Requirements
To run my examples yourself, you’ll need to have a command line environment configured on your OS and be comfortable working with Node.js. We’ll be querying a couple of different APIs using the request http client available via npm.
I’ve deliberately kept the demos fairly high-level so you can adapt them to suit your requirements. The principles should be easy to transfer to other cloud providers and to different languages (including PHP, Java, Ruby, etc) if Node.js isn’t your thing.
Let’s get started!
1. Language Detection
Let’s say you’re debugging a large-scale hreflang implementation and need to identify whether the language codes in the existing declarations are an accurate reflection of page text. You scrape the declarations from the page <head> or the sitemap, along with a snippet of relevant text using an XPath expression, and export the resulting data into a spreadsheet or database.
This is where traditional automation techniques begin to falter; if we assume each text extract is unique, then accurately determining their language would be extremely laborious. If you instead pull a portion of templated copy which you believe is consistent between pages of a certain language, you risk not getting an accurate reflection of the actual content on each page.
Enter the Text Analytics API, part of the Microsoft Azure Cognitive Services platform. Similar services are available from the likes of Google, Amazon, IBM, and others. Head over to Azure to create your free account, then spin up an instance of Cognitive Services and grab your API key and endpoint (under ‘Resource Management’).
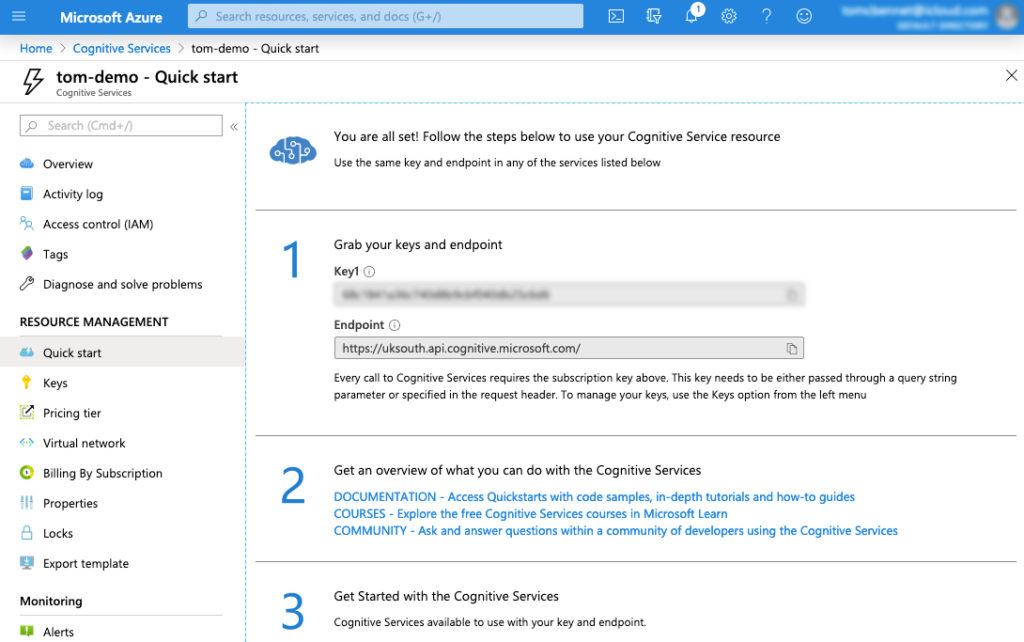
First you’ll need to install the request npm package. Create a new working directory and run the following command:
npm install request
Next, save the language extracts you’d like to test as a JSON file called language-extracts.json:
{ "documents": [
{
"id": "1",
"text": "Был холодный ясный апрельский день, и часы пробили тринадцать."
},{
"id": "2",
"text": "Era un día luminoso y frío de abril y los relojes daban las trece."
},{
"id": "3",
"text": "C'était une journée d'avril froide et claire. Les horloges sonnaient treize heures."
}
]}
In the same directory, save the following script as language.js:
'use strict';
const request = require ('request');
// User settings
const subscriptionKey = 'YOUR_AZURE_API_KEY';
const endpoint = 'YOUR_AZURE_ENDPOINT';
const documents = require('./language-samples.json');
const uriBase = endpoint + 'text/analytics/v3.0-preview.1/languages';
const options = {
uri: uriBase,
body: JSON.stringify(documents),
headers: {
'Content-Type': 'text/json',
'Ocp-Apim-Subscription-Key' : subscriptionKey
}
};
request.post(options, (error, response, body) => {
if (error) {
console.log('Error: ', error);
return;
}
let jsonResponse = JSON.stringify(JSON.parse(body), null, ' ');
console.log(jsonResponse);
});
Let’s break down the three settings at the top:
- Subscription Key: Either of your two API keys for Azure Cognitive Services.
- Endpoint: The URL for your Azure instance to which you’ll make calls.
- Samples: The path of the JSON file containing samples you’d like to test. Here I’ve assumed it’s in the same directory as
language.js.
In a production environment you should obviously be using environment variables for sensitive information like API keys, but for the sake of keeping this demo simple I have instead hard-coded them into the script.
Once you’ve entered your API key and endpoint and saved the script, run the following command:
node language.js
You’ll receive a response something like this:
{
"documents": [
{
"id": "1",
"detectedLanguages": [{
"name": "Russian","iso6391Name": "ru","score": 1
}]
},
{
"id": "2",
"detectedLanguages": [{
"name": "Spanish","iso6391Name": "es","score": 1
}]
},
{
"id": "3",
"detectedLanguages": [{
"name": "French","iso6391Name": "fr","score": 1
}]
}
],
"errors": [],
"modelVersion": "2019-10-01"
}
What I love about this solution is its near infinite scalability. Note that I’m not just talking about price, either (although the free tier on Azure is generous). You could use this API to test the accuracy of hreflang declarations as part of your CI/CD build process, validate the language of text entered into the CMS by your content editors, or check the suitability of user generated content.
2. Image alt text
I’ve used alt text as an example here, but this could be any task which requires a human understanding of the content of an image. You might be tagging photos for accurate categorisation, checking uploaded photos for adult content, or working on the accessibility of your site for screen readers.
Whatever challenge you’re facing, image recognition is a classic AI problem. While you might be able to distinguish between a bear and a dog (or a turtle and a gun) without breaking a sweat, think about how much pre-existing knowledge and understanding is required for your brain to complete this task.
Consider the image below. Processing raw pixels into a conceptual understanding of a bear, a river, fish, water, grass, nature, and the outdoors, not to mention assembling these concepts into a coherent description, is a huge challenge which spans both computer vision and natural language processing.

Indeed, computer vision is such a monumental challenge that Google is currently running a competition to see who can create a model capable of accurately captioning images at scale. Note that specialised models – those which are trained to carry out a specific task like identifying explicit content or recognising faces – tend to be far more precise than the kind of general-purpose models we’ll be testing here.
For this task, we’ll once again be using the Microsoft Azure Cognitive Services APIs, in this case Computer Vision via Node.js. I’ve assumed you ran through the previous example, and so have a working directory with the request package installed.
Save the following script as image.js in your directory:
'use strict';
const request = require ('request');
// User settings
const subscriptionKey = 'YOUR_AZURE_API_KEY';
const endpoint = 'YOUR_AZURE_ENDPOINT';
const imageUrl =
'https://upload.wikimedia.org/wikipedia/commons/4/46/Bear_Alaska_%283%29.jpg';
const uriBase = endpoint + 'vision/v2.1/describe';
const options = {
uri: uriBase,
qs: {'language': 'en'},
body: '{"url": ' + '"' + imageUrl + '"}',
headers: {
'Content-Type': 'application/json',
'Ocp-Apim-Subscription-Key' : subscriptionKey
}
};
request.post(options, (error, response, body) => {
if (error) {
console.log('Error: ', error);
return;
}
let jsonResponse = JSON.stringify(JSON.parse(body), null, ' ');
console.log(jsonResponse);
});
You should be able to use the same cognitive services subscription key and endpoint as before. All you’ll need to do is add these to your script along with the URL of an image that you’d like to process, then run:
node image.js
You’ll receive a response that looks like this:
{
"description": {
"tags": [
"water","outdoor","bear","brown","animal","mammal","river","grass","playing","fish","lake","standing"
],
"captions": [{
"text": "a brown bear standing next to a body of water",
"confidence": 0.9316322692983895
}]
},
"requestId": "fc41270e-aa6f-46b1-9165-079a601abae2",
"metadata": {
"width": 2872,"height": 2468,"format": "Jpeg"
}
}
That’s right, a brown bear standing next to a body of water, with 93% confidence. Well done Skynet.
3. Page meta descriptions
For our final example, we’ll be looking at page meta descriptions. Any SEO will tell you the importance of writing a good and unique meta description to encourage click-through from the SERPs.
But for large ecommerce websites this can quickly become a problem: with tens or even hundreds of thousands of pages, how can you generate these descriptions in a scalable way? Templating descriptions by inserting keywords into boilerplate copy will typically result in dull repetitive text, while using a predetermined portion of the page copy (the first 160 characters, say) won’t necessarily describe the overall meaning of the content.
Using AI to aid in writing these descriptions can be a great stop-gap until human copywriting resource is available. Much like our language detection scenario earlier, this is a natural language processing (NLP) task. This time, however, our model has to output human-readable text based on the snippet supplied, and this is a significant challenge.
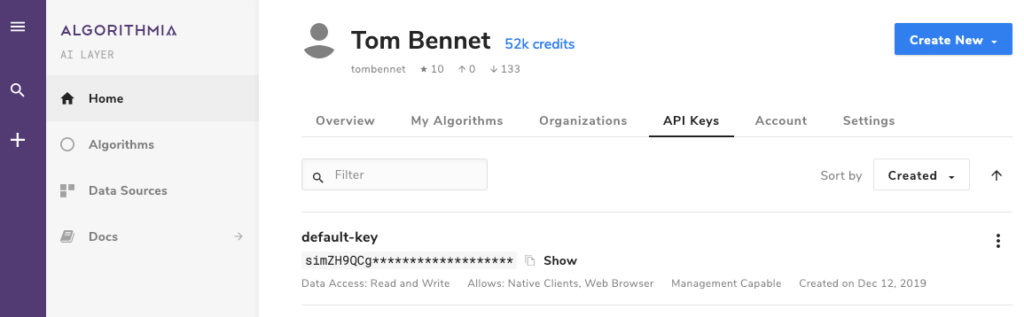
We’re going to take a break from Azure and instead use Algorithmia for this task. Head to the website and create a free account, then generate an API key.
I’ve picked a 1000-character book synopsis to use for our example. We’ll aim to summarise this in two sentences.
"Winner of the 30th anniversary Arthur C Clarke Award for Best Novel. Adrian Tchaikovksy’s critically acclaimed, stand-alone novel Children of Time is the epic story of humanity’s battle for survival on a terraformed planet. Who will inherit this new Earth? The last remnants of the human race left a dying Earth, desperate to find a new home among the stars. Following in the footsteps of their ancestors, they discover the greatest treasure of the past age - a world terraformed and prepared for human life. But all is not right in this new Eden. In the long years since the planet was abandoned, the work of its architects has borne disastrous fruit. The planet is not waiting for them, pristine and unoccupied. New masters have turned it from a refuge into mankind’s worst nightmare. Now two civilizations are on a collision course, both testing the boundaries of what they will do to survive. As the fate of humanity hangs in the balance, who are the true heirs of this new Earth?"
As before, you’ll need the request npm package installed in your working directory. Save the following script as summarize.js, copy and pasting your chosen text extract into the data constant as a string. The sentence constant accepts an integer which will tell the service how many sentences to return as a summary.
'use strict';
const request = require ('request');
// User settings
const subscriptionKey = 'YOUR_ALGORITHMIA_API_KEY';
const data = 'TEXT_STRING_TO_SUMMARIZE';
const sentences = 2;
const options = {
uri: 'https://api.algorithmia.com/v1/algo/nlp/Summarizer/0.1.8?timeout=300',
body: JSON.stringify([data,sentences]),
headers: {
'Content-Type': 'application/json',
'Authorization': 'Simple ' + subscriptionKey
}
};
request.post(options, (error, response, body) => {
if (error) {
console.log('Error: ', error);
return;
}
let jsonResponse = JSON.stringify(JSON.parse(body), null, ' ');
console.log(jsonResponse);
});
Run node summarize.js and you’ll get something like this:
{
"result": "Adrian Tchaikovksy's critically acclaimed, stand-alone novel Children of Time is the epic story of humanity's battle for survival on a terraformed planet. Who will inherit this new Earth.",
"metadata": {
"content_type": "text",
"duration": 0.044619293
}
}
Wrapping up
I should stress that these examples are absolutely not production-ready code! They’re intended as proof-of-concept demonstrations to get you excited about the potential of AI and machine learning to enable you to work more efficiently.
By automating SEO tasks which would once have required monotonous work and outsourced jobs, agencies are better able to fulfill their remit of providing tangible return on the spend which clients have invested. What’s more, an API-based approach to automation means that machine learning solutions can be integrated into deployment test pipelines, allowing content to be validated quickly, reliably, and at scale.
I hope this article has sparked some inspiration. Let me know how you’re using machine learning and AI to boost your SEO efforts in the comments or on LinkedIn.
Thanks for reading!
We love using creativity to solve technical challenges for our clients. Contact us to build a brief around solving problems for your business.
Thanks to Oli Mason for feedback on an early draft of this article.

Yılmaz Saraç
This article is a new window for an SEO expert. Thank you
SEO Agency
Hi Tom!
Your approach to automation with API is a good concept to make SEO expert jobs easy. Thanks for the ideas and this has definitely inspired us.