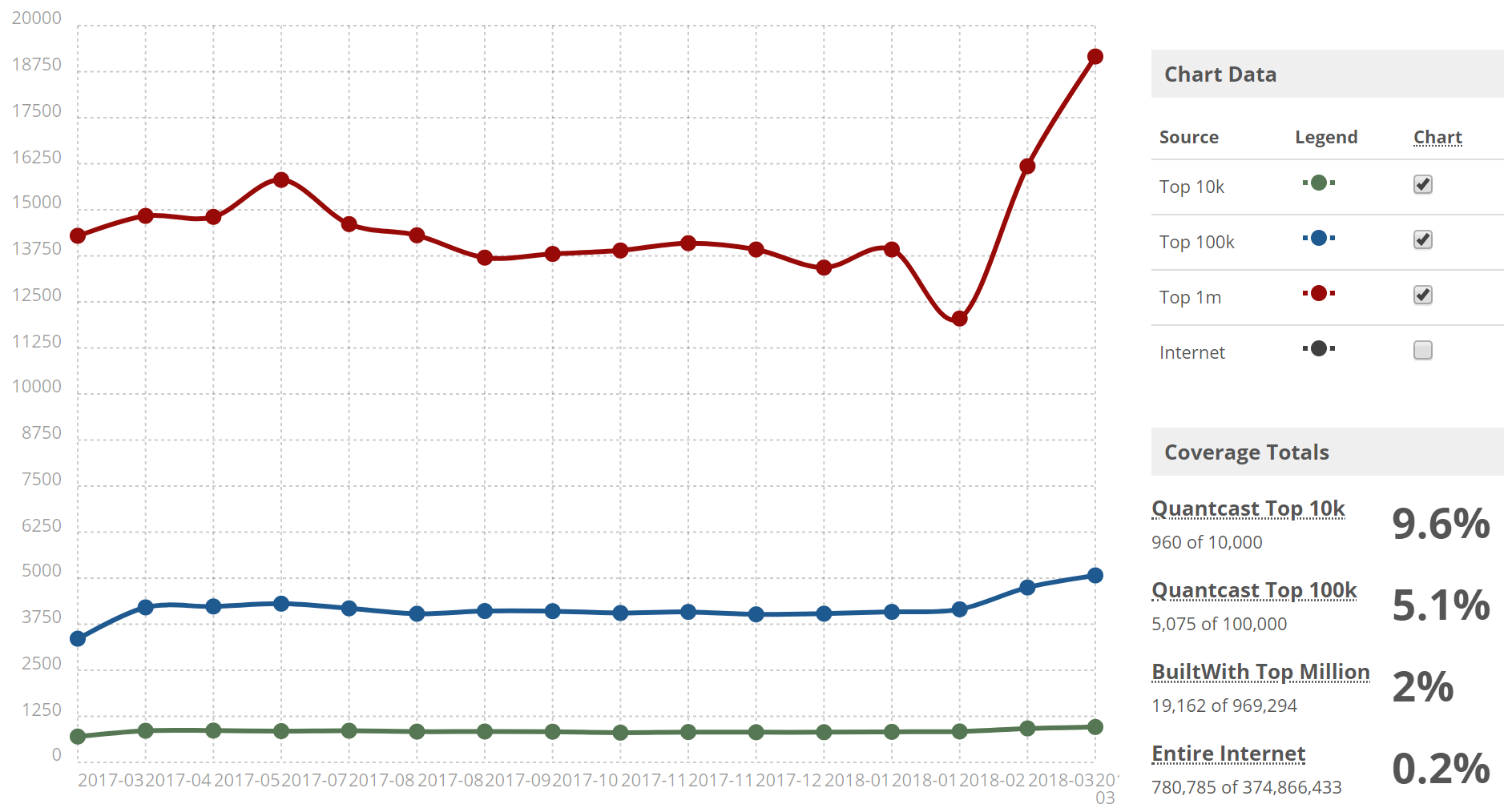
An experiment by Bartosz Góralewicz found that only Google and Ask could properly index JavaScript generated content:
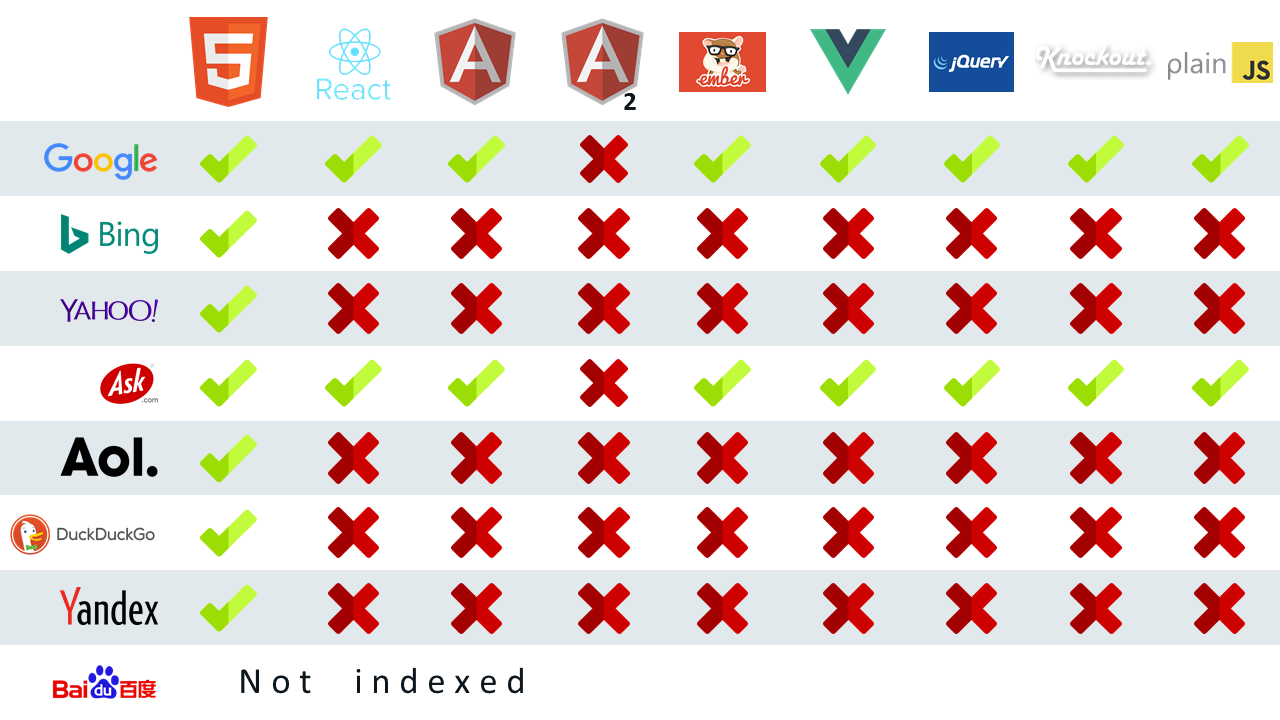
Google can render and crawl JS sites. This, however is no guarantee that the outcome will be an SEO friendly, perfectly optimised site. Technical SEO expertise is needed, especially during testing. This will ensure that you have an SEO friendly site architecture, targeting the right keywords. A site that continues to rank despite the changes made in Google’s crawl.
In my opinion, it’s better to retain tighter control of what’s being rendered by serving Google a pre-rendered, flat version of your site. This way, all the classic rules of SEO apply and it should be easier to detect and diagnose potential SEO issues during testing.
Dynamic Rendering
If you’re currently pre-rendering pages to Google then you’re probably using something like Phantom JS or a service such as prerender.io that takes care of that for you. Both scenarios result in a static cached version of a page being served, effectively simulating server-side rendering just without the code to directly influence the server platform.
The newer versions of Angular (4 with universal) and ReactJS have server side rendering capability available, which also brings about a number of additional benefits. Switching up to the latest version would be the ideal solution for combatting the deprecated AJAX crawling scheme, which ensures that all search engines, social networks etc can consistently and accurately read the content on your site.
If that’s not possible however, pre-rendering is still a viable solution if it’s deployed at the request URL directly and only to search engine user agents or services that require access to the static HTML. That way they still get the benefits of the simulated SSR (server side render) and we get assurances of pages and content being consistently crawled and indexed.
Is it cloaking? No – in the exact same way as when you once generated a static snapshot of your page and delivered it to search engines either via the #! or Meta fragment tag, that page still needs to be identical to the JS generated page to avoid ‘cloaking’. This method is exactly the same but in this scenario we’re detecting search engines and then serving the same static page and experience just at the request URL directly.
There’s a thread on this very topic in the JavaScript Google group that’s worth checking out!
Even John Mueller pitched in with:
“We realize this isn’t trivial to do. If you can only provide your content through a “DOM-level equivalent” prerendered version served through dynamic serving to the appropriate clients, then that works for us too.”
In summary, if you can’t do either of those and you care about your SEO do not build a PWA!
Principles for Making JavaScript Frameworks Search Friendly
Server Side Rendering
As we touched on in the previous section, the first thing that I’d always set up is server-side rendering. In Vue.js that means using Nuxt.js. In React, that means ReactDOMServer.renderToString(), and then ReactDOM.hydrate() on the client. Angular 4 has Universal. But whatever the tech you’re using, it’s about time you made sure you were using a universal approach, rather than pre-rendering, if that’s what you’re currently doing.
It makes it easy to deliver what *should* be rendered on the client to Googlebot etc, and to keep parity between them, as if it’s what’s going to be rendered on the client, it’s what’s rendered server-side too. However, there is a gotcha that can occur, and it’s…
Hot-Swapping Elements
Some common examples where I see this being a problem include:
Image Galleries
There’s a temptation with image galleries to improve performance by having a number of image elements, and change the images being rendered by swapping in and out different src attributes. That’s great, but if you’re reliant on image search traffic then search engines will only see the images you’re initially rendering, rather than all of them.
If you need to get every image rendered, you’ll have to use an architecture for your image galleries more akin to those used by things like jQuery (controlling what’s shown using CSS).
Tabbed Content
Similarly, there’s a tendency to have a single block element which swaps content in and out, depending on the tab required, rather than using CSS. Again, that’s often a useful thing, but it does mean that any content in anything other than the first tab won’t get indexed. Not necessarily an issue, if it’s highly repetitive or content that’s there for legal/UX reasons, but isn’t likely to be needed more than once (delivery/returns policies for example). However, if it’s required for indexation, again you’re back to using swapped classes on elements and CSS to show/hide things.
Paginated Content
This is a slightly different sort of case, but the same thing applies – anything that’s not the first set of data loaded won’t get indexed, so if you’re displaying blog entries for example, only the first list would get linked to, whilst the rest would disappear. As such, the pagination should work updating the URL, and those URLs should be properly resolvable too.
Metadata & Routing
Metadata updates can be a nightmare; more-so with React, which has no built-in routing solution. React Router makes the situation worse, by forcing rendering to be done inside of it, creating some weird architectural issues around changing content in the head. Pete Wailes built a script as a workaround to this called Vivaldi, but any solution is fine as long as it allows for proper creation of metadata both on initial loads and navigation between pages, to ensure consistency between what Google sees and what users experience as they move between areas.
Whatever technology you end up using, make sure you keep parity across navigation in at least these head elements:
- Title
- Meta description
- Rel canonical
- Hreflang rel alternate
Links For *All* Navigation/Accessible URLs
Events may be what you’re using to actually control things behind the scenes and change what’s displayed to a user, but if you want it to be indexable, for now at least the content needs to live on a URL where it can be indexed, and that means you should be using links to navigate between areas. Sure, you can intercept the request with preventDefault and run your own code to swap things around, but you still need everything to work as if JS wasn’t there.
Which brings us to the final concept…
Pretend JS is Turned Off
Netflix are one of the biggest names in the React sphere, and a lot of their learnings can be applied to any JS SPA, not just React-based ones. And the biggest of these is that you should only be using client-side JS libraries where it’s actually required. I’d do a big write-up here, but honestly Jake Archibald’s is so good you should just go read his.
As much as possible, use client-side rendering as little as possible, and just serve from the server, importing the library where the functionality on the page requires it. You’ll not only be ensuring you get the benefits of good, crawlable content, but also deliver a faster and more responsive experience to your users, and have fewer issues with your code.
Testing Your Implementation
Crawling
Within the last year a multitude of tools have developed support for JS crawling and even rendering capabilities which allow SEOs to quickly compare the raw HTML with the rendered HTML to spot potential issues.
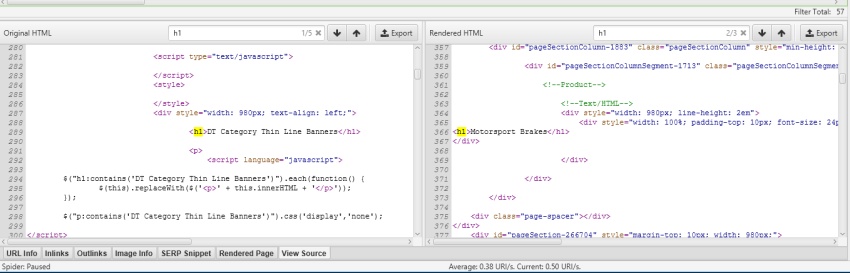
Compare raw & rendered HTML with Screaming Frog
Once you’ve managed to test the pre-rendering service with a crawler, you’ll immediately be able to switch to “classic SEO” mode; in that you’re looking out for the exact same types of problem you’d encounter on a standard / more typical HTML website.
Here are a few of our favourites:
Screaming Frog – https://www.screamingfrog.co.uk/crawl-javascript-seo/
DeepCrawl – https://www.deepcrawl.com/help/guides/javascript-rendering/
Sitebulb – https://sitebulb.com/resources/guides/how-to-crawl-javascript-websites/
Botify – https://www.botify.com/blog/crawling-javascript-for-technical-seo-audits/
Google Tools
Googles Fetch & Render also runs off Chrome 41, and so you can either download and test yourself using the Chrome developer tools or run the request through Search Console. Having the capability to interact with what Google actually see’s is invaluable insight for testing whether specific components can be rendered.
Another valuable asset in the Google toolbox is Lighthouse, an open source tool that provides automated auditing of any web page in terms of performance and accessibility. A part of this process focuses specifically on optimisation of PWAs, which as an added bonus can also be run directly from command line as a Node module for testing during development.
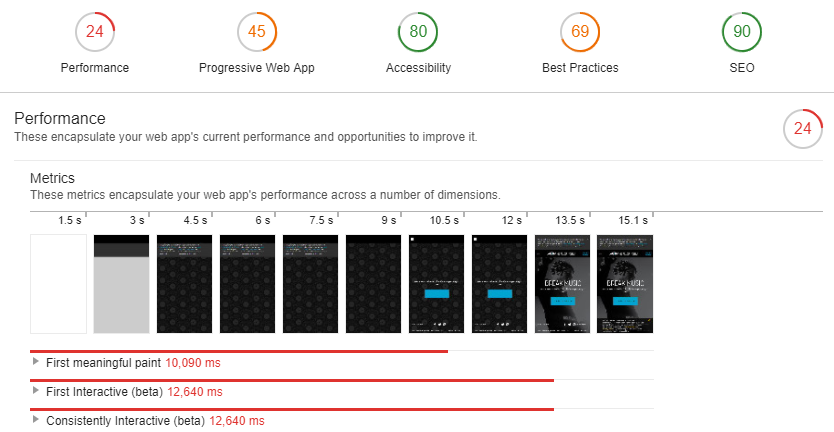
Disable JavaScript
Particularly useful when working with server side rendering, simply disabling JavaScript in the browser (I prefer to do this via the Chrome web developer toolbar but can also be disabled in Chrome directly) can be a quick way to troubleshoot components that are less likely to be indexed by search engines.
Taking this another step further, as much as we want to allow search engines to crawl & render JavaScript content, it doesn’t mean that they need to read every aspect of JS being fired. This is particularly true if it leads to irrelevant URLs that wouldn’t have otherwise been requested being crawled. Remember this still absorbs crawl budget, so we’re burning unnecessary resource by allowing access to URLs that do not affect the rendering of the page.
Within Chrome developer tools, switch to the ‘Network’ tab, identify the resource in question, right click and select ‘Block request URL’. Reload the page and see what happens to the rendered page with the corresponding resource disabled. In some cases the resource may not have been used altogether, perhaps it’s legacy and simply been forgotten in which case removing it will also have a performance benefit.
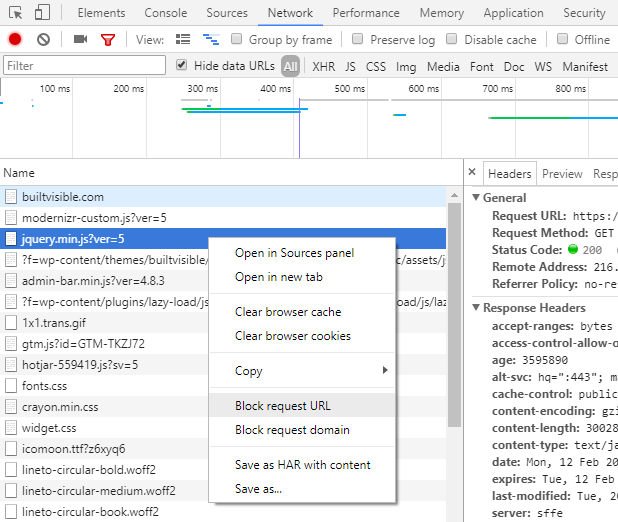
Combining this approach with log file analysis will provide us with clearer insight into what resources search engines are burning unnecessary crawl budget on.
Links
Ok so this one isn’t strictly for auditing your website, but as more sites begin to utilise these technologies more links will inevitably find their way inside JS components. Understanding which of those links can be rendered and thus pass equity is extremely important for building your organic search strategy.
Fortunately in Sept 2017 Ahrefs released an update for their crawlers which means they’re now able to execute and render JavaScript. This at least combined with your data from Search Console can plug some more gaps.
